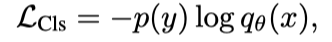-
News Message
Google Research提出超强预训练模型CoCa,在ImageNet上微调Top-1准确率达91%!
- by wittx 2023-03-06
探索大规模预训练基础模型在计算机视觉中具有重要意义,因为这些模型可以快速转移到许多下游任务中。本文提出了对比字幕(Contrastive Captioner,CoCa)模型,它将图像文本编码器-解码器基础模型与对比损失和字幕损失结合起来进行预训练,从而从CLIP等对比方法和SimVLM等生成方法中吸收两种模型的长处。与所有解码器层都attend到编码器输出的标准编码器-解码器Transformer不同,CoCa省略了前一半解码器层中的交叉注意来编码unimodal文本表示,并将交叉注意力图像编码器的其余解码器层级联以进行multimodal图像文本表示。
作者在unimodal图像和文本嵌入之间应用了对比损失,此外,multimodal解码器输出上的字幕损失可以自动回归预测文本token。通过共享相同的计算图,可以以最小的开销高效地计算两个训练目标。通过将所有标签简单地视为文本,CoCa在web级文本数据和带标注的图像上都进行了端到端和从头开始的预训练,统一了表示学习的自然语言监督。
从实验上来看,CoCa在广泛的下游任务中,通过Zero-Shot迁移或最小的任务特定的微调,实现了最先进的性能,包括视觉识别(ImageNet、Kinetics400/600/700、Moments in Time)、跨模态检索(MSCOCO、Flickr30K、MSR-VTT)、多模态理解(VQA、SNLI-VE、NLVR2)和图像字幕(MSCOCO、NoCaps)。在ImageNet分类方面,CoCa获得了86.3%的zero-shot top-1准确率,使用冻结的编码器和学习分类头获得了90.6%,使用可学习的编码器获得了91.0%的top-1准确率。
1. 论文和代码地址

论文名称:CoCa: Contrastive Captioners are Image-Text Foundation Models
论文地址:https://arxiv.org/abs/2205.01917[1]
代码地址:未开源
2. Motivation
深度学习最近见证了基础语言模型的兴起,如BERT、T5、GPT-3,其中模型在网络规模的数据上进行预训练,并通过zero-shot、few-shot或迁移学习展示通用多任务能力。与专门的个体模型相比,大规模下游任务的预训练基础模型可以分摊训练成本,为人类水平的智力提供了突破模型规模限制的机会。
对于视觉和视觉语言问题,已经探索了几个候选基础模型:(1)一些开创性的工作表明,在图像分类数据集(如ImageNet)上,使用交叉熵损失预训练的单编码器模型是有效的。图像编码器提供通用的视觉表示,可以适应各种下游任务。然而,这些模型在很大程度上依赖于图像标注作为标记向量,并且没有吸收自由形式人类自然语言的知识,这阻碍了它们在涉及视觉和语言模态的下游任务中的应用。(2) 最近,一系列研究表明,通过对两个并行编码器进行预训练,并在web级噪声图像-文本对上进行对比损失,可以实现图像-文本基础模型。除了仅用于视觉任务的视觉嵌入外,生成的双编码器模型还可以将文本嵌入编码到相同的潜在空间,从而实现新的跨模态对齐功能,如zero-shot图像分类和图像文本检索。尽管如此,由于缺少学习融合图像和文本表示的组件,这些模型不直接适用于视觉问答(VQA)等联合视觉语言理解任务。(3) 另一些研究探索了使用编码器-解码器模型进行生成性预训练,以学习通用视觉和多模态表示。在预训练期间,模型在编码器侧处理图像,并在解码器输出上应用语言建模(LM)损失。对于下游任务,解码器输出可以用作多模态理解任务的联合表示。虽然经过预训练的编码器-解码器模型已经获得了优异的视觉语言结果,但它们不会生成与图像嵌入对齐的纯文本表示,因此对于跨模态对齐任务来说,不太可行和有效。
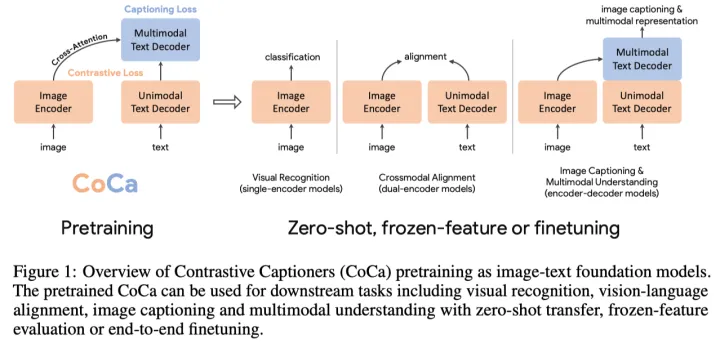
在这项工作中,作者统一了单编码器、双编码器和编码器-解码器范例,并训练了一个包含所有三种方法能力的图像-文本基础模型。作者提出了一个名为对比字幕(CoCa)的简单模型族,该族具有经过对比丢失和字幕生成损失训练的编码器-解码器结构。如上图所示,作者将解码器Transformer解耦为两部分,单峰解码器(unimodal decoder)和多峰解码器(multimodal decoder)。作者省略了单峰解码器层中的交叉注意来编码纯文本表示,而级联多峰解码器层交叉注意到图像编码器输出来学习多模态图像文本表示。作者在图像编码器和单峰文本解码器的输出之间应用对比目标,并在多峰解码器的输出处应用字幕目标。此外,通过将所有标签简单地视为文本,对CoCa进行图像标注数据和噪声图像文本数据的训练。图像标注文本的生成性损失提供了与单编码器交叉熵损失方法类似的细粒度训练信号,有效地将所有三种预训练范式纳入了一种单一的方法中。
CoCa的设计利用对比学习来学习全局表示,用字幕损失来学习细粒度区域级特征,从而有利于上图所示的所有三个类别的任务。实验结果表明,CoCa使用zero-shot迁移或最小任务特定适应,单个预训练模型可以优于许多任务特定的模型。例如,CoCa在ImageNet上获得了86.3%的zero-shot精度,在MSCOCO和Flickr30k上获得了更好的zero-shot跨模态检索。使用冻结编码器,CoCa在ImageNet分类上的得分为90.6%,在Kinetics40/600/700上的得分为88.0%/88.5%/81.1%。经过轻量化微调后,CoCa在ImageNet上的Top-1准确率达到91.0%,在VQA上达到82.3%,在NoCaps上达到120.6 CIDEr。
3. 方法
作者首先回顾了三个不同利用自然语言监督的基础模型:单编码器分类预训练、双编码器对比学习和编码器解码器图像字幕。然后,作者提出了对比字幕(CoCa)模型,它在一个简单的结构下共享对比学习和图像到字幕生成的优点。作者进一步讨论了CoCa模型如何在zero-shot迁移或最小任务适应的情况下快速迁移到下游任务。
3.1 Natural Language Supervision
Single-Encoder Classification
经典的单编码器方法通过对大型图像注释数据集(如ImageNet、Instagram或JFT)上的图像分类来预训练视觉编码器,其中标注文本的词汇通常是固定的。这些图像标注通常映射到离散的类向量中,以使用交叉熵损失进行学习:
其中,是来自ground truth标签y的one-hot、multi-hot或平滑标签分布。然后,学习的图像编码器用作下游任务的通用视觉表示提取器。
Dual-Encoder Contrastive Learning
与使用单编码器分类进行预训练(需要人工标注标签和数据清理)相比,双编码器方法利用了嘈杂的web级文本描述,并引入了一个可学习的文本塔来编码自由格式的文本。通过将成对文本与采样batch中的其他文本进行对比,共同优化两个编码器:
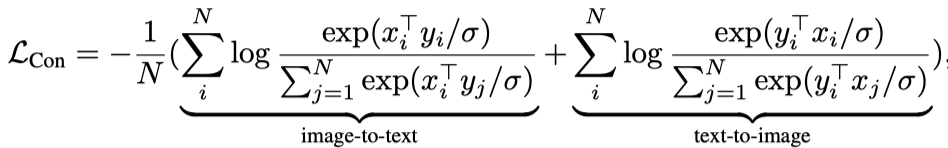
其中,和是第i对中图像和第j对中文本的归一化嵌入。N是Batch大小,σ是缩放logits的temperature。除了图像编码器外,双编码器方法还学习对齐文本编码器,该编码器支持图像文本检索和zero-shot图像分类等跨模态对齐应用。实验结果表明,对于损坏或分布不均的图像,zero-shot分类更鲁棒。
Encoder-Decoder Captioning
虽然双编码器方法将文本作为一个整体进行编码,但生成方法(也称为captioner)旨在实现更细的粒度,并要求模型以自回归的方式预测精确的y标记文本。按照标准编码器-解码器架构,图像编码器提供潜在的编码特征(例如,使用视觉Transformer或卷积网络),文本解码器学习在前向自回归因式分解下最大化成对文本y的条件似然:

编码器-解码器通过teacher-forcing进行训练,使计算并行化并最大限度地提高学习效率。与以前的方法不同,captioner方法产生了一种可用于视觉语言理解的联合图像文本表示,并且还能够使用自然语言生成图像字幕。
3.2 Contrastive Captioners Pretraining
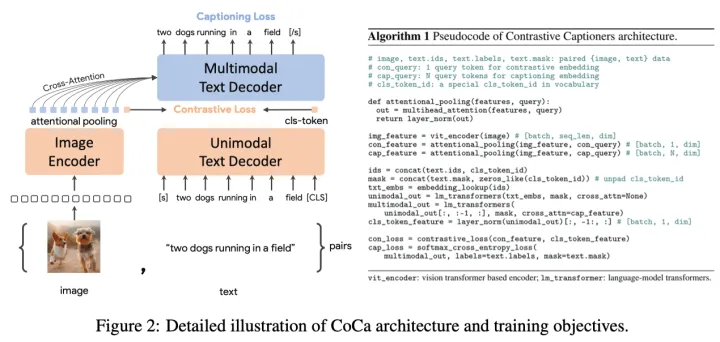
上图展示了本文提出的contrastive captioner(CoCa):一种简单的编码器-解码器方法,它无缝地结合了三种训练范式。与标准图像-文本编码器-编码器模型类似,CoCa通过神经网络编码器将图像编码为潜在表示,例如,视觉Transformer(ViT),并使用因果掩蔽Transformer解码器解码文本。与标准解码器Transformer不同,CoCa在编码单峰文本表示时省略了前半个解码器层中的交叉注意力,而级联其余解码器层,交叉注意到图像编码器以实现多峰图像文本表示。因此,CoCa解码器同时产生单峰和多峰文本表示,使模型能够将对比和生成目标应用为:
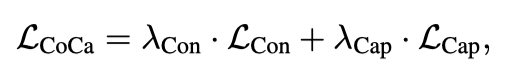
其中和 是损失加权超参数。当词汇表是所有标签名称的集合时,单编码器交叉分类目标可以解释为应用于图像注释数据的生成方法的特例。
Decoupled Text Decoder and CoCa Architecture
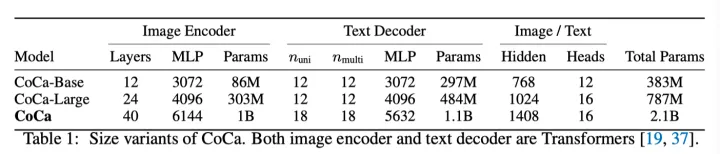
captioning的方法优化了文本的条件likelihood,而对比法使用无条件文本表示。为了解决这一难题并将这两种方法结合到一个模型中,作者提出了一种简单的解耦解码器设计,通过跳过单峰解码器层中的交叉注意机制,将解码器分为单峰和多峰分量。也就是说,底部的单峰解码器层将输入文本用具有因果掩蔽的自注意力编码为潜在向量,而顶部的个多模态层进一步将因果掩蔽的自注意力以及交叉注意应用于视觉编码器的输出。所有解码器层都不能让token attend到未来的token,对于字幕目标,使用多模态文本解码器输出非常简单。对于对比目标,作者在输入句子的末尾附加一个可学习的token,并使用单峰解码器相应的输出作为文本嵌入。根据ALIGN,预训练图像分辨率为288×288,patch大小为18×18,总共生成256个图像token。本文最大的CoCa模型(简称“CoCa”)遵循ViT-giant设置,图像编码器中有1B个参数,文本解码器中有2.1B个参数。上表展示了“CoCa”,“CoCa-Base”和“CoCa-Large”的设置。
Attentional Poolers
值得注意的是,对比损失对每个图像使用单个嵌入,而解码器通常关注编码器-解码器捕获器中的一系列图像输出token。本文的初步实验表明,单个池化的图像嵌入有助于视觉识别任务作为全局表示,而更多的视觉token(因此更细粒度)有利于需要区域级特征的多模态理解任务。因此,CoCa采用任务特定的注意力池化来定制视觉表征,以用于不同类型的训练目标和下游任务。在这里,pooler是一个具有个可学习查询的单个多头注意层,编码器输出为键和值。通过这一点,模型可以为两个训练目标学习不同长度的嵌入。使用特定于任务的池化不仅可以满足不同任务的不同需求,还可以将池化器作为自然的任务适配器引入。作者在预训练中使用注意力池化对生成损失和对比损失进行预训练。
Pretraining Efficiency
解耦解码器设计的一个好处是,对于所考虑的两种训练损失,其损失特定的参数可以忽略不计。由于自回归语言模型在完整句子上使用因果掩蔽进行训练,解码器可以通过单个前向传播有效地生成对比损失和生成损失的输出。因此,大部分计算是在两个损失之间共享的,与标准编码器-解码器模型相比,CoCa只会产生最小的开销。
3.3 Contrastive Captioners for Downstream Tasks
Zero-shot Transfer
预训练的CoCa模型通过利用图像和文本输入以Zero-Shot方式执行许多任务,包括Zero-Shot图像分类、Zero-Shot图像文本检索、Zero-Shot视频文本检索。
Frozen-feature Evaluation
如上所述,CoCa在共享主干编码器的同时,采用任务特定的注意力池化来定制不同类型下游任务的视觉表示。这使得该模型能够作为一个冻结编码器获得强大的性能,只需要学习一个新的池化层来聚合特征。它还可以帮助解决多任务问题,这些问题共享相同的冻结图像编码器计算,但不同的任务特定头。
CoCa for Video Action Recognition
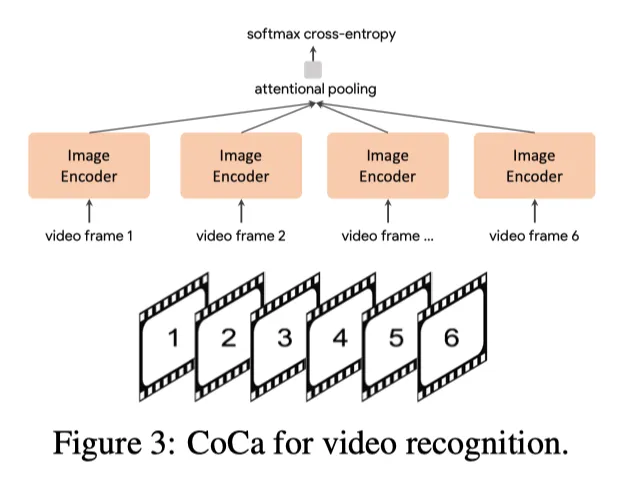
作者使用一种简单的方法为视频动作识别任务启用一个学习的CoCa模型。首先获取视频的多个帧,并将每个帧分别馈送到共享图像编码器中,如上图所示。对于冻结的特征评估或finetuning,作者在空间和时间特征token上学习了一个额外的池化器,该池化具有softmax交叉熵损失。注意,池化器只有一个查询token,因此在所有空间和时间token上进行池化计算并不昂贵。对于zero-shot视频文本检索,作者使用了一种更简单的方法,即计算16帧视频的平均嵌入量(帧从视频中均匀采样)。在计算检索度量时,作者还将每个视频的标题编码为目标嵌入。
4.实验
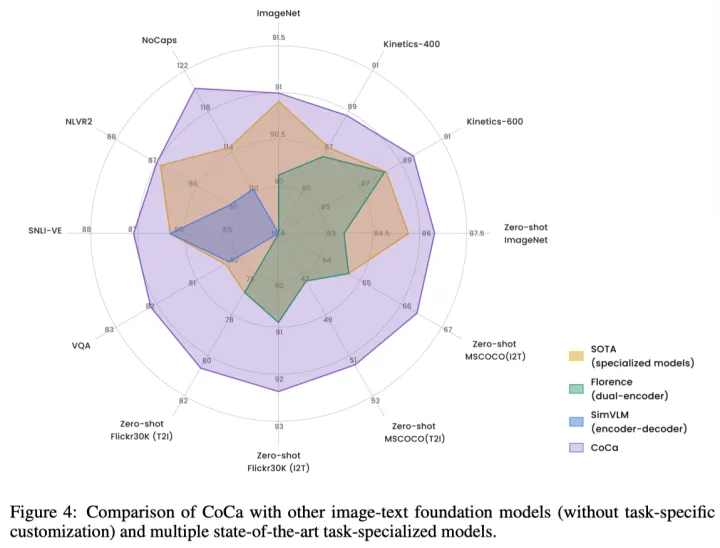
上图展示了与其他双编码器和编码器-解码器基础模型以及SOTA的任务专用方法相比,CoCa具有明显性能优势。
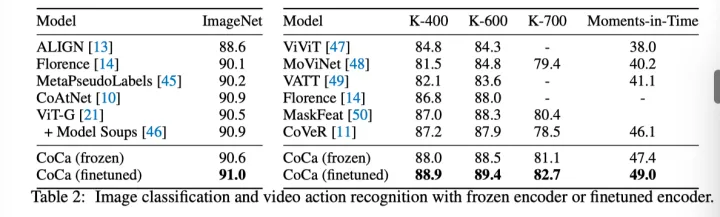
如上表所示,在不微调全部编码器的情况下,CoCa已经实现了具有竞争力的Top-1分类精度,并且在视频任务上优于先前Top-1的任务特定的方法。
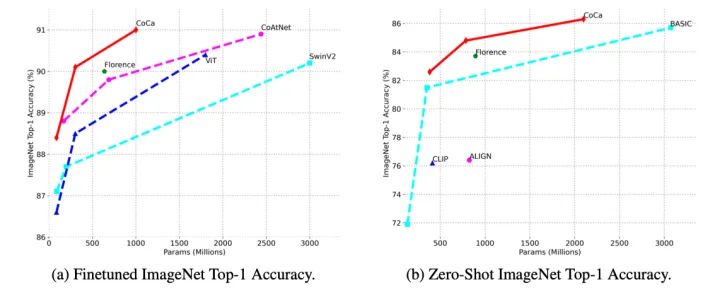
上表展示了本文方法在ImageNet上finetuning和zero-shot的性能。
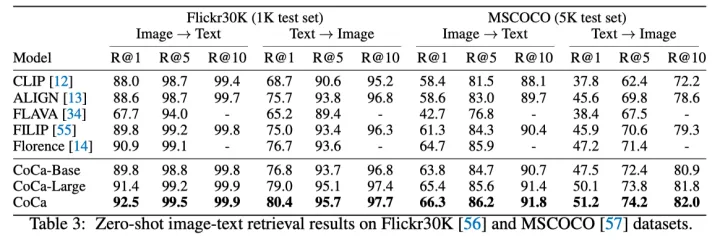
上表展示了Zero-shot的图文检索的性能对比。
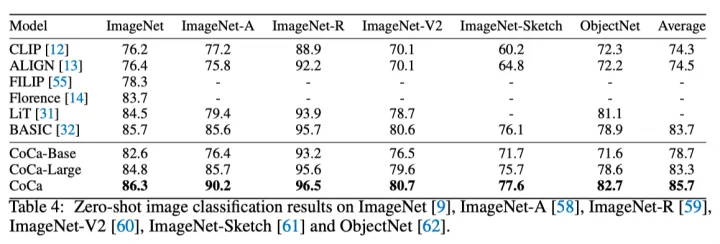
上表展示了不同数据集上Zero-shot的图片分类任务的性能对比。

上表展示了MSRVTT数据集上Zero-shot的视频文本检索任务的性能对比。
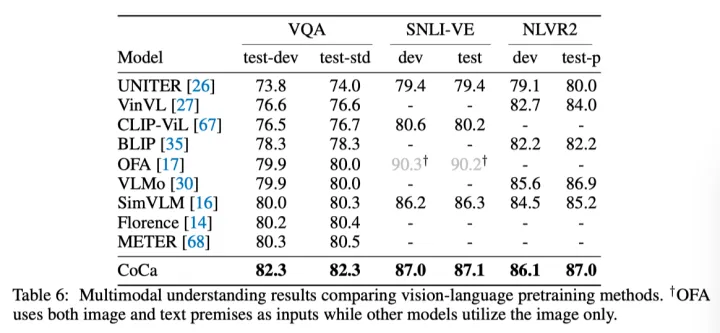
上表展示了不同多模态理解任务上本文方法和其他预训练方法的性能对比。

上表展示了本文提出的模块和不同超参数设置的消融实验结果。
5. 总结
在这项工作中,作者提出了对比字幕(CoCa)模型,这是一个新的图像-文本基础模型,它将现有的视觉预训练纳入自然语言监督。在单个阶段中,通过来自不同数据源的图像-文本对的预训练,CoCa在编码器-解码器模型中有效地结合了对比和字幕的目标。CoCa在一系列视觉和视觉语言问题上通过一个checkpoint获得了一系列SOTA的表现。
参考资料
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1152
Best Last Month
Information industry by wittx
Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx
Information industry by wittxMachine learning-eabled constrained multi-objective desig of architected materials

Petrochemical industry by wittxLarge-area and adaptable electrospun silicon-based thermoelectric nanomaterials with high energy con

Information industry by wittx