-
News Message
Microsoft’s Automatic Prompt Optimization Improves Prompts to Boost LLM Performance
- by wittx 2023-07-15
The recent rise of powerful large language models (LLMs) has revolutionized the field of natural language processing (NLP). The performance of these generative models is largely dependent on users’ prompts, which are becoming increasingly detailed and complex. A Google Trends search reveals a hundredfold increase in popularity for the term “prompt engineering” over the last six months, and social media is teeming with novel prompting tips and templates. Is trial-and-error really the best approach, or could there be a more efficient way to develop effective prompts?
In the new paper Automatic Prompt Optimization with “Gradient Descent” and Beam Search, a Microsoft research team presents Automatic Prompt Optimization (APO), a simple and general prompt optimization algorithm that automatically improves prompts for LLMs, significantly reducing the time and energy spent on manual prompting approaches.
The proposed APO is a general and nonparametric prompt optimization algorithm inspired by numerical gradient descent and designed to automatically optimize prompts. APO connects two existing automated approaches for helping humans write better prompts: 1) training auxiliary models or differentiable representations of the prompt and 2) applying discrete manipulations to prompts through reinforcement learning (RL) or LLM-based feedback.
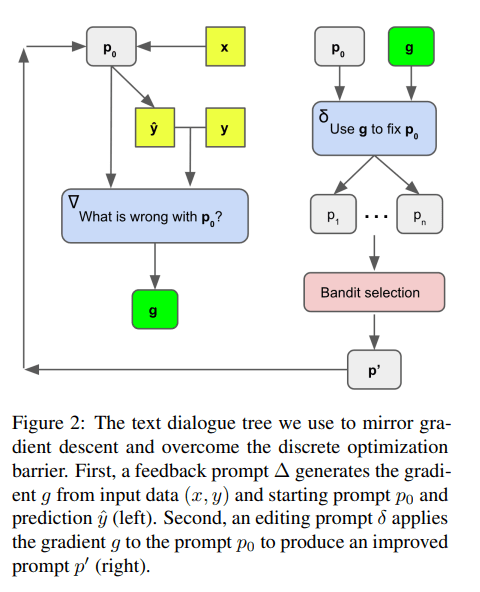
APO differs from these approaches in that it addresses the discrete optimization barrier by applying gradient descent within a text-based Socratic dialogue, replacing differentiation with LLM feedback and backpropagation with LLM editing.
The proposed approach first adopts minibatches of training data to obtain the “gradients” in natural language (descriptions of a given prompt’s flaws), then edits the prompt toward the opposite semantic direction of the gradient. These steps serve as the expansion component of a wider beam search in the space of prompts, such that the task becomes a beam candidate selection problem, which increases algorithmic efficiency.
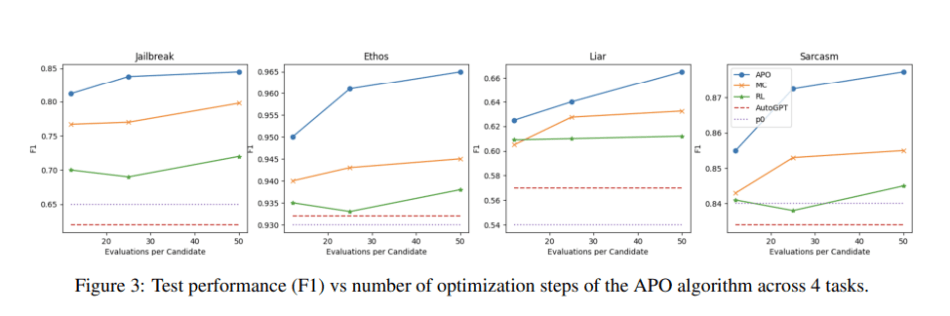
In their empirical study, the team compared their APO framework with three state-of-the-art prompt learning baselines — Monte-Carlo (MC, Zhou et al., 2022), RL, and AutoGPT — across Jailbreak detection, Ethos (hate speech detection, Mollas et al., 2020), Liar (fake news detection, Wang, 2017) and Sarcasm detection (Farha and Magdy, 2020) NLP tasks.
APO surpassed the baselines on all four tasks, improving over MC and RL by a significant 3.9 percent and 8.2 percent, respectively. Moreover, the improvements were achieved without extra hyperparameter tuning or model training, validating the proposed APO’s ability to efficiently and significantly improve prompts.
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1208
Best Last Month
Information industry by wittx
Computer software and hardware by wittx

Traffic by wittxThree Small Stickers in Intersection Can Cause Tesla Autopil

Information industry by wittx

Information industry by wittx
Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx