
-
News Message
微软 BEiT v3(Image as a Foreign Language)
- by wittx 2023-03-06
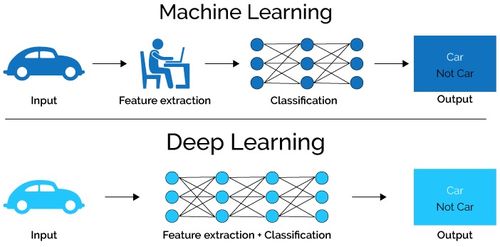
BEiT-1
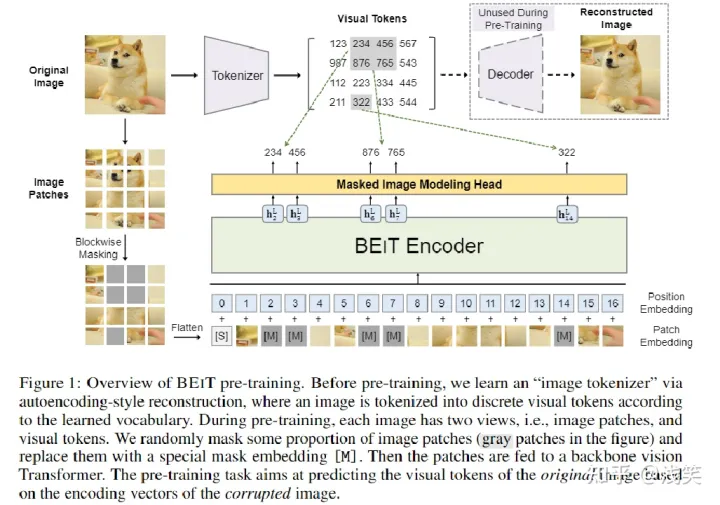
- Motivation :仿照NLP领域的方法去做CV领域的预训练
- 方法:基于损坏的图像patch恢复原始视觉token
- 结构 :只有encoder
- 任务 :pre-training(预测视觉token)
- 缺点:没有移除mask的patch,计算量较大;图片离散化成了一个个的数字(类似文本),但对于cv任务提升不大;编码器只有一部分负责表征学习,还有一部分在做pretext task;MIM 是像素级,而非语义级
BEiT-2
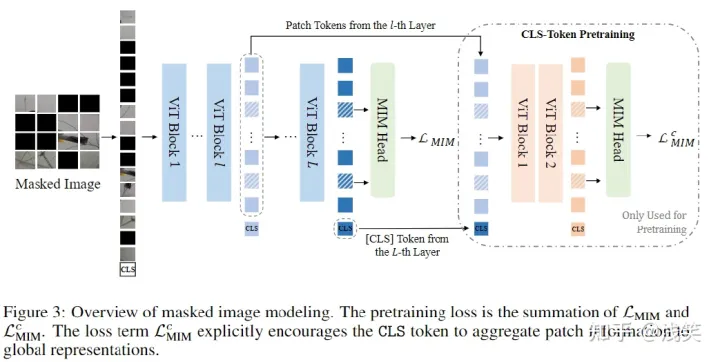
- Motivation :将 MIM 从像素级提升到语义级
- 方法:引入向量量化知识蒸馏(VQ-KD)来构建一个更有语义的 tokenizer; 帮助CLS token学习语义
- 结构 :只有encoder
- 任务 :pre-training
(1) VQ-VAE
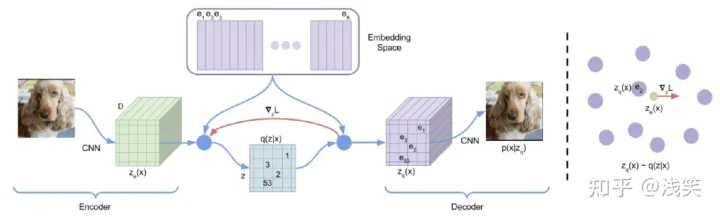
(2) VQ-KD
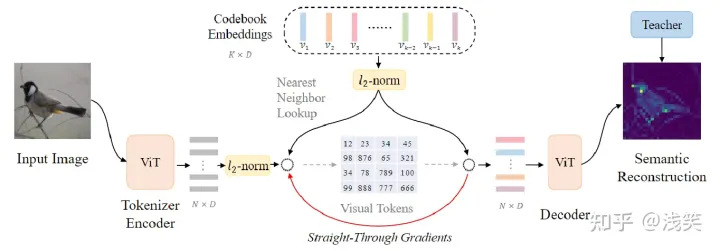
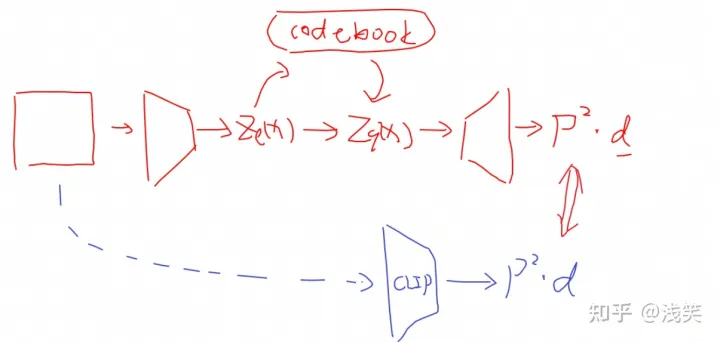
- 结构:encoder和decoder采用了transformer架构
- 实现:重建目标从像素级别的对齐,变成了特征级别的对齐。
- 改进:l2-norm对训练稳定性的优化、码本特征维度设置得较小
BEiT-3
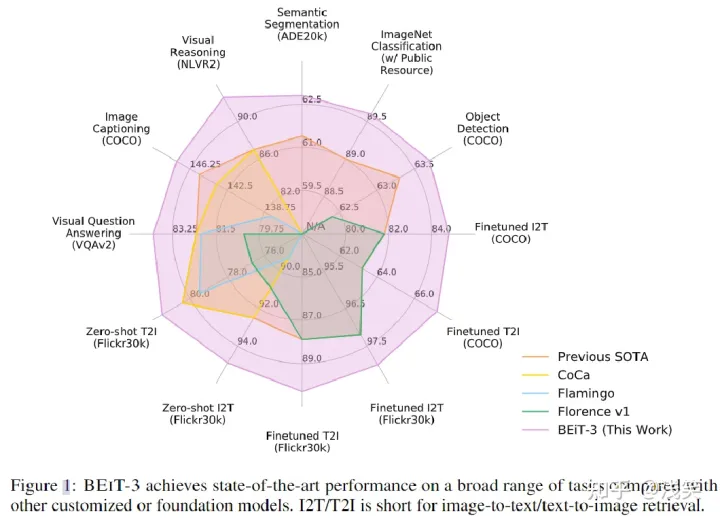
- 动机:多模态和通用基础模型的“大一统”
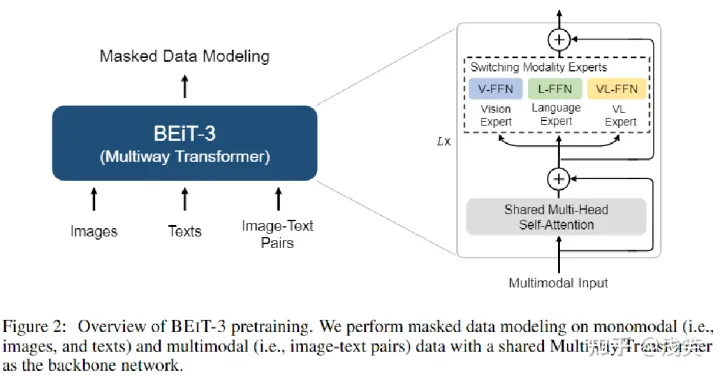
- 方法:BEiT-3 实现了生成式、多模态预训练的统一
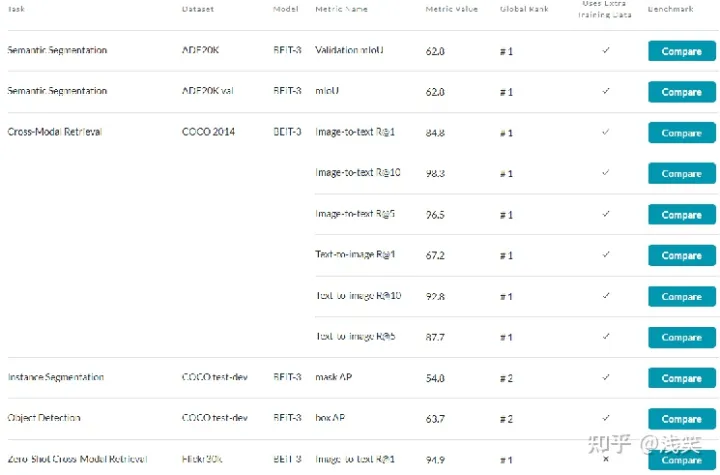
- 1. 网络架构: Multiway Transformer架构作为骨干网络
- 2. 预训练方法: 所有数据都能当成文本数据
- 3. 规模效应: 10亿数量级参数量, 下游任务的泛化能力增强
(1)骨干网络 Multiway Transformer
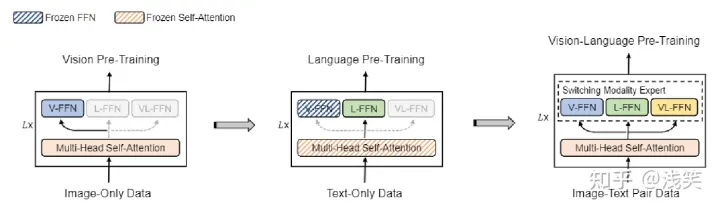
- MLM: 10%
- MIM: 40%
- MVLM: 50% and 40%
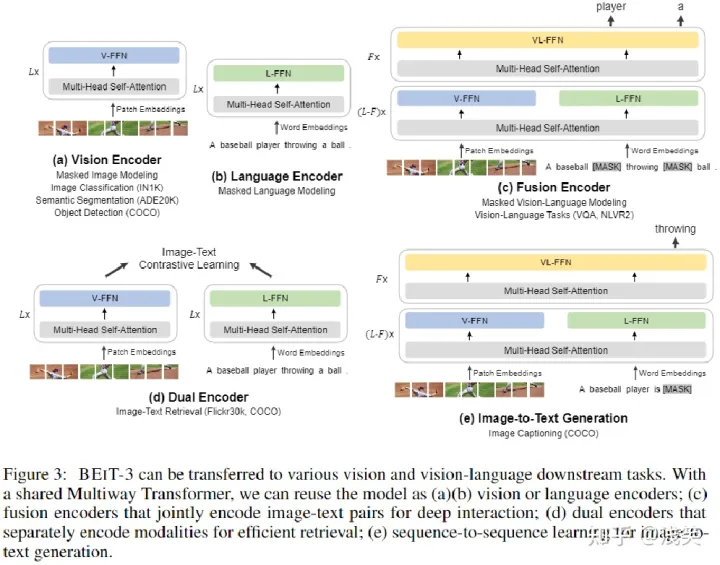
(2)掩码数据建模预训练任务
- image--tokenizer of BEIT v2
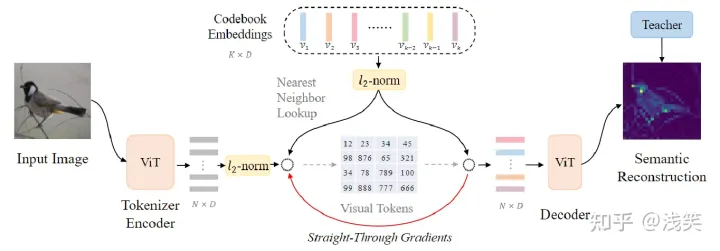
- text--tokenizer of SentencePiece


设计思想: 把所有的原始输入文本看成unicode字符序列,空格也算
(3) 规模扩大
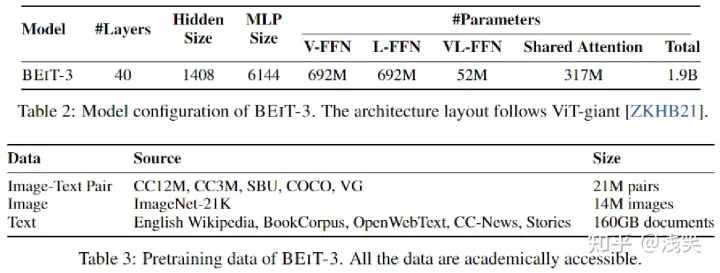
- 在 NLP 领域,Megatron-Turing NLG 模型有5300亿参数
- 在 CV 领域,Swin Transformer v2.0具有30亿参数
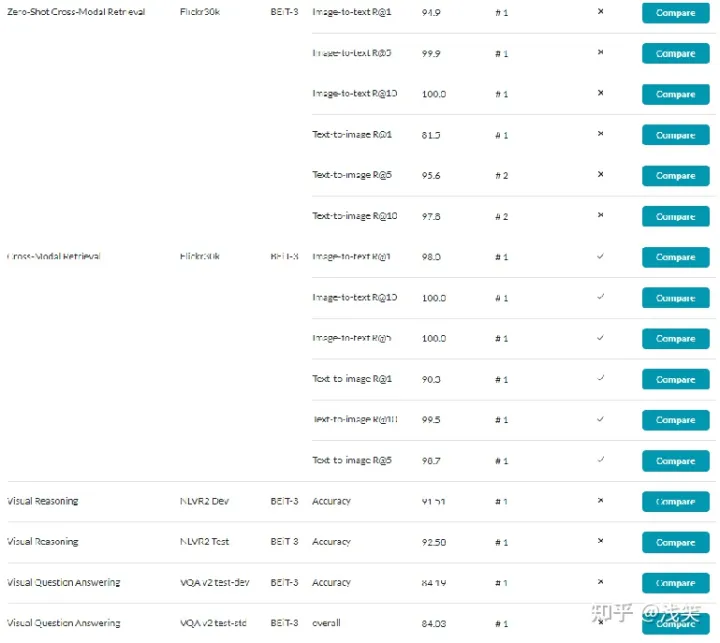
(4) 实验结果
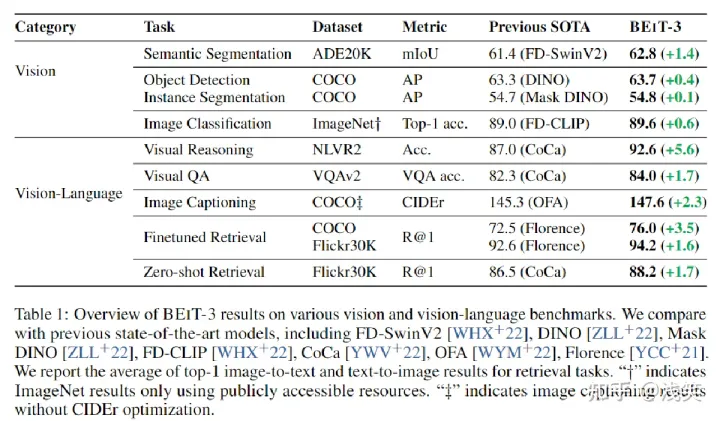
- Vision-Language

1. 视觉问答(VQA):
要求模型回答关于输入图像的自然语言问题。将任务定义为分类问题(从训练集中3129个最频繁的答案候选中预测答案)。微调为融合编码器
2. 视觉推理(NLVR):
需要模型来对图像和自然语言描述进行联合推理, 以确定文本对图像的描述是否正确。微调为融合编码器
3. 图像字幕(coco captioning)
该任务旨在为给定的图像生成自然语言标题。使用交叉熵损失,而不使用CIDEr进行优化。作为条件生成模型,微调为融合编码器
4. 图像-文本检索(MSCOCO/Flickr30K):
测量图像和文本之间的相似度。微调为双编码器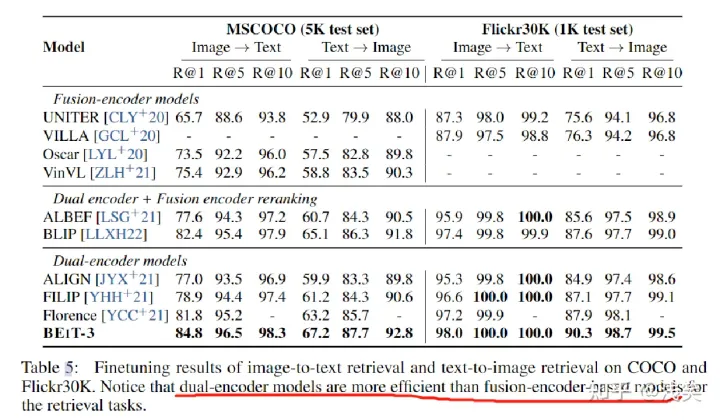
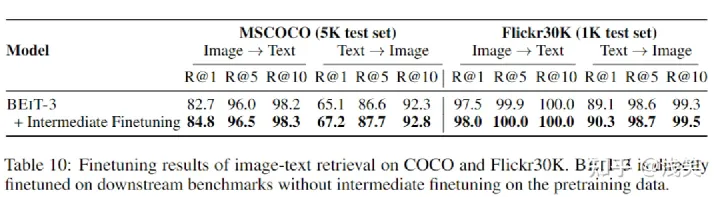
没有使用COCO和Flickr30K图像-文本对数据进行预训练。仅进行微调
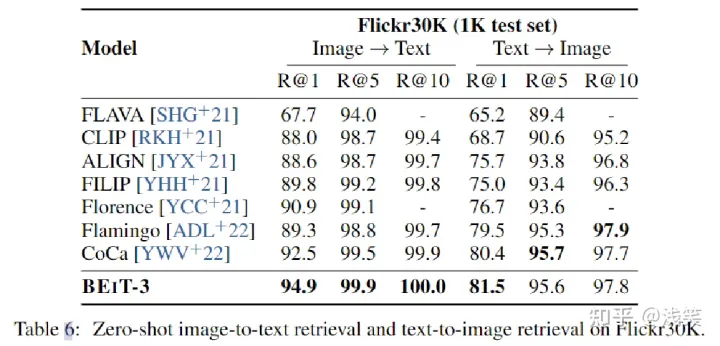
ZSL就是希望对其从没见过的类别进行分类,直接进行推理能力
- Vision
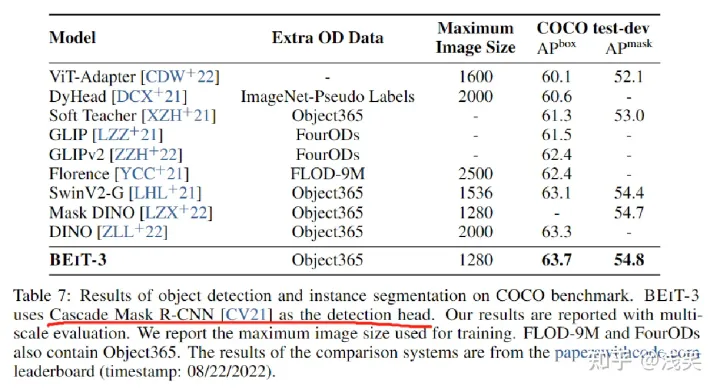
首先用Objects365数据集进行中间微调,然后在COCO数据集上对模型进行微调。COCO数据集包括118k训练、5k验证和20k测试图像
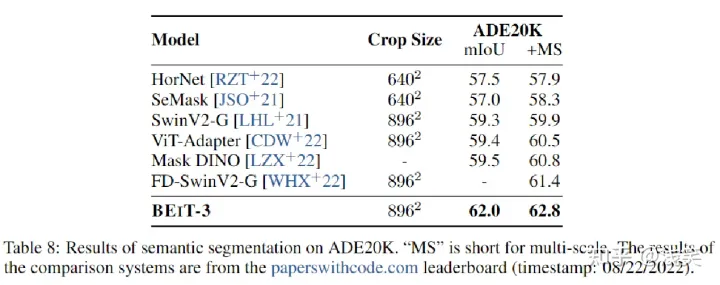
ADE20K包含20k用于训练的图像和2k用于验证的图像;采用Mask2Former作为分割框架
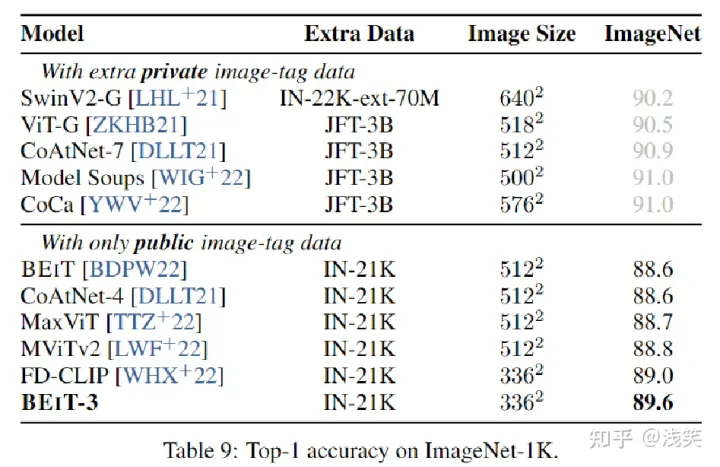
ImageNet-1K包含1.28M训练图像和50k 1k类的验证图像。首先在ImageNet-21K上执行中间微调,然后在ImageNet-1K上训练模型。定义为图像到文本检索任务,使用类别名称作为文本来构建图像-文本对。BEIT-3被训练为双编码器
https://www.zhihu.com/question/549621097/answer/2649483107
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1154
匿名
匿名
匿名
匿名
匿名
匿名
匿名
匿名
匿名
匿名
匿名
匿名
匿名
匿名
匿名
匿名
匿名
匿名
匿名
匿名
Best Last Month

Information industry by wittx
Information industry by wittx

Information industry by wittx

Information industry by wittxFast cycling of lithium metal in solid-state batteries by constriction-susceptible anode materials
Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx
Information industry by wittx
