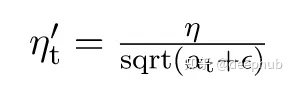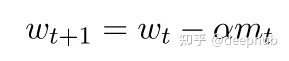-
News Message
SDG,ADAM,LookAhead,Lion机器学习优化器
- by wittx 2023-06-19
优化器
首先,让我们定义优化。当我们训练我们的模型以使其表现更好时,首先使用损失函数,训练时损失的减少表明我们的模型运行良好。而优化是用来描述这种减少损失技术的术语。
“损失函数”是什么意思?
多个变量的值被映射成一个实数,该实数直观地表示使用损失函数与事件相关的一些“成本”。
实际值与模型预测值之间的差值被加起来被称作损失,而计算这种差值的函数被称作损失函数。
Σ (y_actual — y_predicted)/n (from i=1 to n {n = Number of samples})
这是一种衡量算法对它所使用的数据建模的好坏的方法。如果你的预测不准确,你的损失函数将产生更大的值。数字越低,说明模型越好。
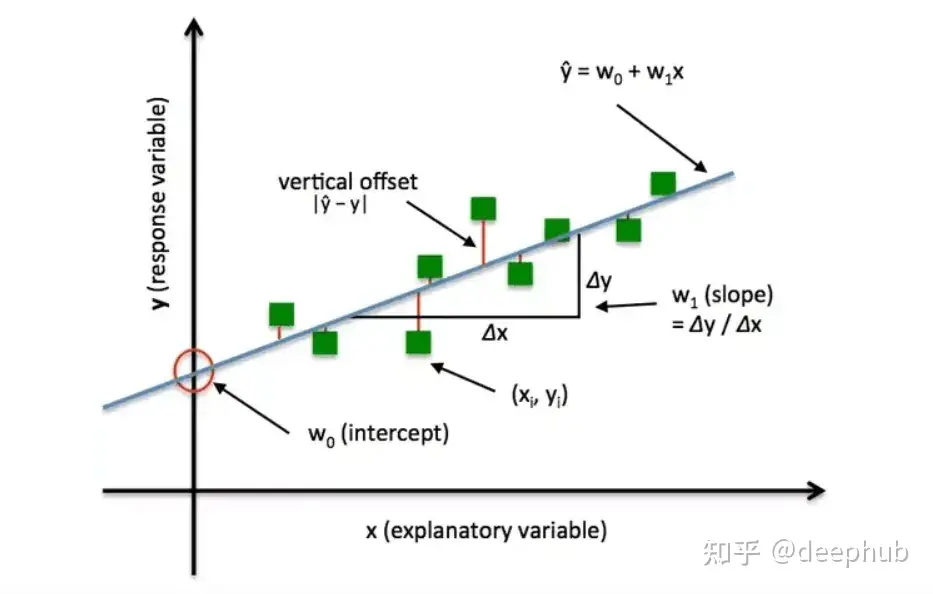
实际的Y值由上面例子中的绿色点表示,拟合的直线由蓝色线表示(由我们的模型预测的值)。
让我们开始介绍优化技术来增强我们模型并尽可能减少前面提到的损失函数
梯度下降法 Gradient Descent
术语“梯度”指的是当函数的输入发生轻微变化时,函数的输出会发生多大的变化。
使用微积分,梯度下降迭代调整参数值,以在定义初始参数值后最小化所提供的成本函数。这是根据重复直到收敛方法完成的。
1、通过计算函数的一阶导数(y = mX + c {m =斜率,c =截距)来确定函数的梯度或斜率
2、斜率将从当前位置提升一个等于eta(学习率)倍的量到局部最小值,这是通过与梯度方向相反的方向移动来进行的
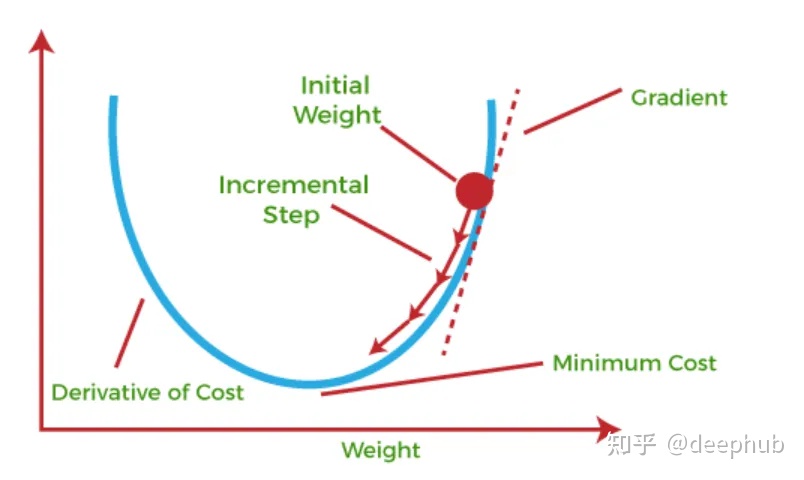
学习率:梯度下降向局部最小值下降所采取的步骤的大小,较大的步长是由高学习率产生的,但也有超过最小值的风险。低学习率还表明步长较小,这降低了操作效率,但提供了更高的准确性,并且有时无法逃出局部最小值,所以学习率是一个很重要的超参数。
随机梯度下降
通过一次加载n点的整个数据集来计算损失函数的导数,SGD方法不是在每次迭代中使用整个数据集,而是通过随机选择少量样本来计算导数,从而降低了计算强度。
SGD的缺点是,一旦它接近最小值,它就不会稳定下来,而是四处反弹,给我们一个很好的模型性能值,但不是最好的值。这可以通过改变模型参数来解决。
使用SGD是大型数据集的理想选择。但是当数据集较小或中等时,最好应用GD来获得更优的解决方案
小批量的梯度下降
小批量梯度将大数据集划分为小批量,并分别更新每个批量,这样既解决了GD的计算消耗问题,也解决了SGD到达最小值的路径问题,这也就是我们在训练时设置batch size参数的作用。
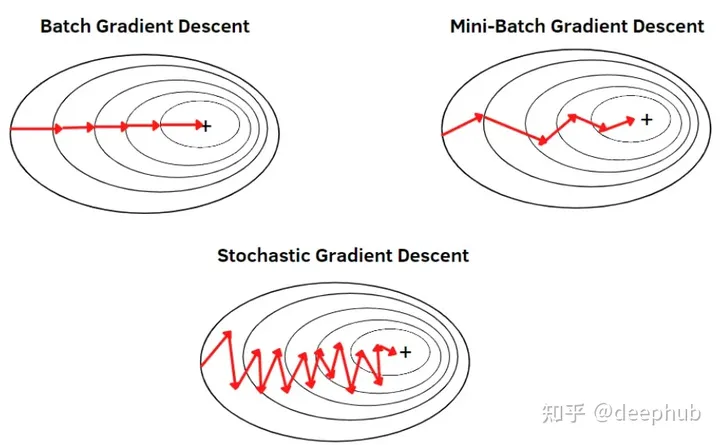
也就是说:
- 梯度下降(GD):在整个训练集之后,训练的参数会被修改
- 随机梯度下降(SGD):在每一个样本训练之后更新参数
- 小批量的梯度下降 (Mini Batch Gradient Descent): 每批完成后,更新参数
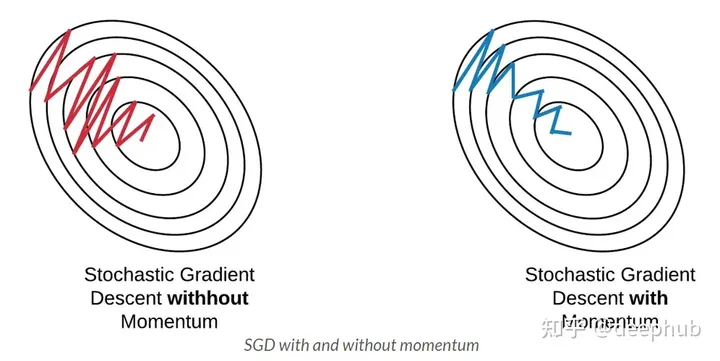
带动量的梯度下降 Momentum Stochastic Gradient
为了平滑更新,考虑到以前的梯度。它不是更新权重,而是计算前几次迭代的梯度平均值。
比传统的梯度下降方法更快。动量通过用指数加权平均去噪梯度来解决这个噪声问题,加快了在正确方向上的收敛,减缓了在错误方向上的波动。这个动量超参数用符号“γ”表示。
权重由θ = θ−γ(t)更新,动量项通常设置为0.9或类似的值,所有以前的更新,计算t时刻的动量,给予最近的更改比旧的更新更多的权重。这导致收敛加速并更快地达到最小值。
如果你使用pytorch,有一个momentum 参数,就是这个了。
Adaptive Gradient Descent (AdaGrad)
AdaGrad消除了手动调整学习率的需要,在迭代过程中不断调整学习率,并让目标函数中的每个参数都分别拥有自己的学习率。利用低学习率的参数链接到频繁发生的特征,并使用高学习率的参数链接到很少发生的特征。它适合用于稀疏数据。
每个权重以不同的速率(η)学习。
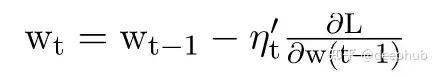
在每次迭代中,每个权重的不同学习率用alpha(t)表示,η =常数,Epsilon =正整数(以避免除0误差)
Adagrad的一个优点是不需要手动调优速率,大多数将其保持在默认值0.01。随着重复次数的增加,alpha(t)会变得相当大,结果ηt’会更快地变化。因此以前的权重将几乎等于新的权重,这可能导致收敛速度较慢。
Adagrad也一些缺点,由于每一个额外的项都是正的,梯度的平方的累积和,分母中的alpha(t)在训练过程中不断扩大,导致学习率下降,最终变得无限小,会导致梯度消失的问题另外就是它是单调下降的学习速率。必须使用初始全局学习率来设置它。
AdaDelta
Adadelta 是 Adagrad 的更可靠的增强,它根据梯度更新的移动窗口来调整学习率,而不是通过取指数衰减平均值来累加所有先前的梯度(累积和)。 在时间步 t 影响 E[g2]t 的运行平均值的唯一因素是先前的平均值和当前梯度。

这有助于在迭代次数非常大时防止低收敛率并导致更快的收敛。即使在进行了多次升级之后,Adadelta 仍以这种方式学习。 与 Adagrad 不同,我们不需要为 Adadelta 选择初始学习率。
Adaptive Moment Estimation (ADAM)
Adam 的优化方法结合了偏差校正、RMSprop 和 带动量SGD。
所以我们没有单独介绍RMSprop
1、RMSProp:通过使用“指数移动平均值”来提高性能,这是平方梯度的平均值。
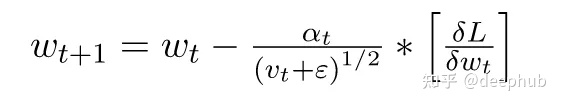
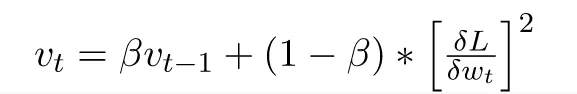
在 mt & vt 计算中,添加的表达式 (1-β)[∂L/∂Wt] 和 (1-β)[∂L/∂Wt]² 分别用于偏差校正,m 和 v 初始化为 0
用于 mt 和 vt 的超参数 β(分别为 β1 和 β2)在 mt 的情况下默认为 0.9,在 vt 的情况下默认为 0.999。 它们的唯一作用是控制这些移动平均线的指数率。因为这里的α 为 0.001,ε 为 10⁻⁷。
还记得ADAM的默认值吗,就是这俩了,对吧。
2、Momentum:与上面的带动量的梯度下降一样,对梯度进行“指数加权平均”,以加速梯度下降算法的收敛到最小值。它是对第一个矩(均值)的估计。
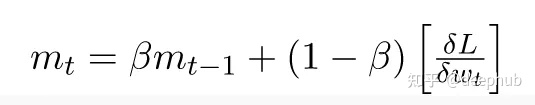
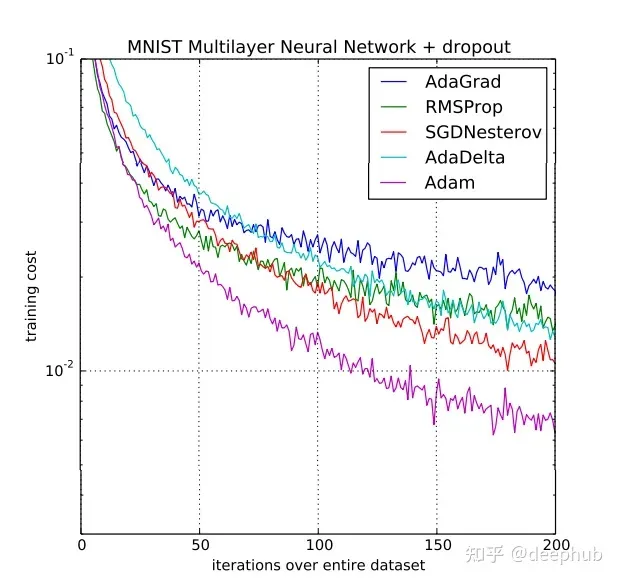
下面的截图是来自研究论文“ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION”的图表显示了实验支持的理由,为什么ADAM是训练成本最低的最佳优化技术
在Adam的基础上还出现了Nadam,AdamW,RAdam等变体,这里就不详细介绍了
ADAM自从发布以来就变为了我们最常用的默认优化器,在没有选择的时候我们直接使用它就可以了,当然上面的变体可以试试,这里推荐试试RAdam,我自测效果不错。
Lookahead
Lookahead是Adam的作者在19年发布的一个方法,虽然它不能算做一个优化器,但是它可以和任何优化器组合使用,所以我们这里要着重的介绍一下。
Lookahead 算法与已有的方法完全不同,它迭代地更新两组权重。直观来说,Lookahead 算法通过提前观察另一个优化器生成的「fast weights」序列,来选择搜索方向。
它可以提高基于梯度的优化方法(如随机梯度下降(SGD)及其变体)的收敛速度和泛化性能。
Lookahead背后的思想是在当前梯度更新的方向上迈出一步,然后使用一组额外的权重(称为“慢权重”)在同一方向上迈出一步,但时间范围更长。与原始权重相比,这些慢权重更新的频率更低,有效地创建了对优化过程未来的“展望”。
在训练期间,Lookahead计算两个权重更新:快速权重更新,它基于当前的梯度并应用于原始权重,以及慢速权重更新,它基于之前的慢速权重并应用于新的权重集。这两个更新的组合给出了最终的权重更新,用于更新原始权重。使用慢权重提供了一种正则化效果,有助于防止过拟合并提高泛化性能。此外,这种前瞻机制有助于优化器更有效地逃避局部最小值和鞍点,从而导致更快的收敛。
Lookahead已被证明在一系列深度学习任务(包括图像分类、语言建模和强化学习)上优于Adam和SGD等其他优化算法。他的使用方式也很简单,我们可以将它与任何优化器相结合:
base_optim = RAdam(model.parameters(),lr = 0.001)
optimizer = Lookahead(base_optim, k=5, alpha=0.5)然后获得的这个optimizer就像以前的优化器一样使用就可以了
LION
最后我们再介绍一个google在2月最新发布的 自动搜索优化器 论文的名字是《Symbolic Discovery of Optimization Algorithms》,作者说通过数千 TPU 小时的算力搜索并结合人工干预,得到了一个更省显存的优化器 Lion(EvoLved Sign Momentum),能看的出来,为了凑LION这个名字作者也是煞费苦心。
所以这里我们不介绍Lion的具体算法,因为作者说了数千 TPU 小时的算力搜索 这个我们没法评判,这里只介绍一些性能的对比。
作者在论文中与 AdamW进行对比:
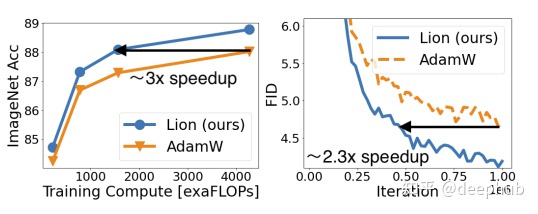
并且在imagenet上训练了各种模型来获得
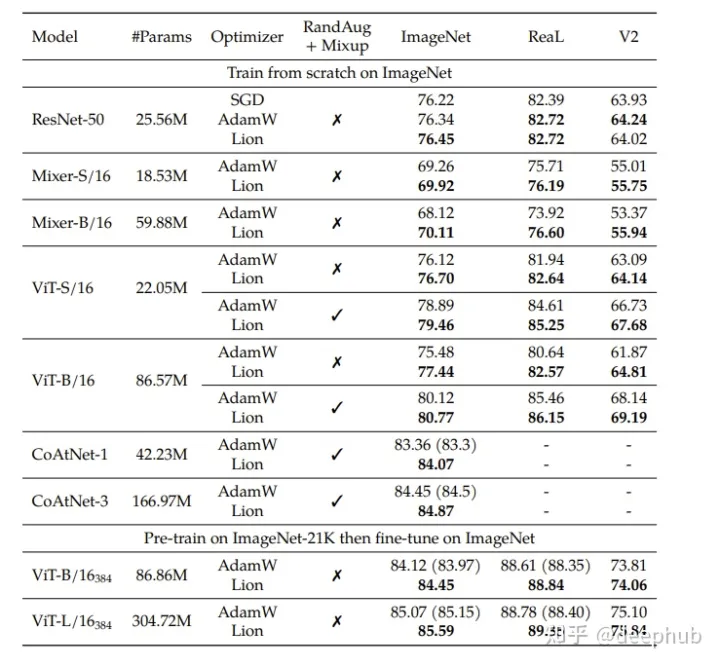
从上图看出Lion还是有所提高的。但是从下图可以看到,大批次的lion表现得更好

总结
优化器是深度学习训练的基础,有很多的优化器可以选择,但是我们可以看到,最基础的SGD为我们提供了优化器工作的理论基础,而Adam的出现使得我们得到了一个在训练时默认的选择(或者可以直接试试RAdam)。在这之上,如果你只想通过设置优化器的方式来进一步提高模型性能的话,可以使用Lookahead。如果想试试最新的那么Lion应该还好,但是具体的效果还需要实地的测试。
最后Lookahead:https://github.com/alphadl/lookahead.pytorch
lion,https://github.com/google/automl/blob/master/lion/lion_pytorch.py
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1188
Best Last Month
.jpg)
Information industry by wittx

Information industry by wittx
Information industry by wittxHigh-Resolution Model for Segmenting and Predicting Brain Tumor Based on Deep UNet with Multi Attent
Information industry by wittxscGPT: Towards Building a Foundation Model for Single-Cell 2 Multi-omics Using Generative AI

Information industry by show
Information industry by wittx
Information industry by wittxAccelerating process development for 3D printing of new metal alloys
Information industry by wittx

Information industry by wittx
.jpg)
Information industry by wittx