
-
News Message
深度强化学习论文合集
- by wittx 2023-02-05
一. DQN
1. Playing Atari with Deep Reinforcement Learning,V. Mnih et al., NIPS Workshop, 2013.
2. Human-level control through deep reinforcement learning, V. Mnih et al., Nature, 2015.
二. DQN的各种改进版本(侧重于算法上的改进)
1. Dueling Network Architectures for Deep Reinforcement Learning. Z. Wang et al., arXiv, 2015.
2. Prioritized Experience Replay, T. Schaul et al., ICLR, 2016.
3. Deep Reinforcement Learning with Double Q-learning, H. van Hasselt et al., arXiv, 2015.
5. Dynamic Frame skip Deep Q Network, A. S. Lakshminarayanan et al., IJCAI Deep RL Workshop, 2016.6. Deep Exploration via Bootstrapped DQN, I. Osband et al., arXiv, 2016.
8. Learning functions across many orders of magnitudes,H Van Hasselt,A Guez,M Hessel,D Silver
9. Massively Parallel Methods for Deep Reinforcement Learning, A. Nair et al., ICML Workshop, 2015.
10. State of the Art Control of Atari Games using shallow reinforcement learning
11. Learning to Play in a Day: Faster Deep Reinforcement Learning by Optimality Tightening(11.13更新)
12. Deep Reinforcement Learning with Averaged Target DQN(11.14更新)
三. DQN的各种改进版本(侧重于模型的改进)
1. Deep Recurrent Q-Learning for Partially Observable MDPs, M. Hausknecht and P. Stone, arXiv, 2015.
2. Deep Attention Recurrent Q-Network
3. Control of Memory, Active Perception, and Action in Minecraft, J. Oh et al., ICML, 2016.
4. Progressive Neural Networks
5. Language Understanding for Text-based Games Using Deep Reinforcement Learning
6. Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks
7. Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation
8. Recurrent Reinforcement Learning: A Hybrid Approach
四. 基于策略梯度的深度强化学习
深度策略梯度:
1. End-to-End Training of Deep Visuomotor Policies
2. Learning Deep Control Policies for Autonomous Aerial Vehicles with MPC-Guided Policy Search
3. Trust Region Policy Optimization
深度行动者评论家算法:
1. Deterministic Policy Gradient Algorithms
2. Continuous control with deep reinforcement learning
3. High-Dimensional Continuous Control Using Using Generalized Advantage Estimation
4. Compatible Value Gradients for Reinforcement Learning of Continuous Deep Policies
5. Deep Reinforcement Learning in Parameterized Action Space
6. Memory-based control with recurrent neural networks
7. Terrain-adaptive locomotion skills using deep reinforcement learning
8. Compatible Value Gradients for Reinforcement Learning of Continuous Deep Policies
9. SAMPLE EFFICIENT ACTOR-CRITIC WITH EXPERIENCE REPLAY(11.13更新)
搜索与监督:
1. End-to-End Training of Deep Visuomotor Policies
2. Interactive Control of Diverse Complex Characters with Neural Networks
连续动作空间下探索改进:
1. Curiosity-driven Exploration in DRL via Bayesian Neuarl Networks
结合策略梯度和Q学习:
1. Q-PROP: SAMPLE-EFFICIENT POLICY GRADIENT WITH AN OFF-POLICY CRITIC(11.13更新)
2. PGQ: COMBINING POLICY GRADIENT AND Q-LEARNING(11.13更新)
其它策略梯度文章:
1. Gradient Estimation Using Stochastic Computation Graphs
2. Continuous Deep Q-Learning with Model-based Acceleration
3. Benchmarking Deep Reinforcement Learning for Continuous Control
4. Learning Continuous Control Policies by Stochastic Value Gradients
五. 分层DRL
1. Deep Successor Reinforcement Learning
2. Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation
3. Hierarchical Reinforcement Learning using Spatio-Temporal Abstractions and Deep Neural Networks
六. DRL中的多任务和迁移学习
1. ADAAPT: A Deep Architecture for Adaptive Policy Transfer from Multiple Sources2. A Deep Hierarchical Approach to Lifelong Learning in Minecraft
3. Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning
5. Progressive Neural Networks
6. Universal Value Function Approximators
7. Multi-task learning with deep model based reinforcement learning(11.14更新)
8. Modular Multitask Reinforcement Learning with Policy Sketches (11.14更新)
七. 基于外部记忆模块的DRL模型
1. Control of Memory, Active Perception, and Action in Minecraft
2. Model-Free Episodic Control
八. DRL中探索与利用问题
1. Action-Conditional Video Prediction using Deep Networks in Atari Games
2. Curiosity-driven Exploration in Deep Reinforcement Learning via Bayesian Neural Networks
3. Deep Exploration via Bootstrapped DQN
4. Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation
5. Incentivizing Exploration In Reinforcement Learning With Deep Predictive Models
6. Unifying Count-Based Exploration and Intrinsic Motivation
7. #Exploration: A Study of Count-Based Exploration for Deep Reinforcemen Learning(11.14更新)
8. Surprise-Based Intrinsic Motivation for Deep Reinforcement Learning(11.14更新)
九. 多Agent的DRL
1. Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks
2. Multiagent Cooperation and Competition with Deep Reinforcement Learning
十. 逆向DRL
1. Guided Cost Learning: Deep Inverse Optimal Control via Policy Optimization
2. Maximum Entropy Deep Inverse Reinforcement Learning
3. Generalizing Skills with Semi-Supervised Reinforcement Learning(11.14更新)
十一. 探索+监督学习
1. Deep learning for real-time Atari game play using offline Monte-Carlo tree search planning
2. Better Computer Go Player with Neural Network and Long-term Prediction
3. Mastering the game of Go with deep neural networks and tree search, D. Silver et al., Nature, 2016.
十二. 异步DRL
1. Asynchronous Methods for Deep Reinforcement Learning
2. Reinforcement Learning through Asynchronous Advantage Actor-Critic on a GPU(11.14更新)
十三:适用于难度较大的游戏场景
2. Strategic Attentive Writer for Learning Macro-Actions
3. Unifying Count-Based Exploration and Intrinsic Motivation
十四:单个网络玩多个游戏
2. Universal Value Function Approximators
3. Learning values across many orders of magnitude
十五:德州poker
1. Deep Reinforcement Learning from Self-Play in Imperfect-Information Games
2. Fictitious Self-Play in Extensive-Form Games
3. Smooth UCT search in computer poker
十六:Doom游戏
1. ViZDoom: A Doom-based AI Research Platform for Visual Reinforcement Learning
2. Training Agent for First-Person Shooter Game with Actor-Critic Curriculum Learning
3. Playing FPS Games with Deep Reinforcement Learning
4. LEARNING TO ACT BY PREDICTING THE FUTURE(11.13更新)
5. Deep Reinforcement Learning From Raw Pixels in Doom(11.14更新)
十七:大规模动作空间
1. Deep Reinforcement Learning in Large Discrete Action Spaces
十八:参数化连续动作空间
1. Deep Reinforcement Learning in Parameterized Action Space
十九:Deep Model
1. Learning Visual Predictive Models of Physics for Playing Billiards
3. Learning Continuous Control Policies by Stochastic Value Gradients
4.Data-Efficient Learning of Feedback Policies from Image Pixels using Deep Dynamical Models
5. Action-Conditional Video Prediction using Deep Networks in Atari Games
6. Incentivizing Exploration In Reinforcement Learning With Deep Predictive Models
二十:DRL应用
机器人领域:
1. Trust Region Policy Optimization
2. Towards Vision-Based Deep Reinforcement Learning for Robotic Motion Control
3. Path Integral Guided Policy Search
4. Memory-based control with recurrent neural networks
6. Learning Deep Neural Network Policies with Continuous Memory States
7. High-Dimensional Continuous Control Using Generalized Advantage Estimation
8. Guided Cost Learning: Deep Inverse Optimal Control via Policy Optimization
9. End-to-End Training of Deep Visuomotor Policies
10. DeepMPC: Learning Deep Latent Features for Model Predictive Control
11. Deep Visual Foresight for Planning Robot Motion
12. Deep Reinforcement Learning for Robotic Manipulation
13. Continuous Deep Q-Learning with Model-based Acceleration
14. Collective Robot Reinforcement Learning with Distributed Asynchronous Guided Policy Search
15. Asynchronous Methods for Deep Reinforcement Learning
16. Learning Continuous Control Policies by Stochastic Value Gradients
机器翻译:
1. Simultaneous Machine Translation using Deep Reinforcement Learning
目标定位:
1. Active Object Localization with Deep Reinforcement Learning
目标驱动的视觉导航:
1. Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning
自动调控参数:
1. Using Deep Q-Learning to Control Optimization Hyperparameters
人机对话:
1. Deep Reinforcement Learning for Dialogue Generation
2. SimpleDS: A Simple Deep Reinforcement Learning Dialogue System
3. Strategic Dialogue Management via Deep Reinforcement Learning
视频预测:
1. Action-Conditional Video Prediction using Deep Networks in Atari Games
文本到语音:
1. WaveNet: A Generative Model for Raw Audio
文本生成:
1. Generating Text with Deep Reinforcement Learning
文本游戏:
1. Language Understanding for Text-based Games Using Deep Reinforcement Learning
无线电操控和信号监控:
1. Deep Reinforcement Learning Radio Control and Signal Detection with KeRLym, a Gym RL Agent
DRL来学习做物理实验:
1. LEARNING TO PERFORM PHYSICS EXPERIMENTS VIA DEEP REINFORCEMENT LEARNING(11.13更新)
DRL加速收敛:
1. Deep Reinforcement Learning for Accelerating the Convergence Rate(11.14更新)
利用DRL来设计神经网络:
1. Designing Neural Network Architectures using Reinforcement Learning(11.14更新)
2. Tuning Recurrent Neural Networks with Reinforcement Learning(11.14更新)
3. Neural Architecture Search with Reinforcement Learning(11.14更新)
控制信号灯:
1. Using a Deep Reinforcement Learning Agent for Traffic Signal Control(11.14更新)
二十一:其它方向
避免危险状态:1. Combating Deep Reinforcement Learning’s Sisyphean Curse with Intrinsic Fear (11.14更新)
DRL中On-Policy vs. Off-Policy 比较:
1. On-Policy vs. Off-Policy Updates for Deep Reinforcement Learning(11.14更新)
最近放出来许多2017ICLR的投稿,有不少是关于DRL的,我目前读过里面比较有意思的有:1. Learning to Play in a Day: Faster Deep Reinforcement Learning by Optimality Tightening,2. PGQ: Combining policy gradient and Q-learning,3. Q-Prop: Sample-Efficient Policy Gradient with An Off-Policy Critic,4. Sample Efficient Actor-Critic with Experience Replay,5. Learning to Act by Predicting the Future。1,2,4都应用在了Atari Games上,3,4 应用在Robotics continuous control上,5 在 Doom Full Deathmatch track 中赢得了第一名。1. 论文名称:Efficient Deep Reinforcement Learning via Adaptive Policy Transfer
论文链接:https://www.aminer.cn/pub/5ef96b048806af6ef2772111/efficient-deep-reinforcement-learning-via-adaptive-policy-transfer?conf=ijcai2020
作者:Tianpei Yang、Jianye Hao、Zhaopeng Meng、Zongzhang Zhang、Yujing Hu、Yingfeng Chen、Changjie Fan、Weixun Wang、Wulong Liu、Zhaodong Wang、Jiajie Peng
简介:· The authors propose a Policy Transfer Framework (PTF) which can efficiently select the optimal source policy and exploit the useful information to facilitate the target task learning.· PTF efficiently avoids negative transfer through terminating the exploitation of current source policy and selects another one adaptively.· PTF can be combined with existing deep DRL methods.· Experimental results show PTF efficiently accelerates the learning process of existing state-ofthe-art DRL methods and outperforms previous policy reuse approaches.
2. 论文名称:KoGuN: Accelerating Deep Reinforcement Learning via Integrating Human Suboptimal Knowledge
论文链接:https://www.aminer.cn/pub/5e4d083f3a55ac8cfd770c23/kogun-accelerating-deep-reinforcement-learning-via-integrating-human-suboptimal-knowledge?conf=ijcai2020
作者:Zhang Peng、Jianye Hao、Wang Weixun、Tang Hongyao、Ma Yi、Duan Yihai、Zheng Yan
简介:· The authors propose a novel policy network framework called KoGuN to leverage human knowledge to accelerate the learning process of RL agents.· The authors firstly evaluate the algorithm on four tasks in Section 4.1 : CartP ole [Barto and Sutton, 1982], LunarLander and LunarLanderContinuous in OpenAI Gym [Brockman et al, 2016] and F lappyBird in PLE [Tasfi, 2016].· The authors show the effectiveness and robustness of KoGuN in sparse reward setting in Section 4.2.· For PPO without KoGuN, the authors use a neural network with two full-connected hidden layers as policy approximator.· For KoGuN with normal network (KoGuN-concat) as refine module, the authors use a neural network with two full-connected hidden layers for the refine module.· For KoGuN with hypernetworks (KoGuN-hyper), the authors use hypernetworks to generate a refine module with one hidden layer.· All hidden layers described above have 32 units. w1 is set to 0.7 at beginning and decays to 0.1 in the end of training phase
3. 论文名称:Generating Behavior-Diverse Game AIs with Evolutionary Multi-Objective Deep Reinforcement Learning
论文链接:https://www.aminer.cn/pub/5ef96b048806af6ef277219d/generating-behavior-diverse-game-ais-with-evolutionary-multi-objective-deep-reinforcement-learning?conf=ijcai2020
作者:Ruimin Shen、Yan Zheng、Jianye Hao、Zhaopeng Meng、Yingfeng Chen、Changjie Fan、Yang Liu
简介:· This paper proposes EMOGI, aiming to efficiently generate behavior-diverse Game AIs by leveraging EA, PMOO and DRL.· Empirical results show the effectiveness of EMOGI in creating diverse and complex behaviors.· To deploy AIs in commercial games, the robustness of the generated AIs is worth investigating as future work [Sun et al, 2020]
4. 论文名称:Solving Hard AI Planning Instances Using Curriculum-Driven Deep Reinforcement Learning
论文链接:https://www.aminer.cn/pub/5eda19d991e01187f5d6db49/solving-hard-ai-planning-instances-using-curriculum-driven-deep-reinforcement-learning?conf=ijcai2020一. DQN
1. Playing Atari with Deep Reinforcement Learning,V. Mnih et al., NIPS Workshop, 2013.
2. Human-level control through deep reinforcement learning, V. Mnih et al., Nature, 2015.
二. DQN的各种改进版本(侧重于算法上的改进)
1. Dueling Network Architectures for Deep Reinforcement Learning. Z. Wang et al., arXiv, 2015.
2. Prioritized Experience Replay, T. Schaul et al., ICLR, 2016.
3. Deep Reinforcement Learning with Double Q-learning, H. van Hasselt et al., arXiv, 2015.
5. Dynamic Frame skip Deep Q Network, A. S. Lakshminarayanan et al., IJCAI Deep RL Workshop, 2016.6. Deep Exploration via Bootstrapped DQN, I. Osband et al., arXiv, 2016.
8. Learning functions across many orders of magnitudes,H Van Hasselt,A Guez,M Hessel,D Silver
9. Massively Parallel Methods for Deep Reinforcement Learning, A. Nair et al., ICML Workshop, 2015.
10. State of the Art Control of Atari Games using shallow reinforcement learning
11. Learning to Play in a Day: Faster Deep Reinforcement Learning by Optimality Tightening(11.13更新)
12. Deep Reinforcement Learning with Averaged Target DQN(11.14更新)
三. DQN的各种改进版本(侧重于模型的改进)
1. Deep Recurrent Q-Learning for Partially Observable MDPs, M. Hausknecht and P. Stone, arXiv, 2015.
2. Deep Attention Recurrent Q-Network
3. Control of Memory, Active Perception, and Action in Minecraft, J. Oh et al., ICML, 2016.
4. Progressive Neural Networks
5. Language Understanding for Text-based Games Using Deep Reinforcement Learning
6. Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks
7. Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation
8. Recurrent Reinforcement Learning: A Hybrid Approach
四. 基于策略梯度的深度强化学习
深度策略梯度:
1. End-to-End Training of Deep Visuomotor Policies
2. Learning Deep Control Policies for Autonomous Aerial Vehicles with MPC-Guided Policy Search
3. Trust Region Policy Optimization
深度行动者评论家算法:
1. Deterministic Policy Gradient Algorithms
2. Continuous control with deep reinforcement learning
3. High-Dimensional Continuous Control Using Using Generalized Advantage Estimation
4. Compatible Value Gradients for Reinforcement Learning of Continuous Deep Policies
5. Deep Reinforcement Learning in Parameterized Action Space
6. Memory-based control with recurrent neural networks
7. Terrain-adaptive locomotion skills using deep reinforcement learning
8. Compatible Value Gradients for Reinforcement Learning of Continuous Deep Policies
9. SAMPLE EFFICIENT ACTOR-CRITIC WITH EXPERIENCE REPLAY(11.13更新)
搜索与监督:
1. End-to-End Training of Deep Visuomotor Policies
2. Interactive Control of Diverse Complex Characters with Neural Networks
连续动作空间下探索改进:
1. Curiosity-driven Exploration in DRL via Bayesian Neuarl Networks
结合策略梯度和Q学习:
1. Q-PROP: SAMPLE-EFFICIENT POLICY GRADIENT WITH AN OFF-POLICY CRITIC(11.13更新)
2. PGQ: COMBINING POLICY GRADIENT AND Q-LEARNING(11.13更新)
其它策略梯度文章:
1. Gradient Estimation Using Stochastic Computation Graphs
2. Continuous Deep Q-Learning with Model-based Acceleration
3. Benchmarking Deep Reinforcement Learning for Continuous Control
4. Learning Continuous Control Policies by Stochastic Value Gradients
五. 分层DRL
1. Deep Successor Reinforcement Learning
2. Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation
3. Hierarchical Reinforcement Learning using Spatio-Temporal Abstractions and Deep Neural Networks
六. DRL中的多任务和迁移学习
1. ADAAPT: A Deep Architecture for Adaptive Policy Transfer from Multiple Sources2. A Deep Hierarchical Approach to Lifelong Learning in Minecraft
3. Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning
5. Progressive Neural Networks
6. Universal Value Function Approximators
7. Multi-task learning with deep model based reinforcement learning(11.14更新)
8. Modular Multitask Reinforcement Learning with Policy Sketches (11.14更新)
七. 基于外部记忆模块的DRL模型
1. Control of Memory, Active Perception, and Action in Minecraft
2. Model-Free Episodic Control
八. DRL中探索与利用问题
1. Action-Conditional Video Prediction using Deep Networks in Atari Games
2. Curiosity-driven Exploration in Deep Reinforcement Learning via Bayesian Neural Networks
3. Deep Exploration via Bootstrapped DQN
4. Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation
5. Incentivizing Exploration In Reinforcement Learning With Deep Predictive Models
6. Unifying Count-Based Exploration and Intrinsic Motivation
7. #Exploration: A Study of Count-Based Exploration for Deep Reinforcemen Learning(11.14更新)
8. Surprise-Based Intrinsic Motivation for Deep Reinforcement Learning(11.14更新)
九. 多Agent的DRL
1. Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks
2. Multiagent Cooperation and Competition with Deep Reinforcement Learning
十. 逆向DRL
1. Guided Cost Learning: Deep Inverse Optimal Control via Policy Optimization
2. Maximum Entropy Deep Inverse Reinforcement Learning
3. Generalizing Skills with Semi-Supervised Reinforcement Learning(11.14更新)
十一. 探索+监督学习
1. Deep learning for real-time Atari game play using offline Monte-Carlo tree search planning
2. Better Computer Go Player with Neural Network and Long-term Prediction
3. Mastering the game of Go with deep neural networks and tree search, D. Silver et al., Nature, 2016.
十二. 异步DRL
1. Asynchronous Methods for Deep Reinforcement Learning
2. Reinforcement Learning through Asynchronous Advantage Actor-Critic on a GPU(11.14更新)
十三:适用于难度较大的游戏场景
2. Strategic Attentive Writer for Learning Macro-Actions
3. Unifying Count-Based Exploration and Intrinsic Motivation
十四:单个网络玩多个游戏
2. Universal Value Function Approximators
3. Learning values across many orders of magnitude
十五:德州poker
1. Deep Reinforcement Learning from Self-Play in Imperfect-Information Games
2. Fictitious Self-Play in Extensive-Form Games
3. Smooth UCT search in computer poker
十六:Doom游戏
1. ViZDoom: A Doom-based AI Research Platform for Visual Reinforcement Learning
2. Training Agent for First-Person Shooter Game with Actor-Critic Curriculum Learning
3. Playing FPS Games with Deep Reinforcement Learning
4. LEARNING TO ACT BY PREDICTING THE FUTURE(11.13更新)
5. Deep Reinforcement Learning From Raw Pixels in Doom(11.14更新)
十七:大规模动作空间
1. Deep Reinforcement Learning in Large Discrete Action Spaces
十八:参数化连续动作空间
1. Deep Reinforcement Learning in Parameterized Action Space
十九:Deep Model
1. Learning Visual Predictive Models of Physics for Playing Billiards
3. Learning Continuous Control Policies by Stochastic Value Gradients
4.Data-Efficient Learning of Feedback Policies from Image Pixels using Deep Dynamical Models
5. Action-Conditional Video Prediction using Deep Networks in Atari Games
6. Incentivizing Exploration In Reinforcement Learning With Deep Predictive Models
二十:DRL应用
机器人领域:
1. Trust Region Policy Optimization
2. Towards Vision-Based Deep Reinforcement Learning for Robotic Motion Control
3. Path Integral Guided Policy Search
4. Memory-based control with recurrent neural networks
6. Learning Deep Neural Network Policies with Continuous Memory States
7. High-Dimensional Continuous Control Using Generalized Advantage Estimation
8. Guided Cost Learning: Deep Inverse Optimal Control via Policy Optimization
9. End-to-End Training of Deep Visuomotor Policies
10. DeepMPC: Learning Deep Latent Features for Model Predictive Control
11. Deep Visual Foresight for Planning Robot Motion
12. Deep Reinforcement Learning for Robotic Manipulation
13. Continuous Deep Q-Learning with Model-based Acceleration
14. Collective Robot Reinforcement Learning with Distributed Asynchronous Guided Policy Search
15. Asynchronous Methods for Deep Reinforcement Learning
16. Learning Continuous Control Policies by Stochastic Value Gradients
机器翻译:
1. Simultaneous Machine Translation using Deep Reinforcement Learning
目标定位:
1. Active Object Localization with Deep Reinforcement Learning
目标驱动的视觉导航:
1. Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning
自动调控参数:
1. Using Deep Q-Learning to Control Optimization Hyperparameters
人机对话:
1. Deep Reinforcement Learning for Dialogue Generation
2. SimpleDS: A Simple Deep Reinforcement Learning Dialogue System
3. Strategic Dialogue Management via Deep Reinforcement Learning
视频预测:
1. Action-Conditional Video Prediction using Deep Networks in Atari Games
文本到语音:
1. WaveNet: A Generative Model for Raw Audio
文本生成:
1. Generating Text with Deep Reinforcement Learning
文本游戏:
1. Language Understanding for Text-based Games Using Deep Reinforcement Learning
无线电操控和信号监控:
1. Deep Reinforcement Learning Radio Control and Signal Detection with KeRLym, a Gym RL Agent
DRL来学习做物理实验:
1. LEARNING TO PERFORM PHYSICS EXPERIMENTS VIA DEEP REINFORCEMENT LEARNING(11.13更新)
DRL加速收敛:
1. Deep Reinforcement Learning for Accelerating the Convergence Rate(11.14更新)
利用DRL来设计神经网络:
1. Designing Neural Network Architectures using Reinforcement Learning(11.14更新)
2. Tuning Recurrent Neural Networks with Reinforcement Learning(11.14更新)
3. Neural Architecture Search with Reinforcement Learning(11.14更新)
控制信号灯:
1. Using a Deep Reinforcement Learning Agent for Traffic Signal Control(11.14更新)
二十一:其它方向
避免危险状态:1. Combating Deep Reinforcement Learning’s Sisyphean Curse with Intrinsic Fear (11.14更新)
DRL中On-Policy vs. Off-Policy 比较:
1. On-Policy vs. Off-Policy Updates for Deep Reinforcement Learning(11.14更新)
最近放出来许多2017ICLR的投稿,有不少是关于DRL的,我目前读过里面比较有意思的有:1. Learning to Play in a Day: Faster Deep Reinforcement Learning by Optimality Tightening,2. PGQ: Combining policy gradient and Q-learning,3. Q-Prop: Sample-Efficient Policy Gradient with An Off-Policy Critic,4. Sample Efficient Actor-Critic with Experience Replay,5. Learning to Act by Predicting the Future。1,2,4都应用在了Atari Games上,3,4 应用在Robotics continuous control上,5 在 Doom Full Deathmatch track 中赢得了第一名。1. 论文名称:Efficient Deep Reinforcement Learning via Adaptive Policy Transfer
论文链接:https://www.aminer.cn/pub/5ef96b048806af6ef2772111/efficient-deep-reinforcement-learning-via-adaptive-policy-transfer?conf=ijcai2020
作者:Tianpei Yang、Jianye Hao、Zhaopeng Meng、Zongzhang Zhang、Yujing Hu、Yingfeng Chen、Changjie Fan、Weixun Wang、Wulong Liu、Zhaodong Wang、Jiajie Peng
简介:· The authors propose a Policy Transfer Framework (PTF) which can efficiently select the optimal source policy and exploit the useful information to facilitate the target task learning.· PTF efficiently avoids negative transfer through terminating the exploitation of current source policy and selects another one adaptively.· PTF can be combined with existing deep DRL methods.· Experimental results show PTF efficiently accelerates the learning process of existing state-ofthe-art DRL methods and outperforms previous policy reuse approaches.
2. 论文名称:KoGuN: Accelerating Deep Reinforcement Learning via Integrating Human Suboptimal Knowledge
论文链接:https://www.aminer.cn/pub/5e4d083f3a55ac8cfd770c23/kogun-accelerating-deep-reinforcement-learning-via-integrating-human-suboptimal-knowledge?conf=ijcai2020
作者:Zhang Peng、Jianye Hao、Wang Weixun、Tang Hongyao、Ma Yi、Duan Yihai、Zheng Yan
简介:· The authors propose a novel policy network framework called KoGuN to leverage human knowledge to accelerate the learning process of RL agents.· The authors firstly evaluate the algorithm on four tasks in Section 4.1 : CartP ole [Barto and Sutton, 1982], LunarLander and LunarLanderContinuous in OpenAI Gym [Brockman et al, 2016] and F lappyBird in PLE [Tasfi, 2016].· The authors show the effectiveness and robustness of KoGuN in sparse reward setting in Section 4.2.· For PPO without KoGuN, the authors use a neural network with two full-connected hidden layers as policy approximator.· For KoGuN with normal network (KoGuN-concat) as refine module, the authors use a neural network with two full-connected hidden layers for the refine module.· For KoGuN with hypernetworks (KoGuN-hyper), the authors use hypernetworks to generate a refine module with one hidden layer.· All hidden layers described above have 32 units. w1 is set to 0.7 at beginning and decays to 0.1 in the end of training phase
3. 论文名称:Generating Behavior-Diverse Game AIs with Evolutionary Multi-Objective Deep Reinforcement Learning
论文链接:https://www.aminer.cn/pub/5ef96b048806af6ef277219d/generating-behavior-diverse-game-ais-with-evolutionary-multi-objective-deep-reinforcement-learning?conf=ijcai2020
作者:Ruimin Shen、Yan Zheng、Jianye Hao、Zhaopeng Meng、Yingfeng Chen、Changjie Fan、Yang Liu
简介:· This paper proposes EMOGI, aiming to efficiently generate behavior-diverse Game AIs by leveraging EA, PMOO and DRL.· Empirical results show the effectiveness of EMOGI in creating diverse and complex behaviors.· To deploy AIs in commercial games, the robustness of the generated AIs is worth investigating as future work [Sun et al, 2020]
4. 论文名称:Solving Hard AI Planning Instances Using Curriculum-Driven Deep Reinforcement Learning
论文链接:https://www.aminer.cn/pub/5eda19d991e01187f5d6db49/solving-hard-ai-planning-instances-using-curriculum-driven-deep-reinforcement-learning?conf=ijcai2020
作者:Feng Dieqiao、Gomes Carla P.、Selman Bart
简介:· The authors presented a framework based on deep RL for solving hard combinatorial planning problems in the domain of Sokoban.· The authors showed the effectiveness of the learning based planning strategy by solving hard Sokoban instances that are out of reach of previous search-based solution techniques, including methods specialized for Sokoban.· Since Sokoban is one of the hardest challenge domains for current AI planners, this work shows the potential of curriculumbased deep RL for solving hard AI planning tasks.
5. 论文名称:I4R: Promoting Deep Reinforcement Learning by the Indicator for Expressive Representations
论文链接:https://www.aminer.cn/pub/5ef96b048806af6ef2772128/i-r-promoting-deep-reinforcement-learning-by-the-indicator-for-expressive-representations?conf=ijcai2020
作者:Xufang Luo、Qi Meng、Di He、Wei Chen、Yunhong Wang
简介:· The authors mainly study the relationship between representations and performance of the DRL agents.· The authors define the NSSV indicator, i.e, the smallest number of significant singular values, as a measurement for learning representations, the authors verify the positive correlation between NSSV and the rewards, and further propose a novel method called I4R, to improve DRL algorthims via adding the corresponding regularization term to enhance NSSV.· The authors show the proposed method I4R based on exploratory experiments, including 3 parts, i.e., observations, the proposed indicator NSSV, and the novel algorithm I4R.
6. 论文名称:Rebalancing Expanding EV Sharing Systems with Deep Reinforcement Learning
论文链接:https://www.aminer.cn/pub/5ef96b048806af6ef2772092/rebalancing-expanding-ev-sharing-systems-with-deep-reinforcement-learning?conf=ijcai2020
作者:Man Luo、Wenzhe Zhang、Tianyou Song、Kun Li、Hongming Zhu、Bowen Du 、Hongkai Wen
简介:· The authors study the incentive-based rebalancing for continuous expanding EV sharing systems.· The authors design a simulator to simulate the operation of EV sharing systems, which is calibrated with real data from an actual EV sharing system for a year.· Extensive experiments have shown that the proposed approach significantly outperforms the baselines and state-of-the-art in both satisfied demand rate and net revenue, and is robust to different levels of system expansion dynamics.· The authors show that the proposed approach performs consistently with different charging time and EV range.
7. 论文名称:Independent Skill Transfer for Deep Reinforcement Learning
论文链接:https://www.aminer.cn/pub/5ef96b048806af6ef2772129/independent-skill-transfer-for-deep-reinforcement-learning?conf=ijcai2020
作者:Qiangxing Tian、Guanchu Wang、Jinxin Liu、Donglin Wang、Yachen Kang
简介:· Deep reinforcement learning (DRL) has wide applications in various challenging fields, such as real-world visual navigation [Zhu et al, 2017], playing games [Silver et al, 2016] and robotic controls [Schulman et al, 2015]· In this work , the authors propose to learn independent skills for efficient skill transfer, where the learned primitive skills with strong correlation are decomposed into independent skills· We take the eigenvalues in Figure 1 as an example: for the case of 6 primitive skills, |Z| = 3 is reasonable since more than 98% component of primitive actions can be represented by three independent components· Effective observation collection and independent skills guarantee the success of low-dimension skill transfer
深度强化学习实验室
来源:ICLR2021
编辑:DeepRL
[1]. What Matters for On-Policy Deep Actor-Critic Methods? A Large-Scale Study
平均得分: 8
得分: ['7', '9', '9', '7']
论文链接: https://openreview.net/forum?id=nIAxjsniDzg
[2]. Invariant Representations for Reinforcement Learning without Reconstruction
平均得分: 7.67
得分: ['9', '7', '7']
论文链接: https://openreview.net/forum?id=-2FCwDKRREu
[3]. Winning the L2RPN Challenge: Power Grid Management via Semi-Markov Afterstate Actor-Critic
平均得分: 7.5
得分: ['7', '9', '7', '7']
论文链接: https://openreview.net/forum?id=LmUJqB1Cz8
[4]. Deep symbolic regression: Recovering mathematical expressions from data via risk-seeking policy gradients
平均得分: 7.5
得分: ['9', '5', '8', '8']
论文链接: https://openreview.net/forum?id=m5Qsh0kBQG
[5]. Parrot: Data-Driven Behavioral Priors for Reinforcement Learning
平均得分: 7.5
得分: ['8', '7', '6', '9']
论文链接: https://openreview.net/forum?id=Ysuv-WOFeKR
[6]. Evolving Reinforcement Learning Algorithms
平均得分: 7.33
得分: ['9', '6', '7']
论文链接: https://openreview.net/forum?id=0XXpJ4OtjW
[7]. Global optimality of softmax policy gradient with single hidden layer neural networks in the mean-field regime
平均得分: 7
得分: ['7', '7', '7', '7']
论文链接: https://openreview.net/forum?id=bB2drc7DPuB
[8]. Single-Timescale Actor-Critic Provably Finds Globally Optimal Policy
平均得分: 7
得分: ['8', '8', '7', '5']
论文链接: https://openreview.net/forum?id=pqZV_srUVmK
[9]. UPDeT: Universal Multi-agent RL via Policy Decoupling with Transformers
平均得分: 7
得分: ['7', '9', '5']
论文链接: https://openreview.net/forum?id=v9c7hr9ADKx
[10]. Regularized Inverse Reinforcement Learning
平均得分: 6.8
得分: ['6', '6', '7', '8', '7']
论文链接: https://openreview.net/forum?id=HgLO8yalfwc
[11]. Randomized Ensembled Double Q-Learning: Learning Fast Without a Model
平均得分: 6.75
得分: ['6', '7', '7', '7']
论文链接: https://openreview.net/forum?id=AY8zfZm0tDd
[12]. Deployment-Efficient Reinforcement Learning via Model-Based Offline Optimization
平均得分: 6.75
得分: ['8', '7', '5', '7']
论文链接: https://openreview.net/forum?id=3hGNqpI4WS
[13]. Image Augmentation Is All You Need: Regularizing Deep Reinforcement Learning from Pixels
平均得分: 6.75
得分: ['7', '6', '7', '7']
论文链接: https://openreview.net/forum?id=GY6-6sTvGaf
[14]. Support-set bottlenecks for video-text representation learning
平均得分: 6.75
得分: ['6', '9', '7', '5']
论文链接: https://openreview.net/forum?id=EqoXe2zmhrh
[15]. A Sharp Analysis of Model-based Reinforcement Learning with Self-Play
平均得分: 6.75
得分: ['4', '7', '8', '8']
论文链接: https://openreview.net/forum?id=9Y7_c5ZAd5i
[16]. RODE: Learning Roles to Decompose Multi-Agent Tasks
平均得分: 6.67
得分: ['8', '6', '6']
论文链接: https://openreview.net/forum?id=TTUVg6vkNjK
[17]. Text Generation by Learning from Off-Policy Demonstrations
平均得分: 6.6
得分: ['7', '7', '7', '5', '7']
论文链接: https://openreview.net/forum?id=RovX-uQ1Hua
[18]. Robust Reinforcement Learning on State Observations with Learned Optimal Adversary
平均得分: 6.5
得分: ['5', '7', '7', '7']
论文链接: https://openreview.net/forum?id=sCZbhBvqQaU
[19]. Self-supervised Visual Reinforcement Learning with Object-centric Representations
平均得分: 6.5
得分: ['7', '6', '4', '9']
论文链接: https://openreview.net/forum?id=xppLmXCbOw1
[20]. On Effective Parallelization of Monte Carlo Tree Search
平均得分: 6.5
得分: ['6', '6', '7', '7']
论文链接: https://openreview.net/forum?id=_FXqMj7T0QQ
[21]. Non-asymptotic Confidence Intervals of Off-policy Evaluation: Primal and Dual Bounds
平均得分: 6.5
得分: ['6', '5', '8', '7']
论文链接: https://openreview.net/forum?id=dKg5D1Z1Lm
[22]. Efficient Transformers in Reinforcement Learning using Actor-Learner Distillation
平均得分: 6.5
得分: ['5', '6', '7', '8']
论文链接: https://openreview.net/forum?id=uR9LaO_QxF
[23]. Ask Your Humans: Using Human Instructions to Improve Generalization in Reinforcement Learning
平均得分: 6.5
得分: ['8', '7', '5', '6']
论文链接: https://openreview.net/forum?id=Y87Ri-GNHYu
[24]. SMiRL: Surprise Minimizing Reinforcement Learning in Unstable Environments
平均得分: 6.5
得分: ['5', '6', '8', '7']
论文链接: https://openreview.net/forum?id=cPZOyoDloxl
[25]. Model-Based Visual Planning with Self-Supervised Functional Distances
平均得分: 6.5
得分: ['7', '6', '7', '6']
论文链接: https://openreview.net/forum?id=UcoXdfrORC
[26]. Learning-based Support Estimation in Sublinear Time
平均得分: 6.5
得分: ['7', '4', '8', '7']
论文链接: https://openreview.net/forum?id=tilovEHA3YS
[27]. DOP: Off-Policy Multi-Agent Decomposed Policy Gradients
平均得分: 6.5
得分: ['7', '3', '9', '7']
论文链接: https://openreview.net/forum?id=6FqKiVAdI3Y
[28]. Correcting experience replay for multi-agent communication
平均得分: 6.5
得分: ['4', '6', '8', '8']
论文链接: https://openreview.net/forum?id=xvxPuCkCNPO
[29]. Risk-Averse Offline Reinforcement Learning
平均得分: 6.4
得分: ['6', '8', '5', '6', '7']
论文链接: https://openreview.net/forum?id=TBIzh9b5eaz
[30]. Learning Value Functions in Deep Policy Gradients using Residual Variance
平均得分: 6.33
得分: ['8', '7', '4']
论文链接: https://openreview.net/forum?id=NX1He-aFO_F
[31]. Contrastive Explanations for Reinforcement Learning via Embedded Self Predictions
平均得分: 6.33
得分: ['4', '8', '7']
论文链接: https://openreview.net/forum?id=Ud3DSz72nYR
[32]. PODS: Policy Optimization via Differentiable Simulation
平均得分: 6.33
得分: ['9', '4', '6']
论文链接: https://openreview.net/forum?id=4f04RAhMUo6
[33]. Transient Non-stationarity and Generalisation in Deep Reinforcement Learning
平均得分: 6.25
得分: ['7', '5', '5', '8']
论文链接: https://openreview.net/forum?id=Qun8fv4qSby
[34]. Improving Learning to Branch via Reinforcement Learning
平均得分: 6.25
得分: ['7', '7', '8', '3']
论文链接: https://openreview.net/forum?id=M_KwRsbhi5e
[35]. Mastering Atari with Discrete World Models
平均得分: 6.25
得分: ['4', '7', '10', '4']
论文链接: https://openreview.net/forum?id=0oabwyZbOu
[36]. Data-Efficient Reinforcement Learning with Self-Predictive Representations
平均得分: 6.25
得分: ['6', '5', '7', '7']
论文链接: https://openreview.net/forum?id=uCQfPZwRaUu
[37]. Local Information Opponent Modelling Using Variational Autoencoders
平均得分: 6.25
得分: ['8', '7', '4', '6']
论文链接: https://openreview.net/forum?id=xF5r3dVeaEl
[38]. Contrastive Behavioral Similarity Embeddings for Generalization in Reinforcement Learning
平均得分: 6.25
得分: ['6', '6', '6', '7']
论文链接: https://openreview.net/forum?id=qda7-sVg84
[39]. Efficient Reinforcement Learning in Factored MDPs with Application to Constrained RL
平均得分: 6.25
得分: ['7', '5', '7', '6']
论文链接: https://openreview.net/forum?id=fmtSg8591Q
[40]. Batch Reinforcement Learning Through Continuation Method
平均得分: 6.25
得分: ['6', '9', '6', '4']
论文链接: https://openreview.net/forum?id=po-DLlBuAuz
[41]. Optimistic Exploration with Backward Bootstrapped Bonus for Deep Reinforcement Learning
平均得分: 6.2
得分: ['7', '6', '7', '6', '5']
论文链接: https://openreview.net/forum?id=QxQkG-gIKJM
[42]. Optimism in Reinforcement Learning with Generalized Linear Function Approximation
平均得分: 6
得分: ['6', '7', '6', '5']
论文链接: https://openreview.net/forum?id=CBmJwzneppz
[43]. Adversarially Guided Actor-Critic
平均得分: 6
得分: ['5', '6', '7']
论文链接: https://openreview.net/forum?id=_mQp5cr_iNy
[44]. QTRAN++: Improved Value Transformation for Cooperative Multi-Agent Reinforcement Learning
平均得分: 6
得分: ['7', '6', '6', '5']
论文链接: https://openreview.net/forum?id=TlS3LBoDj3Z
[45]. Policy Optimization in Zero-Sum Markov Games: Fictitious Self-Play Provably Attains Nash Equilibria
平均得分: 6
得分: ['6', '5', '8', '5']
论文链接: https://openreview.net/forum?id=c3MWGN_cTf
[46]. Optimistic Policy Optimization with General Function Approximations
平均得分: 6
得分: ['7', '7', '4']
论文链接: https://openreview.net/forum?id=JydXRRDoDTv
[47]. Multi-Agent Collaboration via Reward Attribution Decomposition
平均得分: 6
得分: ['5', '6', '7', '6']
论文链接: https://openreview.net/forum?id=GVNGAaY2Dr1
[48]. Efficient Wasserstein Natural Gradients for Reinforcement Learning
平均得分: 6
得分: ['5', '8', '5']
论文链接: https://openreview.net/forum?id=OHgnfSrn2jv
[49]. Density Constrained Reinforcement Learning
平均得分: 6
得分: ['7', '6', '5', '6']
论文链接: https://openreview.net/forum?id=jMc7DlflrMC
[50]. Representation Balancing Offline Model-based Reinforcement Learning
平均得分: 6
得分: ['5', '6', '7', '6']
论文链接: https://openreview.net/forum?id=QpNz8r_Ri2Y
[51]. Decoupling Representation Learning from Reinforcement Learning
平均得分: 6
得分: ['7', '5', '4', '8']
论文链接: https://openreview.net/forum?id=_SKUm2AJpvN
[52]. Model-based micro-data reinforcement learning: what are the crucial model properties and which model to choose?
平均得分: 5.8
得分: ['7', '7', '6', '5', '4']
论文链接: https://openreview.net/forum?id=p5uylG94S68
[53]. Model-based Asynchronous Hyperparameter and Neural Architecture Search
平均得分: 5.8
得分: ['7', '5', '6', '6', '5']
论文链接: https://openreview.net/forum?id=a2rFihIU7i
[54]. DeepAveragers: Offline Reinforcement Learning By Solving Derived Non-Parametric MDPs
平均得分: 5.8
得分: ['5', '7', '5', '7', '5']
论文链接: https://openreview.net/forum?id=eMP1j9efXtX
[55]. Uncertainty Weighted Offline Reinforcement Learning
平均得分: 5.8
得分: ['8', '6', '5', '6', '4']
论文链接: https://openreview.net/forum?id=7hMenh--8g
[56]. Optimizing Memory Placement using Evolutionary Graph Reinforcement Learning
平均得分: 5.75
得分: ['5', '7', '5', '6']
论文链接: https://openreview.net/forum?id=-6vS_4Kfz0
[57]. Parameter-based Value Functions
平均得分: 5.75
得分: ['3', '7', '7', '6']
论文链接: https://openreview.net/forum?id=tV6oBfuyLTQ
[58]. Sample-Efficient Automated Deep Reinforcement Learning
平均得分: 5.75
得分: ['7', '5', '5', '6']
论文链接: https://openreview.net/forum?id=hSjxQ3B7GWq
[59]. Causal Inference Q-Network: Toward Resilient Reinforcement Learning
平均得分: 5.75
得分: ['4', '6', '6', '7']
论文链接: https://openreview.net/forum?id=PvVbsAmxdlZ
[60]. SACoD: Sensor Algorithm Co-Design Towards Efficient CNN-powered Intelligent PhlatCam
平均得分: 5.75
得分: ['6', '6', '5', '6']
论文链接: https://openreview.net/forum?id=jQUf0TmN-oT
[61]. Learn Goal-Conditioned Policy with Intrinsic Motivation for Deep Reinforcement Learning
平均得分: 5.75
得分: ['6', '7', '5', '5']
论文链接: https://openreview.net/forum?id=MmcywoW7PbJ
[62]. Benchmarks for Deep Off-Policy Evaluation
平均得分: 5.75
得分: ['7', '6', '4', '6']
论文链接: https://openreview.net/forum?id=kWSeGEeHvF8
[63]. Shortest-Path Constrained Reinforcement Learning for Sparse Reward Tasks
平均得分: 5.75
得分: ['6', '5', '6', '6']
论文链接: https://openreview.net/forum?id=Y-Wl1l0Va-
[64]. Exploring Zero-Shot Emergent Communication in Embodied Multi-Agent Populations
平均得分: 5.75
得分: ['6', '4', '6', '7']
论文链接: https://openreview.net/forum?id=Fblk4_Fd7ao
[65]. Randomized Entity-wise Factorization for Multi-Agent Reinforcement Learning
平均得分: 5.75
得分: ['5', '5', '7', '6']
论文链接: https://openreview.net/forum?id=szUsQ3NcQwV
[66]. Learning Robust State Abstractions for Hidden-Parameter Block MDPs
平均得分: 5.75
得分: ['5', '6', '5', '7']
论文链接: https://openreview.net/forum?id=fmOOI2a3tQP
[67]. Adapting to Reward Progressivity via Spectral Reinforcement Learning
平均得分: 5.75
得分: ['5', '7', '5', '6']
论文链接: https://openreview.net/forum?id=dyjPVUc2KB
[68]. Accelerating Safe Reinforcement Learning with Constraint-mismatched Policies
平均得分: 5.75
得分: ['5', '6', '5', '7']
论文链接: https://openreview.net/forum?id=M3NDrHEGyyO
[69]. Off-Dynamics Reinforcement Learning: Training for Transfer with Domain Classifiers
平均得分: 5.75
得分: ['5', '6', '5', '7']
论文链接: https://openreview.net/forum?id=eqBwg3AcIAK
[70]. Meta-Reinforcement Learning With Informed Policy Regularization
平均得分: 5.75
得分: ['6', '5', '6', '6']
论文链接: https://openreview.net/forum?id=pTZ6EgZtzDU
[71]. Hierarchical Reinforcement Learning by Discovering Intrinsic Options
平均得分: 5.75
得分: ['4', '4', '7', '8']
论文链接: https://openreview.net/forum?id=r-gPPHEjpmw
[72]. Multi-Agent Trust Region Learning
平均得分: 5.75
得分: ['4', '8', '5', '6']
论文链接: https://openreview.net/forum?id=eHG7asK_v-k
[73]. Unity of Opposites: SelfNorm and CrossNorm for Model Robustness
平均得分: 5.75
得分: ['5', '7', '6', '5']
论文链接: https://openreview.net/forum?id=Oj2hGyJwhwX
[74]. The Advantage Regret-Matching Actor-Critic
平均得分: 5.67
得分: ['5', '6', '6']
论文链接: https://openreview.net/forum?id=YMsbeG6FqBU
[75]. Differentiable Trust Region Layers for Deep Reinforcement Learning
平均得分: 5.67
得分: ['7', '4', '6']
论文链接: https://openreview.net/forum?id=qYZD-AO1Vn
[76]. Linear Representation Meta-Reinforcement Learning for Instant Adaptation
平均得分: 5.67
得分: ['5', '5', '7']
论文链接: https://openreview.net/forum?id=lNrtNGkr-vw
[77]. Symmetry-Aware Actor-Critic for 3D Molecular Design
平均得分: 5.67
得分: ['6', '4', '7']
论文链接: https://openreview.net/forum?id=jEYKjPE1xYN
[78]. The Importance of Pessimism in Fixed-Dataset Policy Optimization
平均得分: 5.67
得分: ['5', '5', '7']
论文链接: https://openreview.net/forum?id=E3Ys6a1NTGT
[79]. Understanding and Leveraging Causal Relations in Deep Reinforcement Learning
平均得分: 5.67
得分: ['5', '6', '6']
论文链接: https://openreview.net/forum?id=30I4Azqc_oP
[80]. Efficient Fully-Offline Meta-Reinforcement Learning via Distance Metric Learning and Behavior Regularization
平均得分: 5.67
得分: ['7', '5', '5']
论文链接: https://openreview.net/forum?id=8cpHIfgY4Dj
[81]. Grounding Language to Entities for Generalization in Reinforcement Learning
平均得分: 5.6
得分: ['6', '7', '6', '5', '4']
论文链接: https://openreview.net/forum?id=udbMZR1cKE6
[82]. Large Batch Simulation for Deep Reinforcement Learning
平均得分: 5.6
得分: ['7', '6', '6', '5', '4']
论文链接: https://openreview.net/forum?id=cP5IcoAkfKa
[83]. Deep Reinforcement Learning For Wireless Scheduling with Multiclass Services
平均得分: 5.5
得分: ['3', '7', '7', '5']
论文链接: https://openreview.net/forum?id=UiLl8yjh57
[84]. Monotonic Robust Policy Optimization with Model Discrepancy
平均得分: 5.5
得分: ['7', '6', '5', '4']
论文链接: https://openreview.net/forum?id=kdm4Lm9rgB
[85]. Truly Deterministic Policy Optimization
平均得分: 5.5
得分: ['5', '6', '6', '5']
论文链接: https://openreview.net/forum?id=BntruCi1uvF
[86]. Distributional Reinforcement Learning for Risk-Sensitive Policies
平均得分: 5.5
得分: ['5', '7', '5', '5']
论文链接: https://openreview.net/forum?id=19drPzGV691
[87]. Bounded Myopic Adversaries for Deep Reinforcement Learning Agents
平均得分: 5.5
得分: ['5', '6', '5', '6']
论文链接: https://openreview.net/forum?id=Ew0zR07CYRd
[88]. Decoupling Exploration and Exploitation for Meta-Reinforcement Learning without Sacrifices
平均得分: 5.5
得分: ['7', '6', '4', '5']
论文链接: https://openreview.net/forum?id=rSwTMomgCz
[89]. Discovering Diverse Multi-Agent Strategic Behavior via Reward Randomization
平均得分: 5.5
得分: ['5', '7', '5', '5']
论文链接: https://openreview.net/forum?id=lvRTC669EY_
[90]. Blending MPC & Value Function Approximation for Efficient Reinforcement Learning
平均得分: 5.5
得分: ['5', '5', '5', '7']
论文链接: https://openreview.net/forum?id=RqCC_00Bg7V
[91]. A Policy Gradient Algorithm for Learning to Learn in Multiagent Reinforcement Learning
平均得分: 5.5
得分: ['6', '5', '5', '6']
论文链接: https://openreview.net/forum?id=zdrls6LIX4W
[92]. The act of remembering: A study in partially observable reinforcement learning
平均得分: 5.5
得分: ['6', '7', '6', '3']
论文链接: https://openreview.net/forum?id=uFkGzn9RId8
[93]. Random Coordinate Langevin Monte Carlo
平均得分: 5.5
得分: ['7', '7', '4', '4']
论文链接: https://openreview.net/forum?id=lbc44k2jgnX
[94]. Provable Rich Observation Reinforcement Learning with Combinatorial Latent States
平均得分: 5.5
得分: ['4', '6', '5', '7']
论文链接: https://openreview.net/forum?id=hx1IXFHAw7R
[95]. Automatic Data Augmentation for Generalization in Reinforcement Learning
平均得分: 5.5
得分: ['6', '7', '3', '6']
论文链接: https://openreview.net/forum?id=9l9WD4ahJgs
[96]. Reinforcement Learning with Random Delays
平均得分: 5.5
得分: ['3', '6', '5', '8']
论文链接: https://openreview.net/forum?id=QFYnKlBJYR
[97]. On Proximal Policy Optimization's Heavy-Tailed Gradients
平均得分: 5.5
得分: ['6', '5', '6', '5']
论文链接: https://openreview.net/forum?id=cYek5NoXNiX
[98]. A Primal Approach to Constrained Policy Optimization: Global Optimality and Finite-Time Analysis
平均得分: 5.5
得分: ['7', '5', '5', '5']
论文链接: https://openreview.net/forum?id=rI3RMgDkZqJ
[99]. Regularization Matters in Policy Optimization - An Empirical Study on Continuous Control
平均得分: 5.5
得分: ['4', '6', '5', '7']
论文链接: https://openreview.net/forum?id=yr1mzrH3IC
[100]. Divide-and-Conquer Monte Carlo Tree Search
平均得分: 5.5
得分: ['8', '5', '4', '5']
论文链接: https://openreview.net/forum?id=Nj8EIrSu5O
[101]. Status-Quo Policy Gradient in Multi-agent Reinforcement Learning
平均得分: 5.5
得分: ['4', '5', '6', '7']
论文链接: https://openreview.net/forum?id=76M3pxkqRl
[102]. QPLEX: Duplex Dueling Multi-Agent Q-Learning
平均得分: 5.5
得分: ['4', '5', '6', '7']
论文链接: https://openreview.net/forum?id=Rcmk0xxIQV
[103]. A Reduction Approach to Constrained Reinforcement Learning
平均得分: 5.5
得分: ['6', '7', '5', '4']
论文链接: https://openreview.net/forum?id=fV4vvs1J5iM
[104]. Compute- and Memory-Efficient Reinforcement Learning with Latent Experience Replay
平均得分: 5.5
得分: ['7', '4', '5', '6']
论文链接: https://openreview.net/forum?id=J7bUsLCb0zf
[105]. On Trade-offs of Image Prediction in Visual Model-Based Reinforcement Learning
平均得分: 5.5
得分: ['5', '3', '7', '7']
论文链接: https://openreview.net/forum?id=mewtfP6YZ7
[106]. Towards Understanding Linear Value Decomposition in Cooperative Multi-Agent Q-Learning
平均得分: 5.5
得分: ['5', '7', '5', '5']
论文链接: https://openreview.net/forum?id=VMtftZqMruq
[107]. Average Reward Reinforcement Learning with Monotonic Policy Improvement
平均得分: 5.5
得分: ['6', '4', '6', '6']
论文链接: https://openreview.net/forum?id=lo7GKwmakFZ
[108]. FactoredRL: Leveraging Factored Graphs for Deep Reinforcement Learning
平均得分: 5.5
得分: ['5', '6', '6', '5']
论文链接: https://openreview.net/forum?id=wE-3ly4eT5G
[109]. Implicit Under-Parameterization Inhibits Data-Efficient Deep Reinforcement Learning
平均得分: 5.5
得分: ['4', '7', '6', '5']
论文链接: https://openreview.net/forum?id=O9bnihsFfXU
[110]. Scalable Bayesian Inverse Reinforcement Learning by Auto-Encoding Reward
平均得分: 5.5
得分: ['4', '5', '7', '6']
论文链接: https://openreview.net/forum?id=4qR3coiNaIv
[111]. Model-Based Offline Planning
平均得分: 5.5
得分: ['6', '4', '8', '4']
论文链接: https://openreview.net/forum?id=OMNB1G5xzd4
[112]. BRAC+: Going Deeper with Behavior Regularized Offline Reinforcement Learning
平均得分: 5.5
得分: ['4', '6', '7', '5']
论文链接: https://openreview.net/forum?id=bMCfFepJXM
[113]. Learning to Share in Multi-Agent Reinforcement Learning
平均得分: 5.4
得分: ['4', '4', '8', '8', '3']
论文链接: https://openreview.net/forum?id=awnQ2qTLSwn
[114]. Explicit Pareto Front Optimization for Constrained Reinforcement Learning
平均得分: 5.33
得分: ['6', '6', '4']
论文链接: https://openreview.net/forum?id=pOHW7EwFbo9
[115]. Guided Exploration with Proximal Policy Optimization using a Single Demonstration
平均得分: 5.33
得分: ['6', '4', '6']
论文链接: https://openreview.net/forum?id=88_MfcJoJlS
[116]. Unsupervised Active Pre-Training for Reinforcement Learning
平均得分: 5.33
得分: ['5', '6', '5']
论文链接: https://openreview.net/forum?id=cvNYovr16SB
[117]. RECONNAISSANCE FOR REINFORCEMENT LEARNING WITH SAFETY CONSTRAINTS
平均得分: 5.33
得分: ['4', '5', '7']
论文链接: https://openreview.net/forum?id=Gc4MQq-JIgj
[118]. Daylight: Assessing Generalization Skills of Deep Reinforcement Learning Agents
平均得分: 5.33
得分: ['6', '5', '5']
论文链接: https://openreview.net/forum?id=Z3XVHSbSawb
[119]. Diversity Actor-Critic: Sample-Aware Entropy Regularization for Sample-Efficient Exploration
平均得分: 5.33
得分: ['4', '5', '7']
论文链接: https://openreview.net/forum?id=7qmQNB6Wn_B
[120]. OPAL: Offline Primitive Discovery for Accelerating Offline Reinforcement Learning
平均得分: 5.33
得分: ['7', '5', '4']
论文链接: https://openreview.net/forum?id=V69LGwJ0lIN
[121]. A REINFORCEMENT LEARNING FRAMEWORK FOR TIME DEPENDENT CAUSAL EFFECTS EVALUATION IN A/B TESTING
平均得分: 5.33
得分: ['6', '5', '5']
论文链接: https://openreview.net/forum?id=Dtahsj2FkrK
[122]. PettingZoo: Gym for Multi-Agent Reinforcement Learning
平均得分: 5.25
得分: ['7', '5', '6', '3']
论文链接: https://openreview.net/forum?id=WoLQsYU8aZ
[123]. Hippocampal representations emerge when training recurrent neural networks on a memory dependent maze navigation task
平均得分: 5.25
得分: ['4', '6', '4', '7']
论文链接: https://openreview.net/forum?id=Jr8XGtK04Pw
[124]. Data-efficient Hindsight Off-policy Option Learning
平均得分: 5.25
得分: ['5', '6', '5', '5']
论文链接: https://openreview.net/forum?id=QKbS9KXkE_y
[125]. Attacking Few-Shot Classifiers with Adversarial Support Sets
平均得分: 5.25
得分: ['6', '4', '6', '5']
论文链接: https://openreview.net/forum?id=0xdQXkz69x9
[126]. Coverage as a Principle for Discovering Transferable Behavior in Reinforcement Learning
平均得分: 5.25
得分: ['8', '5', '4', '4']
论文链接: https://openreview.net/forum?id=INhwJdJtxn6
[127]. Reinforcement Learning for Control with Probabilistic Stability Guarantee
平均得分: 5.25
得分: ['6', '5', '5', '5']
论文链接: https://openreview.net/forum?id=QfEssgaXpm
[128]. Efficient Reinforcement Learning in Resource Allocation Problems Through Permutation Invariant Multi-task Learning
平均得分: 5.25
得分: ['7', '5', '5', '4']
论文链接: https://openreview.net/forum?id=TiGF63rxr8Q
[129]. Meta-Reinforcement Learning Robust to Distributional Shift via Model Identification and Experience Relabeling
平均得分: 5.25
得分: ['6', '5', '5', '5']
论文链接: https://openreview.net/forum?id=AT7jak63NNK
[130]. Solving Compositional Reinforcement Learning Problems via Task Reduction
平均得分: 5.25
得分: ['3', '5', '6', '7']
论文链接: https://openreview.net/forum?id=9SS69KwomAM
[131]. Emergent Road Rules In Multi-Agent Driving Environments
平均得分: 5.25
得分: ['7', '4', '5', '5']
论文链接: https://openreview.net/forum?id=d8Q1mt2Ghw
[132]. EMaQ: Expected-Max Q-Learning Operator for Simple Yet Effective Offline and Online RL
平均得分: 5.25
得分: ['4', '6', '6', '5']
论文链接: https://openreview.net/forum?id=B8fp0LVMHa
[133]. Double Q-learning: New Analysis and Sharper Finite-time Bound
平均得分: 5.25
得分: ['6', '4', '6', '5']
论文链接: https://openreview.net/forum?id=MwxaStJXK6v
[134]. Safety Verification of Model Based Reinforcement Learning Controllers
平均得分: 5.25
得分: ['3', '7', '6', '5']
论文链接: https://openreview.net/forum?id=mfJepDyIUcQ
[135]. D3C: Reducing the Price of Anarchy in Multi-Agent Learning
平均得分: 5.25
得分: ['3', '4', '7', '7']
论文链接: https://openreview.net/forum?id=8wa7HrUsElL
[136]. Near-Optimal Regret Bounds for Model-Free RL in Non-Stationary Episodic MDPs
平均得分: 5.25
得分: ['6', '4', '4', '7']
论文链接: https://openreview.net/forum?id=TJzkxFw-mGm
[137]. Communication in Multi-Agent Reinforcement Learning: Intention Sharing
平均得分: 5.25
得分: ['6', '4', '6', '5']
论文链接: https://openreview.net/forum?id=qpsl2dR9twy
[138]. On the role of planning in model-based deep reinforcement learning
平均得分: 5.25
得分: ['7', '3', '6', '5']
论文链接: https://openreview.net/forum?id=IrM64DGB21
[139]. Reinforcement Learning with Latent Flow
平均得分: 5.25
得分: ['7', '3', '6', '5']
论文链接: https://openreview.net/forum?id=lSijhyKKsct
[140]. Iterative Amortized Policy Optimization
平均得分: 5.25
得分: ['6', '5', '5', '5']
论文链接: https://openreview.net/forum?id=49mMdsxkPlD
[141]. Unsupervised Task Clustering for Multi-Task Reinforcement Learning
平均得分: 5.25
得分: ['6', '5', '5', '5']
论文链接: https://openreview.net/forum?id=4K_NaDAHc0d
[142]. Adaptive Multi-model Fusion Learning for Sparse-Reward Reinforcement Learning
平均得分: 5.25
得分: ['6', '5', '6', '4']
论文链接: https://openreview.net/forum?id=4emQEegFhSy
[143]. ERMAS: Learning Policies Robust to Reality Gaps in Multi-Agent Simulations
平均得分: 5.25
得分: ['6', '5', '6', '4']
论文链接: https://openreview.net/forum?id=uIc4W6MtbDA
[144]. A Distributional Perspective on Actor-Critic Framework
平均得分: 5.25
得分: ['5', '7', '3', '6']
论文链接: https://openreview.net/forum?id=jWXBUsWP7N
[145]. Robust Reinforcement Learning using Adversarial Populations
平均得分: 5.25
得分: ['5', '7', '4', '5']
论文链接: https://openreview.net/forum?id=I6NRcao1w-X
[146]. The Compact Support Neural Network
平均得分: 5.25
得分: ['5', '5', '6', '5']
论文链接: https://openreview.net/forum?id=xCy9thPPTb_
[147]. RMIX: Risk-Sensitive Multi-Agent Reinforcement Learning
平均得分: 5.25
得分: ['6', '4', '7', '4']
论文链接: https://openreview.net/forum?id=1EVb8XRBDNr
[148]. Meta-Model-Based Meta-Policy Optimization
平均得分: 5.25
得分: ['5', '5', '5', '6']
论文链接: https://openreview.net/forum?id=KOtxfjpQsq
[149]. Decentralized Deterministic Multi-Agent Reinforcement Learning
平均得分: 5.2
得分: ['5', '4', '7', '5', '5']
论文链接: https://openreview.net/forum?id=QM4_h99pjCE
[150]. Transfer among Agents: An Efficient Multiagent Transfer Learning Framework
平均得分: 5.2
得分: ['5', '6', '4', '6', '5']
论文链接: https://openreview.net/forum?id=9w03rTs7w5
[151]. Gradient-based tuning of Hamiltonian Monte Carlo hyperparameters
平均得分: 5
得分: ['5', '4', '6', '5']
论文链接: https://openreview.net/forum?id=LvJ8hLSusrv
[152]. Combining Imitation and Reinforcement Learning with Free Energy Principle
平均得分: 5
得分: ['4', '6', '5', '5']
论文链接: https://openreview.net/forum?id=JI2TGOehNT0
[153]. Ordering-Based Causal Discovery with Reinforcement Learning
平均得分: 5
得分: ['5', '5', '5', '5']
论文链接: https://openreview.net/forum?id=bMzj6hXL2VJ
[154]. Universal Value Density Estimation for Imitation Learning and Goal-Conditioned Reinforcement Learning
平均得分: 5
得分: ['5', '5', '4', '6']
论文链接: https://openreview.net/forum?id=S2UB9PkrEjF
[155]. The Emergence of Individuality in Multi-Agent Reinforcement Learning
平均得分: 5
得分: ['5', '5', '4', '6']
论文链接: https://openreview.net/forum?id=EoVmlONgI9e
[156]. Explore with Dynamic Map: Graph Structured Reinforcement Learning
平均得分: 5
得分: ['4', '5', '6', '5']
论文链接: https://openreview.net/forum?id=-u4j4dHeWQi
[157]. Offline Meta-Reinforcement Learning with Advantage Weighting
平均得分: 5
得分: ['5', '6', '5', '4']
论文链接: https://openreview.net/forum?id=S5S3eTEmouw
[158]. Deep Q-Learning with Low Switching Cost
平均得分: 5
得分: ['6', '5', '5', '4']
论文链接: https://openreview.net/forum?id=7ODIasgLJlU
[159]. AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
平均得分: 5
得分: ['6', '6', '3', '6', '4']
论文链接: https://openreview.net/forum?id=OJiM1R3jAtZ
[160]. A Strong On-Policy Competitor To PPO
平均得分: 5
得分: ['5', '5', '5']
论文链接: https://openreview.net/forum?id=0migj5lyUZl
[161]. Control-Aware Representations for Model-based Reinforcement Learning
平均得分: 5
得分: ['6', '5', '4']
论文链接: https://openreview.net/forum?id=dgd4EJqsbW5
[162]. Formal Language Constrained Markov Decision Processes
平均得分: 5
得分: ['5', '6', '4', '5']
论文链接: https://openreview.net/forum?id=NTP9OdaT6nm
[163]. Multi-Agent Imitation Learning with Copulas
平均得分: 5
得分: ['4', '4', '7']
论文链接: https://openreview.net/forum?id=gRr_gt5bker
[164]. Projected Latent Markov Chain Monte Carlo: Conditional Sampling of Normalizing Flows
平均得分: 5
得分: ['6', '5', '4']
论文链接: https://openreview.net/forum?id=MBpHUFrcG2x
[165]. Efficient Competitive Self-Play Policy Optimization
平均得分: 5
得分: ['7', '5', '3', '5']
论文链接: https://openreview.net/forum?id=99M-4QlinPr
[166]. Offline Model-Based Optimization via Normalized Maximum Likelihood Estimation
平均得分: 5
得分: ['5', '5', '5']
论文链接: https://openreview.net/forum?id=FmMKSO4e8JK
[167]. Beyond Prioritized Replay: Sampling States in Model-Based RL via Simulated Priorities
平均得分: 5
得分: ['4', '6', '5']
论文链接: https://openreview.net/forum?id=B5bZp0m7jZd
[168]. Action Guidance: Getting the Best of Sparse Rewards and Shaped Rewards for Real-time Strategy Games
平均得分: 5
得分: ['6', '4', '6', '4']
论文链接: https://openreview.net/forum?id=1OQ90khuUGZ
[169]. What About Taking Policy as Input of Value Function: Policy-extended Value Function Approximator
平均得分: 5
得分: ['7', '5', '5', '3']
论文链接: https://openreview.net/forum?id=V4AVDoFtVM
[170]. Optimizing Information Bottleneck in Reinforcement Learning: A Stein Variational Approach
平均得分: 5
得分: ['6', '4', '5', '5']
论文链接: https://openreview.net/forum?id=IKqCy8i1XL3
[171]. On the Estimation Bias in Double Q-Learning
平均得分: 5
得分: ['6', '5', '3', '6']
论文链接: https://openreview.net/forum?id=FKotzp6PZJw
[172]. Entropic Risk-Sensitive Reinforcement Learning: A Meta Regret Framework with Function Approximation
平均得分: 5
得分: ['6', '5', '4', '5']
论文链接: https://openreview.net/forum?id=q_kZm9eHIeD
[173]. Goal-Auxiliary Actor-Critic for 6D Robotic Grasping with Point Clouds
平均得分: 5
得分: ['5', '7', '3']
论文链接: https://openreview.net/forum?id=H5B3lmpO1g
[174]. Policy Gradient with Expected Quadratic Utility Maximization: A New Mean-Variance Approach in Reinforcement Learning
平均得分: 5
得分: ['4', '5', '6']
论文链接: https://openreview.net/forum?id=BEs-Q1ggdwT
[175]. D2RL: Deep Dense Architectures in Reinforcement Learning
平均得分: 5
得分: ['4', '8', '4', '4']
论文链接: https://openreview.net/forum?id=mYNfmvt8oSv
[176]. Intention Propagation for Multi-agent Reinforcement Learning
平均得分: 5
得分: ['3', '6', '6', '5']
论文链接: https://openreview.net/forum?id=7apQQsbahFz
[177]. SIM-GAN: Adversarial Calibration of Multi-Agent Market Simulators.
平均得分: 5
得分: ['3', '7', '5']
论文链接: https://openreview.net/forum?id=1z_Hg9oBCtY
[178]. Preventing Value Function Collapse in Ensemble Q-Learning by Maximizing Representation Diversity
平均得分: 5
得分: ['4', '5', '5', '6']
论文链接: https://openreview.net/forum?id=dN_iVr6iNuU
[179]. REPAINT: Knowledge Transfer in Deep Actor-Critic Reinforcement Learning
平均得分: 5
得分: ['4', '6', '4', '6']
论文链接: https://openreview.net/forum?id=P84ryxVG6tR
[180]. Mixture of Step Returns in Bootstrapped DQN
平均得分: 5
得分: ['5', '4', '4', '7', '5']
论文链接: https://openreview.net/forum?id=X6YPReSv5CX
[181]. PAC-Bayesian Randomized Value Function with Informative Prior
平均得分: 4.8
得分: ['7', '3', '5', '4', '5']
论文链接: https://openreview.net/forum?id=d2m6yCwyJW
[182]. Learning Safe Multi-agent Control with Decentralized Neural Barrier Certificates
平均得分: 4.8
得分: ['4', '4', '6', '5', '5']
论文链接: https://openreview.net/forum?id=P6_q1BRxY8Q
[183]. Maximum Reward Formulation In Reinforcement Learning
平均得分: 4.8
得分: ['5', '6', '3', '4', '6']
论文链接: https://openreview.net/forum?id=BnokSKnhC7F
[184]. Model-Free Counterfactual Credit Assignment
平均得分: 4.75
得分: ['5', '5', '6', '3']
论文链接: https://openreview.net/forum?id=F8xpAPm_ZKS
[185]. Plan-Based Asymptotically Equivalent Reward Shaping
平均得分: 4.75
得分: ['3', '5', '7', '4']
论文链接: https://openreview.net/forum?id=w2Z2OwVNeK
[186]. Design-Bench: Benchmarks for Data-Driven Offline Model-Based Optimization
平均得分: 4.75
得分: ['4', '3', '7', '5']
论文链接: https://openreview.net/forum?id=cQzf26aA3vM
[187]. Regioned Episodic Reinforcement Learning
平均得分: 4.75
得分: ['6', '4', '5', '4']
论文链接: https://openreview.net/forum?id=amRmtfpYgDt
[188]. Reinforcement Learning with Bayesian Classifiers: Efficient Skill Learning from Outcome Examples
平均得分: 4.75
得分: ['5', '4', '5', '5']
论文链接: https://openreview.net/forum?id=OZgVHzdKicb
[189]. Provably More Efficient Q-Learning in the One-Sided-Feedback/Full-Feedback Settings
平均得分: 4.75
得分: ['4', '4', '6', '5']
论文链接: https://openreview.net/forum?id=vY0bnzBBvtr
[190]. Systematic Evaluation of Causal Discovery in Visual Model Based Reinforcement Learning
平均得分: 4.75
得分: ['4', '6', '4', '5']
论文链接: https://openreview.net/forum?id=gp5Uzbl-9C-
[191]. Safe Reinforcement Learning with Natural Language Constraints
平均得分: 4.75
得分: ['5', '3', '5', '6']
论文链接: https://openreview.net/forum?id=Ua5yGJhfgAg
[192]. ReaPER: Improving Sample Efficiency in Model-Based Latent Imagination
平均得分: 4.75
得分: ['4', '5', '4', '6']
论文链接: https://openreview.net/forum?id=nlWgE3A-iS
[193]. Coordinated Multi-Agent Exploration Using Shared Goals
平均得分: 4.75
得分: ['4', '5', '5', '5']
论文链接: https://openreview.net/forum?id=MPO4oML_JC
[194]. Measuring and mitigating interference in reinforcement learning
平均得分: 4.75
得分: ['5', '6', '4', '4']
论文链接: https://openreview.net/forum?id=26WnoE4hjS
[195]. Hamiltonian Q-Learning: Leveraging Importance-sampling for Data Efficient RL
平均得分: 4.75
得分: ['5', '5', '5', '4']
论文链接: https://openreview.net/forum?id=10XWPuAro86
[196]. A Maximum Mutual Information Framework for Multi-Agent Reinforcement Learning
平均得分: 4.75
得分: ['3', '5', '6', '5']
论文链接: https://openreview.net/forum?id=_zHHAZOLTVh
[197]. Non-decreasing Quantile Function Network with Efficient Exploration for Distributional Reinforcement Learning
平均得分: 4.75
得分: ['4', '5', '4', '6']
论文链接: https://openreview.net/forum?id=f_GA2IU9-K-
[198]. Constrained Reinforcement Learning With Learned Constraints
平均得分: 4.75
得分: ['3', '3', '5', '8']
论文链接: https://openreview.net/forum?id=akgiLNAkC7P
[199]. Efficient Exploration for Model-based Reinforcement Learning with Continuous States and Actions
平均得分: 4.75
得分: ['5', '5', '4', '5']
论文链接: https://openreview.net/forum?id=asLT0W1w7Li
[200]. Error Controlled Actor-Critic Method to Reinforcement Learning
平均得分: 4.75
得分: ['7', '3', '3', '6']
论文链接: https://openreview.net/forum?id=n5yBuzpqqw
[201]. Cross-State Self-Constraint for Feature Generalization in Deep Reinforcement Learning
平均得分: 4.75
得分: ['5', '5', '4', '5']
论文链接: https://openreview.net/forum?id=JiNvAGORcMW
[202]. Safety Aware Reinforcement Learning (SARL)
平均得分: 4.75
得分: ['4', '6', '6', '3']
论文链接: https://openreview.net/forum?id=RDpTZpubOh7
[203]. UneVEn: Universal Value Exploration for Multi-Agent Reinforcement Learning
平均得分: 4.75
得分: ['4', '4', '6', '5']
论文链接: https://openreview.net/forum?id=0z1HScLBEpb
[204]. Interpretable Reinforcement Learning With Neural Symbolic Logic
平均得分: 4.67
得分: ['5', '4', '5']
论文链接: https://openreview.net/forum?id=M_gk45ItxIp
[205]. Network Reusability Analysis for Multi-Joint Robot Reinforcement Learning
平均得分: 4.67
得分: ['5', '4', '5']
论文链接: https://openreview.net/forum?id=hypDstHla7
[206]. Factored Action Spaces in Deep Reinforcement Learning
平均得分: 4.67
得分: ['6', '3', '5']
论文链接: https://openreview.net/forum?id=naSAkn2Xo46
[207]. Genetic Soft Updates for Policy Evolution in Deep Reinforcement Learning
平均得分: 4.67
得分: ['4', '6', '4']
论文链接: https://openreview.net/forum?id=TGFO0DbD_pk
[208]. The Skill-Action Architecture: Learning Abstract Action Embeddings for Reinforcement Learning
平均得分: 4.67
得分: ['5', '4', '5']
论文链接: https://openreview.net/forum?id=PU35uLgRZkk
[209]. Learning Intrinsic Symbolic Rewards in Reinforcement Learning
平均得分: 4.67
得分: ['5', '4', '5']
论文链接: https://openreview.net/forum?id=4CxsUBDQJqv
[210]. Robust Offline Reinforcement Learning from Low-Quality Data
平均得分: 4.6
得分: ['5', '4', '6', '6', '2']
论文链接: https://openreview.net/forum?id=uOjm_xqKEoX
[211]. Adaptive Learning Rates for Multi-Agent Reinforcement Learning
平均得分: 4.6
得分: ['5', '4', '4', '5', '5']
论文链接: https://openreview.net/forum?id=yN18f9V1Onp
[212]. Revisiting Parameter Sharing in Multi-Agent Deep Reinforcement Learning
平均得分: 4.5
得分: ['3', '3', '5', '7']
论文链接: https://openreview.net/forum?id=MWj_P-Lk3jC
[213]. Addressing Distribution Shift in Online Reinforcement Learning with Offline Datasets
平均得分: 4.5
得分: ['6', '5', '4', '3']
论文链接: https://openreview.net/forum?id=9hgEG-k57Zj
[214]. TOMA: Topological Map Abstraction for Reinforcement Learning
平均得分: 4.5
得分: ['4', '3', '5', '6']
论文链接: https://openreview.net/forum?id=yoem5ud2vb
[215]. Multi-agent Policy Optimization with Approximatively Synchronous Advantage Estimation
平均得分: 4.5
得分: ['5', '3', '6', '4']
论文链接: https://openreview.net/forum?id=Rw_vo-wIAa
[216]. Why Convolutional Networks Learn Oriented Bandpass Filters: Theory and Empirical Support
平均得分: 4.5
得分: ['6', '4', '5', '3']
论文链接: https://openreview.net/forum?id=UJRFjuJDsIO
[217]. Self-Activating Neural Ensembles for Continual Reinforcement Learning
平均得分: 4.5
得分: ['4', '4', '4', '6']
论文链接: https://openreview.net/forum?id=Jf24xdaAwF9
[218]. Approximating Pareto Frontier through Bayesian-optimization-directed Robust Multi-objective Reinforcement Learning
平均得分: 4.5
得分: ['5', '5', '5', '3']
论文链接: https://openreview.net/forum?id=S9MPX7ejmv
[219]. Model-Based Reinforcement Learning via Latent-Space Collocation
平均得分: 4.5
得分: ['3', '5', '6', '4']
论文链接: https://openreview.net/forum?id=ku4sJKvnbwV
[220]. CDT: Cascading Decision Trees for Explainable Reinforcement Learning
平均得分: 4.5
得分: ['4', '4', '5', '5']
论文链接: https://openreview.net/forum?id=WdOCkf4aCM
[221]. PGPS : Coupling Policy Gradient with Population-based Search
平均得分: 4.5
得分: ['5', '5', '3', '5']
论文链接: https://openreview.net/forum?id=PeT5p3ocagr
[222]. CAT-SAC: Soft Actor-Critic with Curiosity-Aware Entropy Temperature
平均得分: 4.5
得分: ['6', '4', '4', '4']
论文链接: https://openreview.net/forum?id=paE8yL0aKHo
[223]. Learning to Observe with Reinforcement Learning
平均得分: 4.5
得分: ['3', '6', '5', '4']
论文链接: https://openreview.net/forum?id=65sCF5wmhpv
[224]. Probabilistic Mixture-of-Experts for Efficient Deep Reinforcement Learning
平均得分: 4.5
得分: ['3', '6', '3', '6']
论文链接: https://openreview.net/forum?id=LtgEkhLScK3
[225]. Visual Imitation with Reinforcement Learning using Recurrent Siamese Networks
平均得分: 4.5
得分: ['4', '4', '4', '6']
论文链接: https://openreview.net/forum?id=MBdafA3G9k
[226]. Lyapunov Barrier Policy Optimization
平均得分: 4.5
得分: ['4', '6', '4', '4']
论文链接: https://openreview.net/forum?id=qUs18ed9oe
[227]. A Deeper Look at Discounting Mismatch in Actor-Critic Algorithms
平均得分: 4.5
得分: ['6', '4', '3', '5']
论文链接: https://openreview.net/forum?id=ypJS_nyu-I
[228]. Cross-Modal Domain Adaptation for Reinforcement Learning
平均得分: 4.5
得分: ['5', '4', '5', '4']
论文链接: https://openreview.net/forum?id=0owsv3F-fM
[229]. L2E: Learning to Exploit Your Opponent
平均得分: 4.5
得分: ['6', '4', '3', '5']
论文链接: https://openreview.net/forum?id=m4PC1eUknQG
[230]. MQES: Max-Q Entropy Search for Efficient Exploration in Continuous Reinforcement Learning
平均得分: 4.4
得分: ['4', '3', '5', '6', '4']
论文链接: https://openreview.net/forum?id=98ntbCuqf4i
[231]. Robust Multi-Agent Reinforcement Learning Driven by Correlated Equilibrium
平均得分: 4.4
得分: ['5', '4', '3', '6', '4']
论文链接: https://openreview.net/forum?id=JvPsKam58LX
[232]. R-LAtte: Attention Module for Visual Control via Reinforcement Learning
平均得分: 4.33
得分: ['4', '4', '5']
论文链接: https://openreview.net/forum?id=D4QFCXGe_z2
[233]. Multi-agent Deep FBSDE Representation For Large Scale Stochastic Differential Games
平均得分: 4.33
得分: ['5', '3', '5']
论文链接: https://openreview.net/forum?id=UoAFJMzCNM
[234]. Aspect-based Sentiment Classification via Reinforcement Learning
平均得分: 4.33
得分: ['5', '5', '3']
论文链接: https://openreview.net/forum?id=bfTUfrqL6d
[235]. Refine and Imitate: Reducing Repetition and Inconsistency in Dialogue Generation via Reinforcement Learning and Human Demonstration
平均得分: 4.33
得分: ['3', '6', '4']
论文链接: https://openreview.net/forum?id=JthLaV0RsV
[236]. An Examination of Preference-based Reinforcement Learning for Treatment Recommendation
平均得分: 4.33
得分: ['4', '4', '5']
论文链接: https://openreview.net/forum?id=uxYjVEXx48i
[237]. Adaptive Dataset Sampling by Deep Policy Gradient
平均得分: 4.33
得分: ['5', '3', '5']
论文链接: https://openreview.net/forum?id=t2C42s67gsQ
[238]. Convergence Proof for Actor-Critic Methods Applied to PPO and RUDDER
平均得分: 4.25
得分: ['5', '4', '4', '4']
论文链接: https://openreview.net/forum?id=0hMthVxlS89
[239]. Q-Value Weighted Regression: Reinforcement Learning with Limited Data
平均得分: 4.25
得分: ['4', '6', '3', '4']
论文链接: https://openreview.net/forum?id=rd_bm8CK7o0
[240]. ScheduleNet: Learn to Solve MinMax mTSP Using Reinforcement Learning with Delayed Reward
平均得分: 4.25
得分: ['5', '4', '3', '5']
论文链接: https://openreview.net/forum?id=P63SQE0fVa
[241]. Benchmarking Multi-Agent Deep Reinforcement Learning Algorithms
平均得分: 4.25
得分: ['4', '4', '3', '6']
论文链接: https://openreview.net/forum?id=t5lNr0Lw84H
[242]. Reinforcement Learning for Sparse-Reward Object-Interaction Tasks in First-person Simulated 3D Environments
平均得分: 4.25
得分: ['3', '4', '4', '6']
论文链接: https://openreview.net/forum?id=7AQUzh5ntX_
[243]. Model-Free Energy Distance for Pruning DNNs
平均得分: 4.25
得分: ['5', '2', '5', '5']
论文链接: https://openreview.net/forum?id=k2TyMLwuikx
[244]. D4RL: Datasets for Deep Data-Driven Reinforcement Learning
平均得分: 4.25
得分: ['2', '3', '6', '6']
论文链接: https://openreview.net/forum?id=px0-N3_KjA
[245]. Exploring Transferability of Perturbations in Deep Reinforcement Learning
平均得分: 4.25
得分: ['3', '4', '6', '4']
论文链接: https://openreview.net/forum?id=inBTt_wSv0
[246]. Alpha-DAG: a reinforcement learning based algorithm to learn Directed Acyclic Graphs
平均得分: 4.25
得分: ['4', '5', '4', '4']
论文链接: https://openreview.net/forum?id=0jqRSnFnmL_
[247]. Visual Explanation using Attention Mechanism in Actor-Critic-based Deep Reinforcement Learning
平均得分: 4.25
得分: ['5', '5', '4', '3']
论文链接: https://openreview.net/forum?id=Y0MgRifqikY
[248]. Knapsack Pruning with Inner Distillation
平均得分: 4.25
得分: ['4', '4', '5', '4']
论文链接: https://openreview.net/forum?id=O9NAKC_MqMx
[249]. Reinforcement Learning for Flexibility Design Problems
平均得分: 4.25
得分: ['5', '4', '4', '4']
论文链接: https://openreview.net/forum?id=oAkujcqxJzW
[250]. Model-based Navigation in Environments with Novel Layouts Using Abstract 2
-D Maps
平均得分: 4.25
得分: ['6', '4', '4', '3']
论文链接: https://openreview.net/forum?id=_lV1OrJIgiG
[251]. Model-Based Robust Deep Learning: Generalizing to Natural, Out-of-Distribution Data
平均得分: 4.25
得分: ['5', '5', '4', '3']
论文链接: https://openreview.net/forum?id=RgDq8-AwvtN
[252]. Structure and randomness in planning and reinforcement learning
平均得分: 4.2
得分: ['5', '3', '6', '3', '4']
论文链接: https://openreview.net/forum?id=UOOmHiXetC
[253]. Trust, but verify: model-based exploration in sparse reward environments
平均得分: 4
得分: ['4', '2', '6', '4']
论文链接: https://openreview.net/forum?id=DE0MSwKv32y
[254]. Play to Grade: Grading Interactive Coding Games as Classifying Markov Decision Process
平均得分: 4
得分: ['4', '3', '5']
论文链接: https://openreview.net/forum?id=GJkTaYTmzVS
[255]. Graph Convolutional Value Decomposition in Multi-Agent Reinforcement Learning
平均得分: 4
得分: ['5', '3', '4', '4']
论文链接: https://openreview.net/forum?id=gDikr8MVsMF
[256]. Regret Bounds and Reinforcement Learning Exploration of EXP-based Algorithms
平均得分: 4
得分: ['4', '4', '4']
论文链接: https://openreview.net/forum?id=-5W5OBfFlwX
[257]. MDP Playground: Controlling Dimensions of Hardness in Reinforcement Learning
平均得分: 4
得分: ['4', '3', '4', '5']
论文链接: https://openreview.net/forum?id=axNDkxU9-6z
[258]. Intrinsically Guided Exploration in Meta Reinforcement Learning
平均得分: 4
得分: ['4', '4', '4', '4']
论文链接: https://openreview.net/forum?id=RwQZd8znR10
[259]. Adaptive N-step Bootstrapping with Off-policy Data
平均得分: 4
得分: ['4', '4', '3', '5']
论文链接: https://openreview.net/forum?id=bhngY7lHu_
[260]. FORK: A FORward-looKing Actor for Model-Free Reinforcement Learning
平均得分: 4
得分: ['5', '3', '5', '3']
论文链接: https://openreview.net/forum?id=lXW6Sk1075v
[261]. Measuring Progress in Deep Reinforcement Learning Sample Efficiency
平均得分: 4
得分: ['4', '5', '5', '2']
论文链接: https://openreview.net/forum?id=_QdvdkxOii6
[262]. Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
平均得分: 4
得分: ['6', '3', '4', '3']
论文链接: https://openreview.net/forum?id=ToWi1RjuEr8
[263]. Joint State-Action Embedding for Efficient Reinforcement Learning
平均得分: 3.8
得分: ['5', '1', '4', '3', '6']
论文链接: https://openreview.net/forum?id=5USOVm2HkfG
[264]. Deep Reinforcement Learning for Optimal Stopping with Application in Financial Engineering
平均得分: 3.75
得分: ['2', '4', '4', '5']
论文链接: https://openreview.net/forum?id=REKvFYIgwz9
[265]. Playing Atari with Capsule Networks: A systematic comparison of CNN and CapsNets-based agents.
平均得分: 3.75
得分: ['2', '4', '5', '4']
论文链接: https://openreview.net/forum?id=GeOIKynj_V
[266]. Robust Constrained Reinforcement Learning for Continuous Control with Model Misspecification
平均得分: 3.75
得分: ['4', '3', '3', '5']
论文链接: https://openreview.net/forum?id=e-ZdxsIwweR
[267]. Decorrelated Double Q-learning
平均得分: 3.75
得分: ['4', '3', '5', '3']
论文链接: https://openreview.net/forum?id=jcN7a3yZeQc
[268]. Learning to Dynamically Select Between Reward Shaping Signals
平均得分: 3.75
得分: ['5', '2', '4', '4']
论文链接: https://openreview.net/forum?id=NrN8XarA2Iz
[269]. Empirically Verifying Hypotheses Using Reinforcement Learning
平均得分: 3.75
得分: ['3', '3', '5', '4']
论文链接: https://openreview.net/forum?id=XbJiphOWXiU
[270]. Self-Supervised Continuous Control without Policy Gradient
平均得分: 3.75
得分: ['3', '4', '4', '4']
论文链接: https://openreview.net/forum?id=pNDvPXd1qUk
[271]. Dynamic Relational Inference in Multi-Agent Trajectories
平均得分: 3.75
得分: ['2', '4', '5', '4']
论文链接: https://openreview.net/forum?id=UV9kN3S4uTZ
[272]. Greedy Multi-Step Off-Policy Reinforcement Learning
平均得分: 3.75
得分: ['2', '4', '4', '5']
论文链接: https://openreview.net/forum?id=rAIkhjUK0Tx
[273]. Addressing Extrapolation Error in Deep Offline Reinforcement Learning
平均得分: 3.67
得分: ['3', '4', '4']
论文链接: https://openreview.net/forum?id=OCRKCul3eKN
[274]. Offline Policy Optimization with Variance Regularization
平均得分: 3.67
得分: ['3', '4', '4']
论文链接: https://openreview.net/forum?id=P3WG6p6Jnb
[275]. Fine-Tuning Offline Reinforcement Learning with Model-Based Policy Optimization
平均得分: 3.6
得分: ['3', '4', '4', '5', '2']
论文链接: https://openreview.net/forum?id=wiSgdeJ29ee
[276]. Learning to communicate through imagination with model-based deep multi-agent reinforcement learning
平均得分: 3.5
得分: ['3', '4', '4', '3']
论文链接: https://openreview.net/forum?id=boZj4g3Jocj
[277]. A Robust Fuel Optimization Strategy For Hybrid Electric Vehicles: A Deep Reinforcement Learning Based Continuous Time Design Approach
平均得分: 3.5
得分: ['3', '5', '4', '2']
论文链接: https://openreview.net/forum?id=LFs3CnHwfM
[278]. Deep Reinforcement Learning With Adaptive Combined Critics
平均得分: 3.5
得分: ['3', '3', '5', '3']
论文链接: https://openreview.net/forum?id=gtwVBChN8td
[279]. FSV: Learning to Factorize Soft Value Function for Cooperative Multi-Agent Reinforcement Learning
平均得分: 3.4
得分: ['2', '6', '2', '3', '4']
论文链接: https://openreview.net/forum?id=ijVgDcvLmZ
[280]. Success-Rate Targeted Reinforcement Learning by Disorientation Penalty
平均得分: 3.25
得分: ['2', '3', '4', '4']
论文链接: https://openreview.net/forum?id=rQYyXqHPgZR
[281]. Explainable Reinforcement Learning Through Goal-Based Explanations
平均得分: 3.25
得分: ['3', '3', '4', '3']
论文链接: https://openreview.net/forum?id=IlJbTsygaI6
[282]. Hierarchical Meta Reinforcement Learning for Multi-Task Environments
平均得分: 3.25
得分: ['3', '3', '4', '3']
论文链接: https://openreview.net/forum?id=u9ax42K7ND
[283]. Interpretable Meta-Reinforcement Learning with Actor-Critic Method
平均得分: 3.2
得分: ['4', '3', '4', '2', '3']
论文链接: https://openreview.net/forum?id=-RQVWPX73VP
[284]. Reinforcement Learning Based Asymmetrical DNN Modularization for Optimal Loading
平均得分: 3
得分: ['3', '2', '3', '4']
论文链接: https://openreview.net/forum?id=_qJXkf347k
[285]. Stochastic Inverse Reinforcement Learning
平均得分: 2.8
得分: ['2', '2', '4', '3', '3']
论文链接: https://openreview.net/forum?id=l3gNU1KStIC
[286]. Using Deep Reinforcement Learning to Train and Evaluate Instructional Sequencing Policies for an Intelligent Tutoring System
平均得分: 2.67
得分: ['2', '4', '2']
论文链接: https://openreview.net/forum?id=eIPsmKwTrIe
[287]. Guiding Representation Learning in Deep Generative Models with Policy Gradients
平均得分: 2.5
得分: ['2', '4', '3', '1']
论文链接: https://openreview.net/forum?id=sgNhTKrZjaT
转自:https://cloud.tencent.com/developer/article/1749804
https://cloud.tencent.com/developer/column/80749
:Feng Dieqiao、Gomes Carla P.、Selman Bart
简介:· The authors presented a framework based on deep RL for solving hard combinatorial planning problems in the domain of Sokoban.· The authors showed the effectiveness of the learning based planning strategy by solving hard Sokoban instances that are out of reach of previous search-based solution techniques, including methods specialized for Sokoban.· Since Sokoban is one of the hardest challenge domains for current AI planners, this work shows the potential of curriculumbased deep RL for solving hard AI planning tasks.
5. 论文名称:I4R: Promoting Deep Reinforcement Learning by the Indicator for Expressive Representations
论文链接:https://www.aminer.cn/pub/5ef96b048806af6ef2772128/i-r-promoting-deep-reinforcement-learning-by-the-indicator-for-expressive-representations?conf=ijcai2020
作者:Xufang Luo、Qi Meng、Di He、Wei Chen、Yunhong Wang
简介:· The authors mainly study the relationship between representations and performance of the DRL agents.· The authors define the NSSV indicator, i.e, the smallest number of significant singular values, as a measurement for learning representations, the authors verify the positive correlation between NSSV and the rewards, and further propose a novel method called I4R, to improve DRL algorthims via adding the corresponding regularization term to enhance NSSV.· The authors show the proposed method I4R based on exploratory experiments, including 3 parts, i.e., observations, the proposed indicator NSSV, and the novel algorithm I4R.
6. 论文名称:Rebalancing Expanding EV Sharing Systems with Deep Reinforcement Learning
论文链接:https://www.aminer.cn/pub/5ef96b048806af6ef2772092/rebalancing-expanding-ev-sharing-systems-with-deep-reinforcement-learning?conf=ijcai2020
作者:Man Luo、Wenzhe Zhang、Tianyou Song、Kun Li、Hongming Zhu、Bowen Du 、Hongkai Wen
简介:· The authors study the incentive-based rebalancing for continuous expanding EV sharing systems.· The authors design a simulator to simulate the operation of EV sharing systems, which is calibrated with real data from an actual EV sharing system for a year.· Extensive experiments have shown that the proposed approach significantly outperforms the baselines and state-of-the-art in both satisfied demand rate and net revenue, and is robust to different levels of system expansion dynamics.· The authors show that the proposed approach performs consistently with different charging time and EV range.
7. 论文名称:Independent Skill Transfer for Deep Reinforcement Learning
论文链接:https://www.aminer.cn/pub/5ef96b048806af6ef2772129/independent-skill-transfer-for-deep-reinforcement-learning?conf=ijcai2020
作者:Qiangxing Tian、Guanchu Wang、Jinxin Liu、Donglin Wang、Yachen Kang
简介:· Deep reinforcement learning (DRL) has wide applications in various challenging fields, such as real-world visual navigation [Zhu et al, 2017], playing games [Silver et al, 2016] and robotic controls [Schulman et al, 2015]· In this work , the authors propose to learn independent skills for efficient skill transfer, where the learned primitive skills with strong correlation are decomposed into independent skills· We take the eigenvalues in Figure 1 as an example: for the case of 6 primitive skills, |Z| = 3 is reasonable since more than 98% component of primitive actions can be represented by three independent components· Effective observation collection and independent skills guarantee the success of low-dimension skill transfer
[1]. What Matters for On-Policy Deep Actor-Critic Methods? A Large-Scale Study
论文链接: https://openreview.net/forum?id=nIAxjsniDzg
[2]. Invariant Representations for Reinforcement Learning without Reconstruction
论文链接: https://openreview.net/forum?id=-2FCwDKRREu
[3]. Winning the L2RPN Challenge: Power Grid Management via Semi-Markov Afterstate Actor-Critic
论文链接: https://openreview.net/forum?id=LmUJqB1Cz8
[4]. Deep symbolic regression: Recovering mathematical expressions from data via risk-seeking policy gradients
论文链接: https://openreview.net/forum?id=m5Qsh0kBQG
[5]. Parrot: Data-Driven Behavioral Priors for Reinforcement Learning
论文链接: https://openreview.net/forum?id=Ysuv-WOFeKR
[6]. Evolving Reinforcement Learning Algorithms
论文链接: https://openreview.net/forum?id=0XXpJ4OtjW
[7]. Global optimality of softmax policy gradient with single hidden layer neural networks in the mean-field regime
论文链接: https://openreview.net/forum?id=bB2drc7DPuB
[8]. Single-Timescale Actor-Critic Provably Finds Globally Optimal Policy
论文链接: https://openreview.net/forum?id=pqZV_srUVmK
[9]. UPDeT: Universal Multi-agent RL via Policy Decoupling with Transformers
论文链接: https://openreview.net/forum?id=v9c7hr9ADKx
[10]. Regularized Inverse Reinforcement Learning
论文链接: https://openreview.net/forum?id=HgLO8yalfwc
[11]. Randomized Ensembled Double Q-Learning: Learning Fast Without a Model
>
论文链接: https://openreview.net/forum?id=AY8zfZm0tDd
[12]. Deployment-Efficient Reinforcement Learning via Model-Based Offline Optimization
论文链接: https://openreview.net/forum?id=3hGNqpI4WS
[13]. Image Augmentation Is All You Need: Regularizing Deep Reinforcement Learning from Pixels
论文链接: https://openreview.net/forum?id=GY6-6sTvGaf
[14]. Support-set bottlenecks for video-text representation learning
论文链接: https://openreview.net/forum?id=EqoXe2zmhrh
[15]. A Sharp Analysis of Model-based Reinforcement Learning with Self-Play
论文链接: https://openreview.net/forum?id=9Y7_c5ZAd5i
[16]. RODE: Learning Roles to Decompose Multi-Agent Tasks
论文链接: https://openreview.net/forum?id=TTUVg6vkNjK
[17]. Text Generation by Learning from Off-Policy Demonstrations
论文链接: https://openreview.net/forum?id=RovX-uQ1Hua
[18]. Robust Reinforcement Learning on State Observations with Learned Optimal Adversary
论文链接: https://openreview.net/forum?id=sCZbhBvqQaU
[19]. Self-supervised Visual Reinforcement Learning with Object-centric Representations
论文链接: https://openreview.net/forum?id=xppLmXCbOw1
[20]. On Effective Parallelization of Monte Carlo Tree Search
论文链接: https://openreview.net/forum?id=_FXqMj7T0QQ
[21]. Non-asymptotic Confidence Intervals of Off-policy Evaluation: Primal and Dual Bounds
论文链接: https://openreview.net/forum?id=dKg5D1Z1Lm
[22]. Efficient Transformers in Reinforcement Learning using Actor-Learner Distillation
论文链接: https://openreview.net/forum?id=uR9LaO_QxF
[23]. Ask Your Humans: Using Human Instructions to Improve Generalization in Reinforcement Learning
论文链接: https://openreview.net/forum?id=Y87Ri-GNHYu
[24]. SMiRL: Surprise Minimizing Reinforcement Learning in Unstable Environments
论文链接: https://openreview.net/forum?id=cPZOyoDloxl
[25]. Model-Based Visual Planning with Self-Supervised Functional Distances
论文链接: https://openreview.net/forum?id=UcoXdfrORC
[26]. Learning-based Support Estimation in Sublinear Time
论文链接: https://openreview.net/forum?id=tilovEHA3YS
[27]. DOP: Off-Policy Multi-Agent Decomposed Policy Gradients
论文链接: https://openreview.net/forum?id=6FqKiVAdI3Y
[28]. Correcting experience replay for multi-agent communication
论文链接: https://openreview.net/forum?id=xvxPuCkCNPO
[29]. Risk-Averse Offline Reinforcement Learning
论文链接: https://openreview.net/forum?id=TBIzh9b5eaz
[30]. Learning Value Functions in Deep Policy Gradients using Residual Variance
论文链接: https://openreview.net/forum?id=NX1He-aFO_F
[31]. Contrastive Explanations for Reinforcement Learning via Embedded Self Predictions
论文链接: https://openreview.net/forum?id=Ud3DSz72nYR
[32]. PODS: Policy Optimization via Differentiable Simulation
论文链接: https://openreview.net/forum?id=4f04RAhMUo6
[33]. Transient Non-stationarity and Generalisation in Deep Reinforcement Learning
论文链接: https://openreview.net/forum?id=Qun8fv4qSby
[34]. Improving Learning to Branch via Reinforcement Learning
论文链接: https://openreview.net/forum?id=M_KwRsbhi5e
[35]. Mastering Atari with Discrete World Models
论文链接: https://openreview.net/forum?id=0oabwyZbOu
[36]. Data-Efficient Reinforcement Learning with Self-Predictive Representations
论文链接: https://openreview.net/forum?id=uCQfPZwRaUu
[37]. Local Information Opponent Modelling Using Variational Autoencoders
论文链接: https://openreview.net/forum?id=xF5r3dVeaEl
[38]. Contrastive Behavioral Similarity Embeddings for Generalization in Reinforcement Learning
论文链接: https://openreview.net/forum?id=qda7-sVg84
[39]. Efficient Reinforcement Learning in Factored MDPs with Application to Constrained RL
论文链接: https://openreview.net/forum?id=fmtSg8591Q
[40]. Batch Reinforcement Learning Through Continuation Method
论文链接: https://openreview.net/forum?id=po-DLlBuAuz
[41]. Optimistic Exploration with Backward Bootstrapped Bonus for Deep Reinforcement Learning
论文链接: https://openreview.net/forum?id=QxQkG-gIKJM
[42]. Optimism in Reinforcement Learning with Generalized Linear Function Approximation
论文链接: https://openreview.net/forum?id=CBmJwzneppz
[43]. Adversarially Guided Actor-Critic
论文链接: https://openreview.net/forum?id=_mQp5cr_iNy
[44]. QTRAN++: Improved Value Transformation for Cooperative Multi-Agent Reinforcement Learning
论文链接: https://openreview.net/forum?id=TlS3LBoDj3Z
[45]. Policy Optimization in Zero-Sum Markov Games: Fictitious Self-Play Provably Attains Nash Equilibria
论文链接: https://openreview.net/forum?id=c3MWGN_cTf
[46]. Optimistic Policy Optimization with General Function Approximations
论文链接: https://openreview.net/forum?id=JydXRRDoDTv
[47]. Multi-Agent Collaboration via Reward Attribution Decomposition
论文链接: https://openreview.net/forum?id=GVNGAaY2Dr1
[48]. Efficient Wasserstein Natural Gradients for Reinforcement Learning
论文链接: https://openreview.net/forum?id=OHgnfSrn2jv
[49]. Density Constrained Reinforcement Learning
论文链接: https://openreview.net/forum?id=jMc7DlflrMC
[50]. Representation Balancing Offline Model-based Reinforcement Learning
论文链接: https://openreview.net/forum?id=QpNz8r_Ri2Y
[51]. Decoupling Representation Learning from Reinforcement Learning
论文链接: https://openreview.net/forum?id=_SKUm2AJpvN
[52]. Model-based micro-data reinforcement learning: what are the crucial model properties and which model to choose?
论文链接: https://openreview.net/forum?id=p5uylG94S68
[53]. Model-based Asynchronous Hyperparameter and Neural Architecture Search
论文链接: https://openreview.net/forum?id=a2rFihIU7i
[54]. DeepAveragers: Offline Reinforcement Learning By Solving Derived Non-Parametric MDPs
论文链接: https://openreview.net/forum?id=eMP1j9efXtX
[55]. Uncertainty Weighted Offline Reinforcement Learning
论文链接: https://openreview.net/forum?id=7hMenh--8g
[56]. Optimizing Memory Placement using Evolutionary Graph Reinforcement Learning
论文链接: https://openreview.net/forum?id=-6vS_4Kfz0
[57]. Parameter-based Value Functions
论文链接: https://openreview.net/forum?id=tV6oBfuyLTQ
[58]. Sample-Efficient Automated Deep Reinforcement Learning
论文链接: https://openreview.net/forum?id=hSjxQ3B7GWq
[59]. Causal Inference Q-Network: Toward Resilient Reinforcement Learning
论文链接: https://openreview.net/forum?id=PvVbsAmxdlZ
[60]. SACoD: Sensor Algorithm Co-Design Towards Efficient CNN-powered Intelligent PhlatCam
论文链接: https://openreview.net/forum?id=jQUf0TmN-oT
[61]. Learn Goal-Conditioned Policy with Intrinsic Motivation for Deep Reinforcement Learning
论文链接: https://openreview.net/forum?id=MmcywoW7PbJ
[62]. Benchmarks for Deep Off-Policy Evaluation
论文链接: https://openreview.net/forum?id=kWSeGEeHvF8
[63]. Shortest-Path Constrained Reinforcement Learning for Sparse Reward Tasks
论文链接: https://openreview.net/forum?id=Y-Wl1l0Va-
[64]. Exploring Zero-Shot Emergent Communication in Embodied Multi-Agent Populations
论文链接: https://openreview.net/forum?id=Fblk4_Fd7ao
[65]. Randomized Entity-wise Factorization for Multi-Agent Reinforcement Learning
论文链接: https://openreview.net/forum?id=szUsQ3NcQwV
[66]. Learning Robust State Abstractions for Hidden-Parameter Block MDPs
论文链接: https://openreview.net/forum?id=fmOOI2a3tQP
[67]. Adapting to Reward Progressivity via Spectral Reinforcement Learning
论文链接: https://openreview.net/forum?id=dyjPVUc2KB
[68]. Accelerating Safe Reinforcement Learning with Constraint-mismatched Policies
论文链接: https://openreview.net/forum?id=M3NDrHEGyyO
[69]. Off-Dynamics Reinforcement Learning: Training for Transfer with Domain Classifiers
论文链接: https://openreview.net/forum?id=eqBwg3AcIAK
[70]. Meta-Reinforcement Learning With Informed Policy Regularization
论文链接: https://openreview.net/forum?id=pTZ6EgZtzDU
[71]. Hierarchical Reinforcement Learning by Discovering Intrinsic Options
论文链接: https://openreview.net/forum?id=r-gPPHEjpmw
[72]. Multi-Agent Trust Region Learning
论文链接: https://openreview.net/forum?id=eHG7asK_v-k
[73]. Unity of Opposites: SelfNorm and CrossNorm for Model Robustness
论文链接: https://openreview.net/forum?id=Oj2hGyJwhwX
[74]. The Advantage Regret-Matching Actor-Critic
论文链接: https://openreview.net/forum?id=YMsbeG6FqBU
[75]. Differentiable Trust Region Layers for Deep Reinforcement Learning
论文链接: https://openreview.net/forum?id=qYZD-AO1Vn
[76]. Linear Representation Meta-Reinforcement Learning for Instant Adaptation
论文链接: https://openreview.net/forum?id=lNrtNGkr-vw
[77]. Symmetry-Aware Actor-Critic for 3D Molecular Design
论文链接: https://openreview.net/forum?id=jEYKjPE1xYN
[78]. The Importance of Pessimism in Fixed-Dataset Policy Optimization
论文链接: https://openreview.net/forum?id=E3Ys6a1NTGT
[79]. Understanding and Leveraging Causal Relations in Deep Reinforcement Learning
论文链接: https://openreview.net/forum?id=30I4Azqc_oP
[80]. Efficient Fully-Offline Meta-Reinforcement Learning via Distance Metric Learning and Behavior Regularization
论文链接: https://openreview.net/forum?id=8cpHIfgY4Dj
[81]. Grounding Language to Entities for Generalization in Reinforcement Learning
论文链接: https://openreview.net/forum?id=udbMZR1cKE6
[82]. Large Batch Simulation for Deep Reinforcement Learning
论文链接: https://openreview.net/forum?id=cP5IcoAkfKa
[83]. Deep Reinforcement Learning For Wireless Scheduling with Multiclass Services
论文链接: https://openreview.net/forum?id=UiLl8yjh57
[84]. Monotonic Robust Policy Optimization with Model Discrepancy
论文链接: https://openreview.net/forum?id=kdm4Lm9rgB
[85]. Truly Deterministic Policy Optimization
论文链接: https://openreview.net/forum?id=BntruCi1uvF
[86]. Distributional Reinforcement Learning for Risk-Sensitive Policies
论文链接: https://openreview.net/forum?id=19drPzGV691
[87]. Bounded Myopic Adversaries for Deep Reinforcement Learning Agents
论文链接: https://openreview.net/forum?id=Ew0zR07CYRd
[88]. Decoupling Exploration and Exploitation for Meta-Reinforcement Learning without Sacrifices
论文链接: https://openreview.net/forum?id=rSwTMomgCz
[89]. Discovering Diverse Multi-Agent Strategic Behavior via Reward Randomization
论文链接: https://openreview.net/forum?id=lvRTC669EY_
[90]. Blending MPC & Value Function Approximation for Efficient Reinforcement Learning
论文链接: https://openreview.net/forum?id=RqCC_00Bg7V
[91]. A Policy Gradient Algorithm for Learning to Learn in Multiagent Reinforcement Learning
论文链接: https://openreview.net/forum?id=zdrls6LIX4W
[92]. The act of remembering: A study in partially observable reinforcement learning
论文链接: https://openreview.net/forum?id=uFkGzn9RId8
[93]. Random Coordinate Langevin Monte Carlo
论文链接: https://openreview.net/forum?id=lbc44k2jgnX
[94]. Provable Rich Observation Reinforcement Learning with Combinatorial Latent States
论文链接: https://openreview.net/forum?id=hx1IXFHAw7R
[95]. Automatic Data Augmentation for Generalization in Reinforcement Learning
论文链接: https://openreview.net/forum?id=9l9WD4ahJgs
[96]. Reinforcement Learning with Random Delays
论文链接: https://openreview.net/forum?id=QFYnKlBJYR
[97]. On Proximal Policy Optimization's Heavy-Tailed Gradients
论文链接: https://openreview.net/forum?id=cYek5NoXNiX
[98]. A Primal Approach to Constrained Policy Optimization: Global Optimality and Finite-Time Analysis
论文链接: https://openreview.net/forum?id=rI3RMgDkZqJ
[99]. Regularization Matters in Policy Optimization - An Empirical Study on Continuous Control
论文链接: https://openreview.net/forum?id=yr1mzrH3IC
[100]. Divide-and-Conquer Monte Carlo Tree Search
论文链接: https://openreview.net/forum?id=Nj8EIrSu5O
[101]. Status-Quo Policy Gradient in Multi-agent Reinforcement Learning
论文链接: https://openreview.net/forum?id=76M3pxkqRl
[102]. QPLEX: Duplex Dueling Multi-Agent Q-Learning
论文链接: https://openreview.net/forum?id=Rcmk0xxIQV
[103]. A Reduction Approach to Constrained Reinforcement Learning
论文链接: https://openreview.net/forum?id=fV4vvs1J5iM
[104]. Compute- and Memory-Efficient Reinforcement Learning with Latent Experience Replay
论文链接: https://openreview.net/forum?id=J7bUsLCb0zf
[105]. On Trade-offs of Image Prediction in Visual Model-Based Reinforcement Learning
论文链接: https://openreview.net/forum?id=mewtfP6YZ7
[106]. Towards Understanding Linear Value Decomposition in Cooperative Multi-Agent Q-Learning
论文链接: https://openreview.net/forum?id=VMtftZqMruq
[107]. Average Reward Reinforcement Learning with Monotonic Policy Improvement
论文链接: https://openreview.net/forum?id=lo7GKwmakFZ
[108]. FactoredRL: Leveraging Factored Graphs for Deep Reinforcement Learning
论文链接: https://openreview.net/forum?id=wE-3ly4eT5G
[109]. Implicit Under-Parameterization Inhibits Data-Efficient Deep Reinforcement Learning
论文链接: https://openreview.net/forum?id=O9bnihsFfXU
[110]. Scalable Bayesian Inverse Reinforcement Learning by Auto-Encoding Reward
论文链接: https://openreview.net/forum?id=4qR3coiNaIv
[111]. Model-Based Offline Planning
论文链接: https://openreview.net/forum?id=OMNB1G5xzd4
[112]. BRAC+: Going Deeper with Behavior Regularized Offline Reinforcement Learning
论文链接: https://openreview.net/forum?id=bMCfFepJXM
[113]. Learning to Share in Multi-Agent Reinforcement Learning
论文链接: https://openreview.net/forum?id=awnQ2qTLSwn
[114]. Explicit Pareto Front Optimization for Constrained Reinforcement Learning
论文链接: https://openreview.net/forum?id=pOHW7EwFbo9
[115]. Guided Exploration with Proximal Policy Optimization using a Single Demonstration
论文链接: https://openreview.net/forum?id=88_MfcJoJlS
[116]. Unsupervised Active Pre-Training for Reinforcement Learning
论文链接: https://openreview.net/forum?id=cvNYovr16SB
[117]. RECONNAISSANCE FOR REINFORCEMENT LEARNING WITH SAFETY CONSTRAINTS
论文链接: https://openreview.net/forum?id=Gc4MQq-JIgj
[118]. Daylight: Assessing Generalization Skills of Deep Reinforcement Learning Agents
论文链接: https://openreview.net/forum?id=Z3XVHSbSawb
[119]. Diversity Actor-Critic: Sample-Aware Entropy Regularization for Sample-Efficient Exploration
论文链接: https://openreview.net/forum?id=7qmQNB6Wn_B
[120]. OPAL: Offline Primitive Discovery for Accelerating Offline Reinforcement Learning
论文链接: https://openreview.net/forum?id=V69LGwJ0lIN
[121]. A REINFORCEMENT LEARNING FRAMEWORK FOR TIME DEPENDENT CAUSAL EFFECTS EVALUATION IN A/B TESTING
论文链接: https://openreview.net/forum?id=Dtahsj2FkrK
[122]. PettingZoo: Gym for Multi-Agent Reinforcement Learning
论文链接: https://openreview.net/forum?id=WoLQsYU8aZ
[123]. Hippocampal representations emerge when training recurrent neural networks on a memory dependent maze navigation task
论文链接: https://openreview.net/forum?id=Jr8XGtK04Pw
[124]. Data-efficient Hindsight Off-policy Option Learning
论文链接: https://openreview.net/forum?id=QKbS9KXkE_y
[125]. Attacking Few-Shot Classifiers with Adversarial Support Sets
论文链接: https://openreview.net/forum?id=0xdQXkz69x9
[126]. Coverage as a Principle for Discovering Transferable Behavior in Reinforcement Learning
论文链接: https://openreview.net/forum?id=INhwJdJtxn6
[127]. Reinforcement Learning for Control with Probabilistic Stability Guarantee
论文链接: https://openreview.net/forum?id=QfEssgaXpm
[128]. Efficient Reinforcement Learning in Resource Allocation Problems Through Permutation Invariant Multi-task Learning
论文链接: https://openreview.net/forum?id=TiGF63rxr8Q
[129]. Meta-Reinforcement Learning Robust to Distributional Shift via Model Identification and Experience Relabeling
论文链接: https://openreview.net/forum?id=AT7jak63NNK
[130]. Solving Compositional Reinforcement Learning Problems via Task Reduction
论文链接: https://openreview.net/forum?id=9SS69KwomAM
[131]. Emergent Road Rules In Multi-Agent Driving Environments
论文链接: https://openreview.net/forum?id=d8Q1mt2Ghw
[132]. EMaQ: Expected-Max Q-Learning Operator for Simple Yet Effective Offline and Online RL
论文链接: https://openreview.net/forum?id=B8fp0LVMHa
[133]. Double Q-learning: New Analysis and Sharper Finite-time Bound
论文链接: https://openreview.net/forum?id=MwxaStJXK6v
[134]. Safety Verification of Model Based Reinforcement Learning Controllers
论文链接: https://openreview.net/forum?id=mfJepDyIUcQ
[135]. D3C: Reducing the Price of Anarchy in Multi-Agent Learning
论文链接: https://openreview.net/forum?id=8wa7HrUsElL
[136]. Near-Optimal Regret Bounds for Model-Free RL in Non-Stationary Episodic MDPs
论文链接: https://openreview.net/forum?id=TJzkxFw-mGm
[137]. Communication in Multi-Agent Reinforcement Learning: Intention Sharing
论文链接: https://openreview.net/forum?id=qpsl2dR9twy
[138]. On the role of planning in model-based deep reinforcement learning
论文链接: https://openreview.net/forum?id=IrM64DGB21
[139]. Reinforcement Learning with Latent Flow
论文链接: https://openreview.net/forum?id=lSijhyKKsct
[140]. Iterative Amortized Policy Optimization
论文链接: https://openreview.net/forum?id=49mMdsxkPlD
[141]. Unsupervised Task Clustering for Multi-Task Reinforcement Learning
论文链接: https://openreview.net/forum?id=4K_NaDAHc0d
[142]. Adaptive Multi-model Fusion Learning for Sparse-Reward Reinforcement Learning
论文链接: https://openreview.net/forum?id=4emQEegFhSy
[143]. ERMAS: Learning Policies Robust to Reality Gaps in Multi-Agent Simulations
论文链接: https://openreview.net/forum?id=uIc4W6MtbDA
[144]. A Distributional Perspective on Actor-Critic Framework
论文链接: https://openreview.net/forum?id=jWXBUsWP7N
[145]. Robust Reinforcement Learning using Adversarial Populations
论文链接: https://openreview.net/forum?id=I6NRcao1w-X
[146]. The Compact Support Neural Network
论文链接: https://openreview.net/forum?id=xCy9thPPTb_
[147]. RMIX: Risk-Sensitive Multi-Agent Reinforcement Learning
论文链接: https://openreview.net/forum?id=1EVb8XRBDNr
[148]. Meta-Model-Based Meta-Policy Optimization
论文链接: https://openreview.net/forum?id=KOtxfjpQsq
[149]. Decentralized Deterministic Multi-Agent Reinforcement Learning
论文链接: https://openreview.net/forum?id=QM4_h99pjCE
[150]. Transfer among Agents: An Efficient Multiagent Transfer Learning Framework
论文链接: https://openreview.net/forum?id=9w03rTs7w5
[151]. Gradient-based tuning of Hamiltonian Monte Carlo hyperparameters
论文链接: https://openreview.net/forum?id=LvJ8hLSusrv
[152]. Combining Imitation and Reinforcement Learning with Free Energy Principle
论文链接: https://openreview.net/forum?id=JI2TGOehNT0
[153]. Ordering-Based Causal Discovery with Reinforcement Learning
论文链接: https://openreview.net/forum?id=bMzj6hXL2VJ
[154]. Universal Value Density Estimation for Imitation Learning and Goal-Conditioned Reinforcement Learning
论文链接: https://openreview.net/forum?id=S2UB9PkrEjF
[155]. The Emergence of Individuality in Multi-Agent Reinforcement Learning
论文链接: https://openreview.net/forum?id=EoVmlONgI9e
[156]. Explore with Dynamic Map: Graph Structured Reinforcement Learning
论文链接: https://openreview.net/forum?id=-u4j4dHeWQi
[157]. Offline Meta-Reinforcement Learning with Advantage Weighting
论文链接: https://openreview.net/forum?id=S5S3eTEmouw
[158]. Deep Q-Learning with Low Switching Cost
论文链接: https://openreview.net/forum?id=7ODIasgLJlU
[159]. AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
论文链接: https://openreview.net/forum?id=OJiM1R3jAtZ
[160]. A Strong On-Policy Competitor To PPO
论文链接: https://openreview.net/forum?id=0migj5lyUZl
[161]. Control-Aware Representations for Model-based Reinforcement Learning
论文链接: https://openreview.net/forum?id=dgd4EJqsbW5
[162]. Formal Language Constrained Markov Decision Processes
论文链接: https://openreview.net/forum?id=NTP9OdaT6nm
[163]. Multi-Agent Imitation Learning with Copulas
论文链接: https://openreview.net/forum?id=gRr_gt5bker
[164]. Projected Latent Markov Chain Monte Carlo: Conditional Sampling of Normalizing Flows
论文链接: https://openreview.net/forum?id=MBpHUFrcG2x
[165]. Efficient Competitive Self-Play Policy Optimization
论文链接: https://openreview.net/forum?id=99M-4QlinPr
[166]. Offline Model-Based Optimization via Normalized Maximum Likelihood Estimation
论文链接: https://openreview.net/forum?id=FmMKSO4e8JK
[167]. Beyond Prioritized Replay: Sampling States in Model-Based RL via Simulated Priorities
论文链接: https://openreview.net/forum?id=B5bZp0m7jZd
[168]. Action Guidance: Getting the Best of Sparse Rewards and Shaped Rewards for Real-time Strategy Games
论文链接: https://openreview.net/forum?id=1OQ90khuUGZ
[169]. What About Taking Policy as Input of Value Function: Policy-extended Value Function Approximator
论文链接: https://openreview.net/forum?id=V4AVDoFtVM
[170]. Optimizing Information Bottleneck in Reinforcement Learning: A Stein Variational Approach
论文链接: https://openreview.net/forum?id=IKqCy8i1XL3
[171]. On the Estimation Bias in Double Q-Learning
论文链接: https://openreview.net/forum?id=FKotzp6PZJw
[172]. Entropic Risk-Sensitive Reinforcement Learning: A Meta Regret Framework with Function Approximation
论文链接: https://openreview.net/forum?id=q_kZm9eHIeD
[173]. Goal-Auxiliary Actor-Critic for 6D Robotic Grasping with Point Clouds
论文链接: https://openreview.net/forum?id=H5B3lmpO1g
[174]. Policy Gradient with Expected Quadratic Utility Maximization: A New Mean-Variance Approach in Reinforcement Learning
论文链接: https://openreview.net/forum?id=BEs-Q1ggdwT
[175]. D2RL: Deep Dense Architectures in Reinforcement Learning
论文链接: https://openreview.net/forum?id=mYNfmvt8oSv
[176]. Intention Propagation for Multi-agent Reinforcement Learning
论文链接: https://openreview.net/forum?id=7apQQsbahFz
[177]. SIM-GAN: Adversarial Calibration of Multi-Agent Market Simulators.
论文链接: https://openreview.net/forum?id=1z_Hg9oBCtY
[178]. Preventing Value Function Collapse in Ensemble Q-Learning by Maximizing Representation Diversity
论文链接: https://openreview.net/forum?id=dN_iVr6iNuU
[179]. REPAINT: Knowledge Transfer in Deep Actor-Critic Reinforcement Learning
论文链接: https://openreview.net/forum?id=P84ryxVG6tR
[180]. Mixture of Step Returns in Bootstrapped DQN
论文链接: https://openreview.net/forum?id=X6YPReSv5CX
[181]. PAC-Bayesian Randomized Value Function with Informative Prior
论文链接: https://openreview.net/forum?id=d2m6yCwyJW
[182]. Learning Safe Multi-agent Control with Decentralized Neural Barrier Certificates
论文链接: https://openreview.net/forum?id=P6_q1BRxY8Q
[183]. Maximum Reward Formulation In Reinforcement Learning
论文链接: https://openreview.net/forum?id=BnokSKnhC7F
[184]. Model-Free Counterfactual Credit Assignment
论文链接: https://openreview.net/forum?id=F8xpAPm_ZKS
[185]. Plan-Based Asymptotically Equivalent Reward Shaping
论文链接: https://openreview.net/forum?id=w2Z2OwVNeK
[186]. Design-Bench: Benchmarks for Data-Driven Offline Model-Based Optimization
论文链接: https://openreview.net/forum?id=cQzf26aA3vM
[187]. Regioned Episodic Reinforcement Learning
论文链接: https://openreview.net/forum?id=amRmtfpYgDt
[188]. Reinforcement Learning with Bayesian Classifiers: Efficient Skill Learning from Outcome Examples
论文链接: https://openreview.net/forum?id=OZgVHzdKicb
[189]. Provably More Efficient Q-Learning in the One-Sided-Feedback/Full-Feedback Settings
论文链接: https://openreview.net/forum?id=vY0bnzBBvtr
[190]. Systematic Evaluation of Causal Discovery in Visual Model Based Reinforcement Learning
论文链接: https://openreview.net/forum?id=gp5Uzbl-9C-
[191]. Safe Reinforcement Learning with Natural Language Constraints
论文链接: https://openreview.net/forum?id=Ua5yGJhfgAg
[192]. ReaPER: Improving Sample Efficiency in Model-Based Latent Imagination
论文链接: https://openreview.net/forum?id=nlWgE3A-iS
[193]. Coordinated Multi-Agent Exploration Using Shared Goals
论文链接: https://openreview.net/forum?id=MPO4oML_JC
[194]. Measuring and mitigating interference in reinforcement learning
论文链接: https://openreview.net/forum?id=26WnoE4hjS
[195]. Hamiltonian Q-Learning: Leveraging Importance-sampling for Data Efficient RL
论文链接: https://openreview.net/forum?id=10XWPuAro86
[196]. A Maximum Mutual Information Framework for Multi-Agent Reinforcement Learning
论文链接: https://openreview.net/forum?id=_zHHAZOLTVh
[197]. Non-decreasing Quantile Function Network with Efficient Exploration for Distributional Reinforcement Learning
论文链接: https://openreview.net/forum?id=f_GA2IU9-K-
[198]. Constrained Reinforcement Learning With Learned Constraints
论文链接: https://openreview.net/forum?id=akgiLNAkC7P
[199]. Efficient Exploration for Model-based Reinforcement Learning with Continuous States and Actions
论文链接: https://openreview.net/forum?id=asLT0W1w7Li
[200]. Error Controlled Actor-Critic Method to Reinforcement Learning
论文链接: https://openreview.net/forum?id=n5yBuzpqqw
[201]. Cross-State Self-Constraint for Feature Generalization in Deep Reinforcement Learning
论文链接: https://openreview.net/forum?id=JiNvAGORcMW
[202]. Safety Aware Reinforcement Learning (SARL)
论文链接: https://openreview.net/forum?id=RDpTZpubOh7
[203]. UneVEn: Universal Value Exploration for Multi-Agent Reinforcement Learning
论文链接: https://openreview.net/forum?id=0z1HScLBEpb
[204]. Interpretable Reinforcement Learning With Neural Symbolic Logic
论文链接: https://openreview.net/forum?id=M_gk45ItxIp
[205]. Network Reusability Analysis for Multi-Joint Robot Reinforcement Learning
论文链接: https://openreview.net/forum?id=hypDstHla7
[206]. Factored Action Spaces in Deep Reinforcement Learning
论文链接: https://openreview.net/forum?id=naSAkn2Xo46
[207]. Genetic Soft Updates for Policy Evolution in Deep Reinforcement Learning
论文链接: https://openreview.net/forum?id=TGFO0DbD_pk
[208]. The Skill-Action Architecture: Learning Abstract Action Embeddings for Reinforcement Learning
论文链接: https://openreview.net/forum?id=PU35uLgRZkk
[209]. Learning Intrinsic Symbolic Rewards in Reinforcement Learning
论文链接: https://openreview.net/forum?id=4CxsUBDQJqv
[210]. Robust Offline Reinforcement Learning from Low-Quality Data
论文链接: https://openreview.net/forum?id=uOjm_xqKEoX
[211]. Adaptive Learning Rates for Multi-Agent Reinforcement Learning
论文链接: https://openreview.net/forum?id=yN18f9V1Onp
[212]. Revisiting Parameter Sharing in Multi-Agent Deep Reinforcement Learning
论文链接: https://openreview.net/forum?id=MWj_P-Lk3jC
[213]. Addressing Distribution Shift in Online Reinforcement Learning with Offline Datasets
论文链接: https://openreview.net/forum?id=9hgEG-k57Zj
[214]. TOMA: Topological Map Abstraction for Reinforcement Learning
论文链接: https://openreview.net/forum?id=yoem5ud2vb
[215]. Multi-agent Policy Optimization with Approximatively Synchronous Advantage Estimation
论文链接: https://openreview.net/forum?id=Rw_vo-wIAa
[216]. Why Convolutional Networks Learn Oriented Bandpass Filters: Theory and Empirical Support
论文链接: https://openreview.net/forum?id=UJRFjuJDsIO
[217]. Self-Activating Neural Ensembles for Continual Reinforcement Learning
论文链接: https://openreview.net/forum?id=Jf24xdaAwF9
[218]. Approximating Pareto Frontier through Bayesian-optimization-directed Robust Multi-objective Reinforcement Learning
论文链接: https://openreview.net/forum?id=S9MPX7ejmv
[219]. Model-Based Reinforcement Learning via Latent-Space Collocation
论文链接: https://openreview.net/forum?id=ku4sJKvnbwV
[220]. CDT: Cascading Decision Trees for Explainable Reinforcement Learning
论文链接: https://openreview.net/forum?id=WdOCkf4aCM
[221]. PGPS : Coupling Policy Gradient with Population-based Search
论文链接: https://openreview.net/forum?id=PeT5p3ocagr
[222]. CAT-SAC: Soft Actor-Critic with Curiosity-Aware Entropy Temperature
论文链接: https://openreview.net/forum?id=paE8yL0aKHo
[223]. Learning to Observe with Reinforcement Learning
论文链接: https://openreview.net/forum?id=65sCF5wmhpv
[224]. Probabilistic Mixture-of-Experts for Efficient Deep Reinforcement Learning
论文链接: https://openreview.net/forum?id=LtgEkhLScK3
[225]. Visual Imitation with Reinforcement Learning using Recurrent Siamese Networks
论文链接: https://openreview.net/forum?id=MBdafA3G9k
[226]. Lyapunov Barrier Policy Optimization
论文链接: https://openreview.net/forum?id=qUs18ed9oe
[227]. A Deeper Look at Discounting Mismatch in Actor-Critic Algorithms
论文链接: https://openreview.net/forum?id=ypJS_nyu-I
[228]. Cross-Modal Domain Adaptation for Reinforcement Learning
论文链接: https://openreview.net/forum?id=0owsv3F-fM
[229]. L2E: Learning to Exploit Your Opponent
论文链接: https://openreview.net/forum?id=m4PC1eUknQG
[230]. MQES: Max-Q Entropy Search for Efficient Exploration in Continuous Reinforcement Learning
论文链接: https://openreview.net/forum?id=98ntbCuqf4i
[231]. Robust Multi-Agent Reinforcement Learning Driven by Correlated Equilibrium
论文链接: https://openreview.net/forum?id=JvPsKam58LX
[232]. R-LAtte: Attention Module for Visual Control via Reinforcement Learning
论文链接: https://openreview.net/forum?id=D4QFCXGe_z2
[233]. Multi-agent Deep FBSDE Representation For Large Scale Stochastic Differential Games
论文链接: https://openreview.net/forum?id=UoAFJMzCNM
[234]. Aspect-based Sentiment Classification via Reinforcement Learning
论文链接: https://openreview.net/forum?id=bfTUfrqL6d
[235]. Refine and Imitate: Reducing Repetition and Inconsistency in Dialogue Generation via Reinforcement Learning and Human Demonstration
论文链接: https://openreview.net/forum?id=JthLaV0RsV
[236]. An Examination of Preference-based Reinforcement Learning for Treatment Recommendation
论文链接: https://openreview.net/forum?id=uxYjVEXx48i
[237]. Adaptive Dataset Sampling by Deep Policy Gradient
论文链接: https://openreview.net/forum?id=t2C42s67gsQ
[238]. Convergence Proof for Actor-Critic Methods Applied to PPO and RUDDER
论文链接: https://openreview.net/forum?id=0hMthVxlS89
[239]. Q-Value Weighted Regression: Reinforcement Learning with Limited Data
论文链接: https://openreview.net/forum?id=rd_bm8CK7o0
[240]. ScheduleNet: Learn to Solve MinMax mTSP Using Reinforcement Learning with Delayed Reward
论文链接: https://openreview.net/forum?id=P63SQE0fVa
[241]. Benchmarking Multi-Agent Deep Reinforcement Learning Algorithms
论文链接: https://openreview.net/forum?id=t5lNr0Lw84H
[242]. Reinforcement Learning for Sparse-Reward Object-Interaction Tasks in First-person Simulated 3D Environments
论文链接: https://openreview.net/forum?id=7AQUzh5ntX_
[243]. Model-Free Energy Distance for Pruning DNNs
论文链接: https://openreview.net/forum?id=k2TyMLwuikx
[244]. D4RL: Datasets for Deep Data-Driven Reinforcement Learning
论文链接: https://openreview.net/forum?id=px0-N3_KjA
[245]. Exploring Transferability of Perturbations in Deep Reinforcement Learning
论文链接: https://openreview.net/forum?id=inBTt_wSv0
[246]. Alpha-DAG: a reinforcement learning based algorithm to learn Directed Acyclic Graphs
论文链接: https://openreview.net/forum?id=0jqRSnFnmL_
[247]. Visual Explanation using Attention Mechanism in Actor-Critic-based Deep Reinforcement Learning
论文链接: https://openreview.net/forum?id=Y0MgRifqikY
[248]. Knapsack Pruning with Inner Distillation
论文链接: https://openreview.net/forum?id=O9NAKC_MqMx
[249]. Reinforcement Learning for Flexibility Design Problems
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1122
Best Last Month

Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx
Information industry by wittx
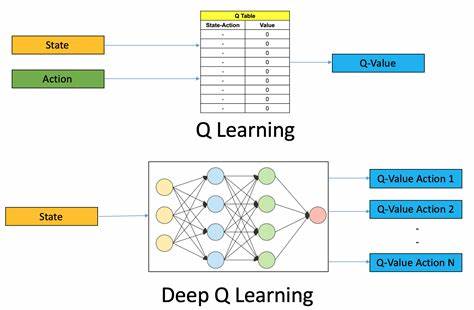
Information industry by wittx
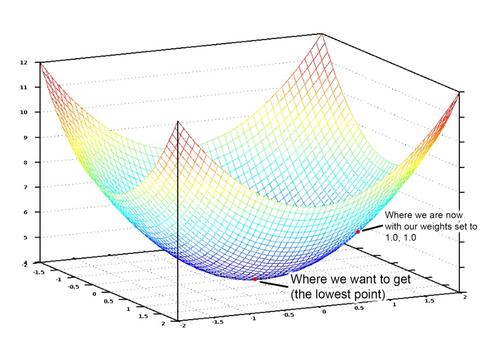
Information industry by wittx
