-
News Message
Gamma分布 Beta分布
- by wittx 2020-09-04
1: 神奇的Gamma函数
- 1.1 Gamma函数
- 1.2 Gamma函数可视化
- 1.3 从二项分布到Gamma函数
2: Beta分布
- 2.1 认识Beta分布
- 2.2 可视化百变星君Beta分布
- 2.3 Beta-Binomial共轭
- 2.4 Beta分布的应用
3: Dirichlet分布
- 3.1 认识Dirichlet分布
- 3.2 可视化Dirichlet分布
- 3.3 Dirichlet-Multinomial共轭
- 3.4 Beta/Dirichlet 分布的一个性质
4: 参考文献
注:本文主要参考了 Rickjin (靳志辉)大神的《LDA数学八卦》前两章内容。
1. 神奇的Gamma函数
1.1 Gamma函数
Gamma函数如下:
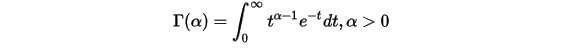
很奇怪,但可以形象理解为用一个伽马刀,对
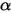 动了一刀,于是指数为
动了一刀,于是指数为  ,动完刀需要扶着梯子
,动完刀需要扶着梯子 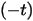 才能走下来(记忆,摘自QUETAL博客)。
才能走下来(记忆,摘自QUETAL博客)。通过分布积分可以得到如下性质:
![\Gamma(\alpha+1)=\int _{0}^{\infty}t^{\alpha}e^{-t}dt=-\int _{0}^{\infty}t^{\alpha}d(e^{-t})=-\left[t^{\alpha}e^{-t}|_{0}^{\infty}-\alpha\int_{0}^{\infty}e^{-t}t^{\alpha-1}dt\right]=\alpha\Gamma(\alpha)\\](/Witty_Finance/images/download/1554175142731_54715.png)
易证明有如下性质: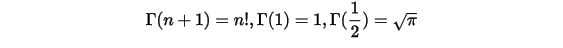
其中还有几个重要的等式,这里就不证明了,有兴趣的可以查找相关资料: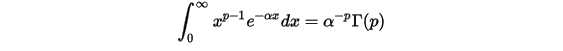
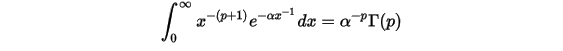
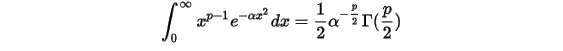
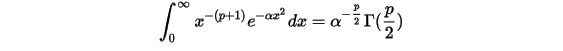
1.2 Gamma函数可视化
import numpy as np from scipy.special import gamma import matplotlib.pyplot as plt fig = plt.figure(figsize=(12,8)) # The Gamma function x = np.linspace(-5, 5, 1000) plt.plot(x, gamma(x), ls='-', c='k', label='$\Gamma(x)$') # (x-1)! for x = 1, 2, ..., 6 x2 = np.linspace(1,6,6) y = np.array([1, 1, 2, 6, 24, 120]) pylab.plot(x2, y, marker='*', markersize=12, markeredgecolor='r', markerfacecolor='r', ls='',c='r', label='$(x-1)!$') plt.title('Gamma Function') plt.ylim(-50,50) plt.xlim(-5, 5) plt.xlabel('$x$') plt.legend() plt.show()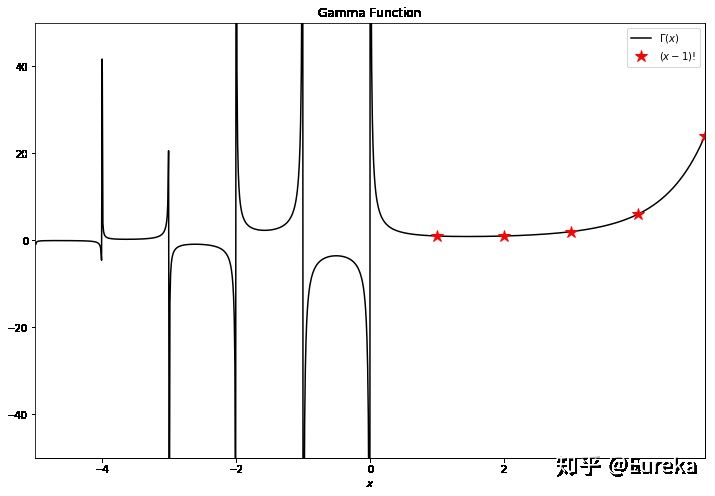
从图可以看出Gamma函数可凸函数,不仅如此,
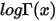 也是凸函数。
也是凸函数。fig = plt.figure(figsize=(12,8)) # The Gamma function x = np.linspace(0, 15, 1000) plt.plot(x, np.log(gamma(x)), ls='-', c='k', label='$log\Gamma(x)$') plt.title('Log$\Gamma(x)$ Function') plt.ylim(-1,50) plt.xlim(-1, 15) plt.xlabel('$x$') plt.legend() plt.show()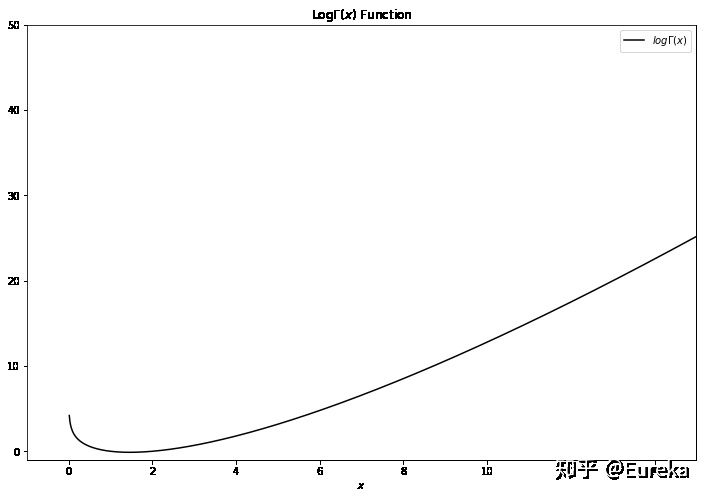
如下函数被称为Digamma函数:
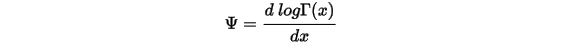
Digamma函数具有如下性质: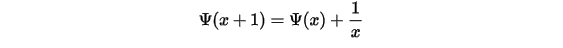
1.3 从二项分布到Gamma函数
对Gamma函数做个变形,可以得到如下式子:
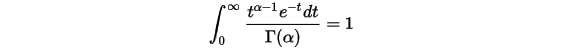
取积分中的函数作为概率密度,就得到一个简单的Gamma分布的密度函数: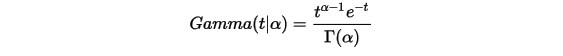
如果做一个变换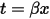 ,就得到Gamma分布的更一般形式:
,就得到Gamma分布的更一般形式: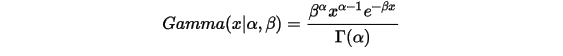
其中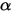 称为shape parameter,主要决定了分布曲线的形状,而
称为shape parameter,主要决定了分布曲线的形状,而 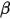 称为rate parameter或inverse scale parameter(
称为rate parameter或inverse scale parameter( 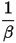 scale parameter),主要决定曲线有多陡。
scale parameter),主要决定曲线有多陡。import numpy as np from scipy.stats import gamma from matplotlib import pyplot as plt alpha_values = [1, 2, 3, 3, 3] beta_values = [0.5, 0.5, 0.5, 1, 2] color = ['b','r','g','y','m'] x = np.linspace(1E-6, 10, 1000) fig, ax = plt.subplots(figsize=(12, 8)) for k, t, c in zip(alpha_values, beta_values, color): dist = gamma(k, 0, t) plt.plot(x, dist.pdf(x), c=c, label=r'$\alpha=%.1f,\ \theta=%.1f$' % (k, t)) plt.xlim(0, 10) plt.ylim(0, 2) plt.xlabel('$x$') plt.ylabel(r'$p(x|\alpha,\beta)$') plt.title('Gamma Distribution') plt.legend(loc=0) plt.show()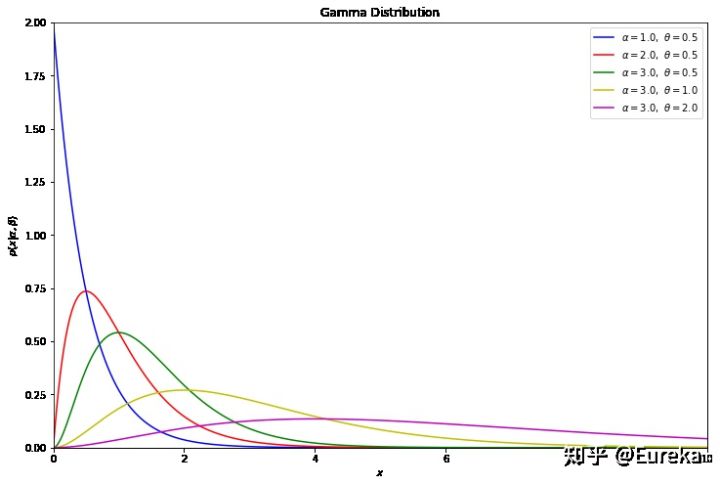
我们可以发现Gamma分布的概率密度和Poisson分布在数学上的形式具有高度的一致性。参数
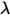 的Poisson分布,概率为:
的Poisson分布,概率为: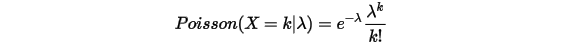
而在Gamma分布的密度函数中取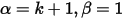 ,可以得到:
,可以得到: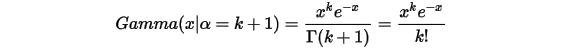
可以看到这两个分布在数学形式上是一致的,只是Poisson分布式离散的,Gamma分布式连续的,可以直观认为,Gamma分布式是Poisson分布在正实数集上连续化版本。我们在概率论与数理统计的课程中都学过,
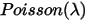 分布可以看成是二项分布
分布可以看成是二项分布 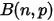 在
在 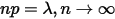 条件下的极限分布:
条件下的极限分布: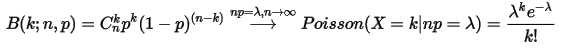
二项分布也满足下面一个奇妙的等式: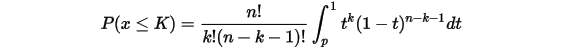
这个分布式反应二项分布和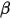 分布的关系,证明后面再讲。
分布的关系,证明后面再讲。我们在右等式做个变换
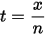
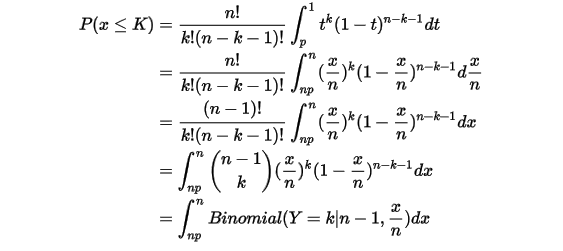
上式左侧是二项分布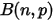 ,而右侧为无穷多个二项分布
,而右侧为无穷多个二项分布 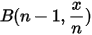 的积分求和,所以可以写为
的积分求和,所以可以写为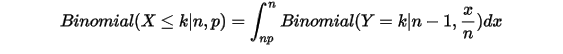
对两边在条件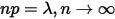 条件下取极限,则左边有
条件下取极限,则左边有 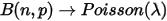 ,而右边有
,而右边有 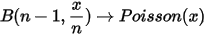 ,所以得到:
,所以得到: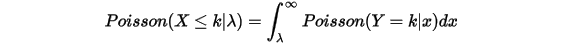
把Poisson分布展开,于是得到: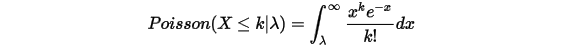
此为Poisson-Gamma duality.我们对上式两边取极限
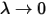 ,左边是Poisson至多发生
,左边是Poisson至多发生 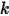 事件的概率,
事件的概率, 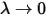 的时候就不可能有事件再发生了,故
的时候就不可能有事件再发生了,故  ,于是:
,于是: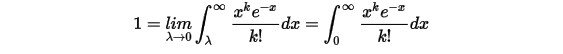
该积分式子说明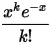 在实数集上是一个概率分布函数,而这个函数恰好就是Gamma分布。我们继续把上式右边中的
在实数集上是一个概率分布函数,而这个函数恰好就是Gamma分布。我们继续把上式右边中的 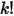 移到左边,于是得到:
移到左边,于是得到: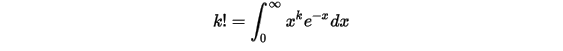
于是我们得到了将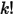 表示为积分的方法。
表示为积分的方法。我们将
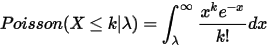 进行变换下:
进行变换下: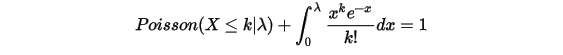
我们可以看到,Poisson分布的概率密度累积函数和Gamma分布的概率密度累积函数有互补的关系。做个小结:我们从二项分布的等式出发,同时利用二项分布的极限是Poisson分布,推导出了Gamma分布,同时把
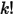 表示成积分形式了。
表示成积分形式了。2. Beta分布
2.1 认识Beta分布
我们将由几个问题来得引出几个分布:
问题一:
1: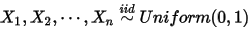
2:把这个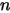 个随机变量排序后得到顺序统计量
个随机变量排序后得到顺序统计量 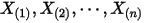
3:问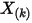 是什么分布
是什么分布首先我们尝试计算
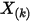 落在一个区间
落在一个区间 ![[x,x+\Delta x]](/Witty_Finance/images/download/1554175160478_13661.png) 的概率,也就是如下概率值:
的概率,也就是如下概率值: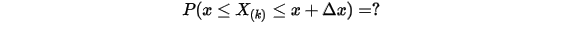
我们可以把![[0,1]](/Witty_Finance/images/download/1554175161144_57216.png) 分成三段
分成三段 ![[0,x),[x,x+\Delta x],(x+\Delta x,1]](/Witty_Finance/images/download/1554175161461_68111.png) 。
。我们考虑第一种情形:假设
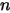 个数中只有一个落在区间
个数中只有一个落在区间 ![[x,x+\Delta x]](/Witty_Finance/images/download/1554175162115_86813.png) 内,则这个区间内的数
内,则这个区间内的数 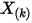 是第
是第 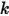 大的,则
大的,则 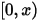 中应该有
中应该有 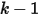 个数,
个数, ![(x+\Delta x,1]](/Witty_Finance/images/download/1554175163579_47223.png) 中有
中有  个数,我们将此描述为事件
个数,我们将此描述为事件 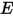 :
:![\begin{align*}E&=\{X_1\in[x,x+\Delta x], \\&X_i\in [0,x)(i=2,\cdots,k) \\&X_j\in (x+\Delta x,1](j=k+1,\cdots,n)\}\end{align*}\\](/Witty_Finance/images/download/1554175164484_17203.png)
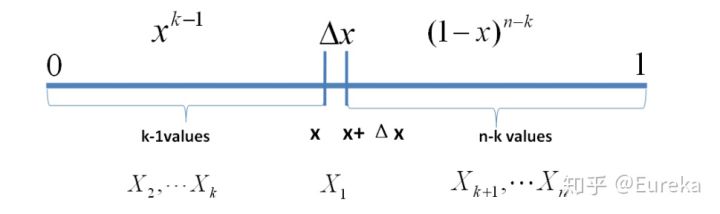
则有:
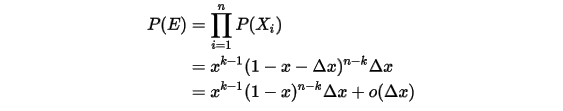
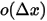 是
是 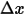 的高阶无穷小。显然
的高阶无穷小。显然 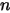 个数落在
个数落在 ![[x,x+\Delta x]](/Witty_Finance/images/download/1554175166126_85402.png) 区间有
区间有 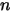 种取法,余下
种取法,余下 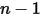 个数中有
个数中有 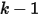 个数落在
个数落在 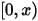 中有
中有 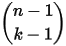 种组合,所以和事件
种组合,所以和事件 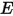 等价的事件一共有
等价的事件一共有 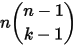 个。
个。考虑第二种情形:假设
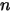 个数中只有两个落在区间
个数中只有两个落在区间 ![[x,x+\Delta x]](/Witty_Finance/images/download/1554175168442_45965.png) 内:
内:![\begin{align*}E'&=\{X_1,X_2\in[x,x+\Delta x], \\&X_i\in [0,x)(i=3,\cdots,k) \\&X_j\in (x+\Delta x,1](j=k+1,\cdots,n)\}\end{align*}\\](/Witty_Finance/images/download/1554175168730_42110.png)
则有: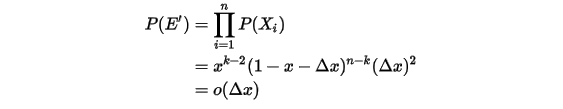
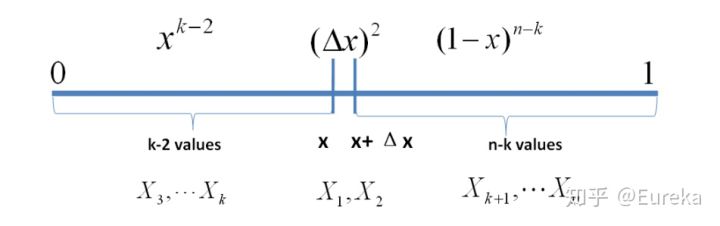
从以上分析可以得到:只要落在
![[x,x+\Delta x]](/Witty_Finance/images/download/1554175169767_67694.png) 内的数字超过一个,则对应的事件的概率就是
内的数字超过一个,则对应的事件的概率就是 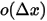 ,于是:
,于是: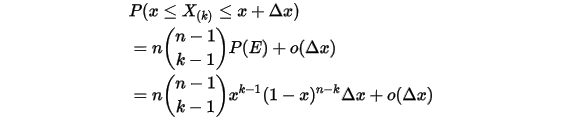
所以得到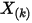 的概率密度函数是:
的概率密度函数是:![\begin{align*}f(x)&=\underset{\Delta x\rightarrow 0}{lim}\frac{P(x\leq X_{(k)}\leq x+\Delta x)}{\Delta x} \\&=n\binom{n-1}{k-1}x^{k-1}(1-x)^{n-k} \\&=\frac{n!}{(k-1)!(n-k)!}x^{k-1}(1-x)^{n-k},x\in[0,1]\end{align*}\\](/Witty_Finance/images/download/1554175171285_40049.png)
我们知道利用Gamma函数可以把很多数学概念从整数集合延拓到实数集合。我们在上式中取
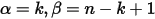 ,于是得到:
,于是得到: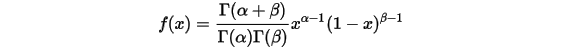
这就是Beta分布了。那么这个游戏里我们取Beta分布的峰值是胜率最大的。
2.2 可视化百变星君Beta分布
import numpy as np from scipy.stats import beta from matplotlib import pyplot as plt alpha_values = [1/3,2/3,1,1,2,2,4,10,20] beta_values = [1,2/3,3,1,1,6,4,30,20] colors = ['tab:blue', 'tab:orange', 'tab:green', 'tab:red', 'tab:purple', 'tab:brown', 'tab:pink', 'tab:gray', 'tab:olive'] x = np.linspace(0, 1, 1002)[1:-1] fig, ax = plt.subplots(figsize=(14,9)) for a, b, c in zip(alpha_values, beta_values, colors): dist = beta(a, b) plt.plot(x, dist.pdf(x), c=c,label=r'$\alpha=%.1f,\ \beta=%.1f$' % (a, b)) plt.xlim(0, 1) plt.ylim(0, 6) plt.xlabel('$x$') plt.ylabel(r'$p(x|\alpha,\beta)$') plt.title('Beta Distribution') ax.annotate('Beta(1/3,1)', xy=(0.014, 5), xytext=(0.04, 5.2), arrowprops=dict(facecolor='black', arrowstyle='-')) ax.annotate('Beta(10,30)', xy=(0.276, 5), xytext=(0.3, 5.4), arrowprops=dict(facecolor='black', arrowstyle='-')) ax.annotate('Beta(20,20)', xy=(0.5, 5), xytext=(0.52, 5.4), arrowprops=dict(facecolor='black', arrowstyle='-')) ax.annotate('Beta(1,3)', xy=(0.06, 2.6), xytext=(0.07, 3.1), arrowprops=dict(facecolor='black', arrowstyle='-')) ax.annotate('Beta(2,6)', xy=(0.256, 2.41), xytext=(0.2, 3.1), arrowprops=dict(facecolor='black', arrowstyle='-')) ax.annotate('Beta(4,4)', xy=(0.53, 2.15), xytext=(0.45, 2.6), arrowprops=dict(facecolor='black', arrowstyle='-')) ax.annotate('Beta(1,1)', xy=(0.8, 1), xytext=(0.7, 2), arrowprops=dict(facecolor='black', arrowstyle='-')) ax.annotate('Beta(2,1)', xy=(0.9, 1.8), xytext=(0.75, 2.6), arrowprops=dict(facecolor='black', arrowstyle='-')) ax.annotate('Beta(2/3,2/3)', xy=(0.99, 2.4), xytext=(0.86, 2.8), arrowprops=dict(facecolor='black', arrowstyle='-')) #plt.legend(loc=0) plt.show()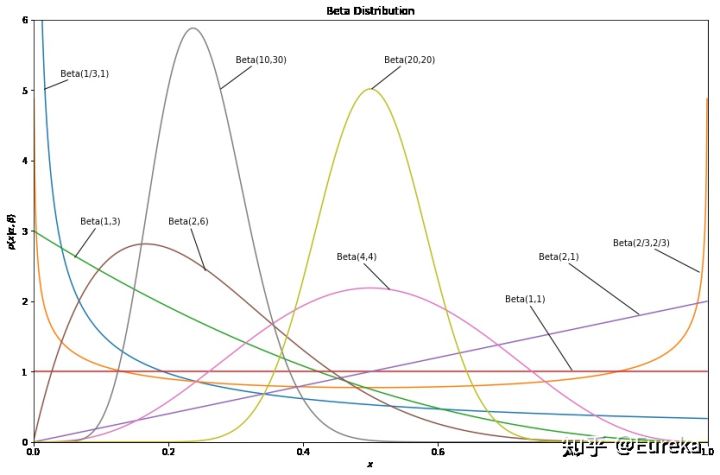
从图中可以看出,Beta分布可以是凹的、凸的、单调上升的、单调下降的;可以是曲线也可以是直线,而均匀分布也特殊的Beta分布。可以尝试改下参数,看看Beta分布的各种形态。
2.3 Beta-Binomial共轭
问题二:
1: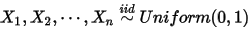 ,排序后对应的顺序统计量
,排序后对应的顺序统计量 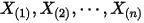 ,我们要猜测
,我们要猜测 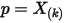 ;
;
2: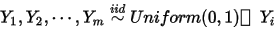 中有
中有 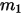 个比
个比 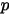 小,
小, 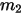 个比
个比 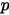 大;
大;
3:问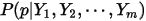 是什么分布
是什么分布由于
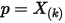 在
在 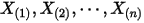 中是第
中是第 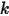 大的,我们容易推得到
大的,我们容易推得到 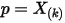 在
在 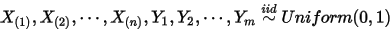 这
这 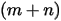 个独立随机变量中是第
个独立随机变量中是第 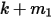 大的。可以按上一节的推导,此时
大的。可以按上一节的推导,此时 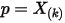 的概率密度是
的概率密度是 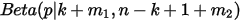 。
。按贝叶斯推导的逻辑:
1):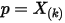 是我们要猜测的参数,我们推导出
是我们要猜测的参数,我们推导出 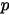 的分布是
的分布是 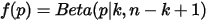 ,称为
,称为 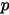 的先验分布。
的先验分布。
2):数据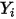 中有
中有 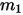 个比
个比 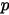 小,
小, 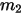 个比
个比 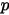 大,
大, 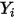 相当于做了
相当于做了 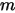 次贝努力实验,所以
次贝努力实验,所以  服从二项分布
服从二项分布 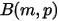 。
。
3):在给定来自数据的提供的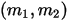 知识后,
知识后, 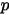 的后验分布为
的后验分布为 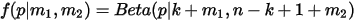
贝叶斯参数估计的基本过程是:
先验分布+数据知识=后验分布
因此可以得到:
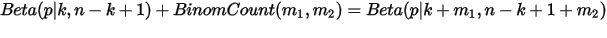
更一般的,对于非负实数
 ,我们有如下关系:
,我们有如下关系: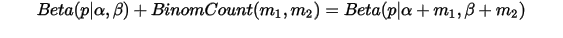
以上式子实际上描述的就是Beta-Binomial共轭。共轭意思是先验和后验都服从同一个分布形式。这种形式不变,我们能够在先验分布中赋予参数很明确的物理意义,这个物理意义可以延伸到后验分布中进行解释,同时从先验变换到后验的过程中从数据中补充的知识也容易有物理解释。(我感觉有共轭后计算更容易哈,因为形式都知道了,其他的就是凑参数了。还有另一个好处是:每当有新的观测数据,就把上次的后验概率作为先验概率,乘以新数据的likelihood,然后就得到新的后验概率,而不必用先验概率乘以所有数据的likelihood得到后验概率。)
从前面的过程中可以知道,Beta分布中的参数
 也可以理解为物理计数,这两个参数经常被称为伪计数(pseudo-count)。基于以上逻辑,我们可以把
也可以理解为物理计数,这两个参数经常被称为伪计数(pseudo-count)。基于以上逻辑,我们可以把 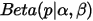 写成下式来理解:
写成下式来理解: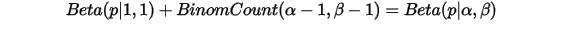
其中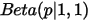 恰好的均匀分布
恰好的均匀分布 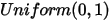 。
。对于上式,可以从贝叶斯角度来理解。假设有一个不均匀的硬币抛出正面的概率是
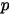 ,抛
,抛 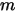 次后得到正面和反面的次数分别为
次后得到正面和反面的次数分别为 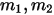 次,那按传统概率学派的观点,
次,那按传统概率学派的观点, 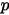 的估计是
的估计是 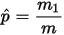 。而从贝叶斯学派的角度来看,开始对硬币的不均匀性一无所知,所以假设
。而从贝叶斯学派的角度来看,开始对硬币的不均匀性一无所知,所以假设 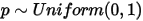 ,于是有了二项分布的计数
,于是有了二项分布的计数 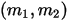 后,按照贝叶斯的公式计算
后,按照贝叶斯的公式计算 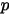 的后验分布:
的后验分布: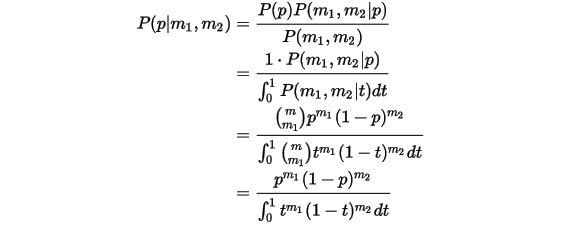
计算得到后验分布为正好是: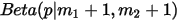
前面从二项分布推导Gamma分布的时候,使用了如下等式:
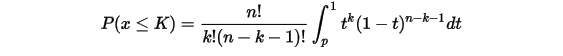
左边是二项分布的概率累积,右边是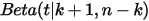 分布的概率累积。现在我们来证明这个等式。
分布的概率累积。现在我们来证明这个等式。我们构造如下二项分布,取随机变量
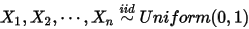 ,一个成功的贝努力实验就是
,一个成功的贝努力实验就是 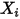
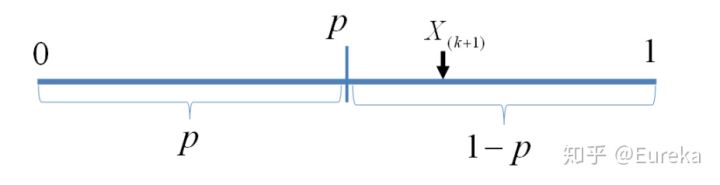
我们可以得到:
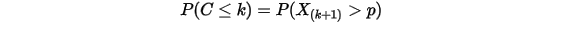
此处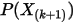 是顺序统计量,为第
是顺序统计量,为第 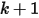 大的数。上述等式意思是:成功至多
大的数。上述等式意思是:成功至多 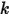 次等于第
次等于第 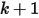 大的数必定失败(即失败至少
大的数必定失败(即失败至少  次)。由于
次)。由于 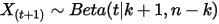 ,于是
,于是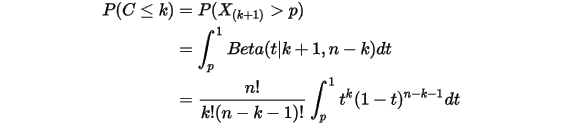
2.4 Beta分布的应用
1. 棒球击球率
那么我们简单说个Beta-Binomial共轭的应用。用一句话来说,beta分布可以看作一个概率的概率分布,当你不知道一个东西的具体概率是多少时,它可以给出了所有概率出现的可能性大小。
举一个简单的例子,熟悉棒球运动的都知道有一个指标就是棒球击球率(batting average),就是用一个运动员击中的球数除以击球的总数,我们一般认为0.266是正常水平的击球率,而如果击球率高达0.3就被认为是非常优秀的。现在有一个棒球运动员,我们希望能够预测他在这一赛季中的棒球击球率是多少。传统的频率学派会直接计算棒球击球率,用击中的数除以击球数,但是如果这个棒球运动员只打了一次,而且还命中了,那么他就击球率就是100%了,这显然是不合理的,因为根据棒球的历史信息,我们知道这个击球率应该是0.215到0.36之间才对。对于这个问题,我们可以用一个二项分布表示(一系列成功或失败),一个最好的方法来表示这些经验(在统计中称为先验信息)就是用beta分布,这表示在我们没有看到这个运动员打球之前,我们就有了一个大概的范围。beta分布的定义域是
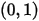 这就跟概率的范围是一样的。接下来我们将这些先验信息转换为beta分布的参数,我们知道一个击球率应该是平均0.27左右,而他的范围是0.21到0.35,那么根据这个信息,我们可以取
这就跟概率的范围是一样的。接下来我们将这些先验信息转换为beta分布的参数,我们知道一个击球率应该是平均0.27左右,而他的范围是0.21到0.35,那么根据这个信息,我们可以取 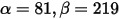 。(这样取值可以从Beta的均值和分布考虑)
。(这样取值可以从Beta的均值和分布考虑)import numpy as np from scipy.stats import beta from matplotlib import pyplot as plt x = np.linspace(0, 1, 1002)[1:-1] fig, ax = plt.subplots(figsize=(10,6)) dist = beta(81, 219) plt.plot(x, dist.pdf(x), c='b',label=r'$\alpha=%.1f,\ \beta=%.1f$' % (81, 219)) plt.xlim(0, .6) plt.ylim(0, 16) plt.xlabel('$x$') plt.ylabel(r'$p(x|\alpha,\beta)$') plt.title('Beta Distribution') plt.legend(loc=0) plt.show()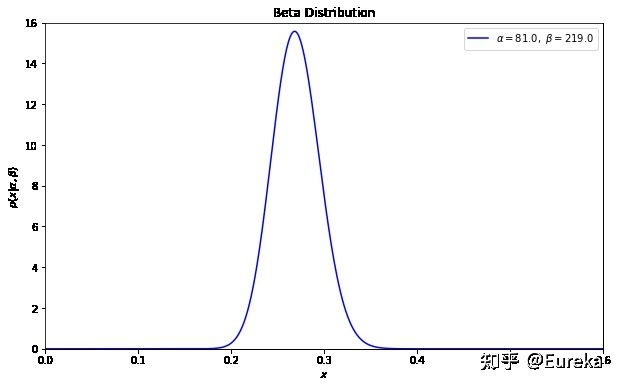
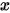 轴表示各个击球率的取值,
轴表示各个击球率的取值, 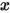 对应的
对应的 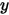 值就是这个击球率所对应的概率。也就是说beta分布可以看作一个概率的概率分布。
值就是这个击球率所对应的概率。也就是说beta分布可以看作一个概率的概率分布。那么有了先验信息后,现在我们考虑一个运动员只打一次球,那么他现在的数据就是”1中;1击”。这时候我们就可以更新我们的分布了,让这个曲线做一些移动去适应我们的新信息。因beta分布与二项分布是共轭先验的(Conjugate_prior)。那么后验是:
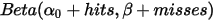 。
。其中
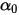 和
和 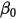 是一开始的参数,在这里是81和219。所以在这一例子里,
是一开始的参数,在这里是81和219。所以在这一例子里, 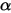 增加了1(击中了一次)。
增加了1(击中了一次)。 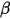 没有增加(没有漏球)。这就是我们的新的beta分布
没有增加(没有漏球)。这就是我们的新的beta分布 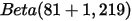 。
。import numpy as np from scipy.stats import beta from matplotlib import pyplot as plt x = np.linspace(0, 1, 1002)[1:-1] fig, ax = plt.subplots(figsize=(10,6)) dist = beta(81, 219) plt.plot(x, dist.pdf(x), c='b',label=r'$\alpha=%.1f,\ \beta=%.1f$' % (81, 219)) dist = beta(82, 219) plt.plot(x, dist.pdf(x), c='r',label=r'$\alpha=%.1f,\ \beta=%.1f$' % (82, 219)) plt.xlim(0, .6) plt.ylim(0, 16) plt.xlabel('$x$') plt.ylabel(r'$p(x|\alpha,\beta)$') plt.title('Beta Distribution') plt.legend(loc=0) plt.show()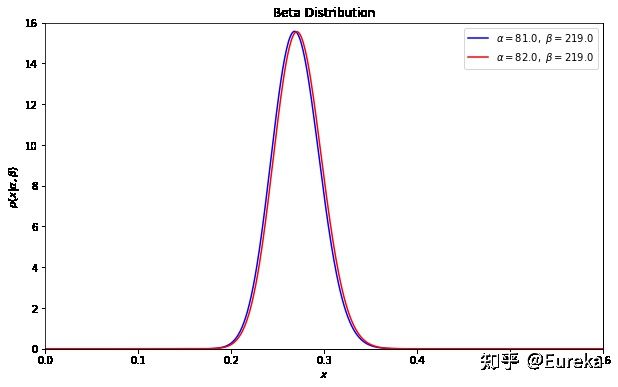
可以看到这个分布其实没多大变化,这是因为只打了1次球并不能说明什么问题。但是如果我们得到了更多的数据,假设一共打了300次,其中击中了100次,200次没击中,那么这一新分布就是:
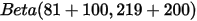
import numpy as np from scipy.stats import beta from matplotlib import pyplot as plt x = np.linspace(0, 1, 1002)[1:-1] fig, ax = plt.subplots(figsize=(10,6)) dist = beta(81, 219) plt.plot(x, dist.pdf(x), c='b',label=r'$\alpha=%.1f,\ \beta=%.1f$' % (81, 219)) dist = beta(181, 419) plt.plot(x, dist.pdf(x), c='r',label=r'$\alpha=%.1f,\ \beta=%.1f$' % (181, 419)) plt.xlim(0, .6) plt.ylim(0, 22) plt.xlabel('$x$') plt.ylabel(r'$p(x|\alpha,\beta)$') plt.title('Beta Distribution') plt.legend(loc=0) plt.show()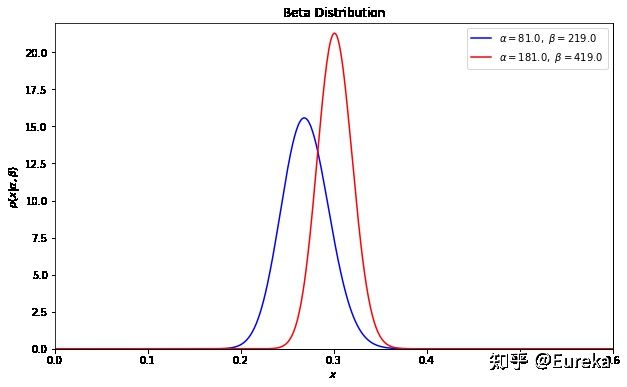
注意到这个曲线变得更加尖,并且平移到了一个右边的位置,表示比平均水平要高。
一个有趣的事情是,根据这个新的beta分布,我们可以得出他的数学期望为:
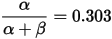 ,这一结果要比直接的估计要小
,这一结果要比直接的估计要小 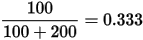 。你可能已经意识到,我们事实上就是在这个运动员在击球之前可以理解为他已经成功了81次,失败了219次这样一个先验信息。
。你可能已经意识到,我们事实上就是在这个运动员在击球之前可以理解为他已经成功了81次,失败了219次这样一个先验信息。因此,对于一个我们不知道概率是什么,而又有一些合理的猜测时,beta分布能很好的作为一个表示概率的概率分布。
2. A/B测试
前面已大概了解了Beta分布的简单应用,我们再来深入了解下。
关于
 测试,其实概念非常简单,简单来说,就是为同一个目标制定两个方案(比如两个页面),让一部分用户使用
测试,其实概念非常简单,简单来说,就是为同一个目标制定两个方案(比如两个页面),让一部分用户使用  方案,另一部分用户使用
方案,另一部分用户使用  方案,记录下用户的使用情况,看哪个方案更符合设计。
方案,记录下用户的使用情况,看哪个方案更符合设计。 方案的转化率可以看作一个二项分布:
方案的转化率可以看作一个二项分布: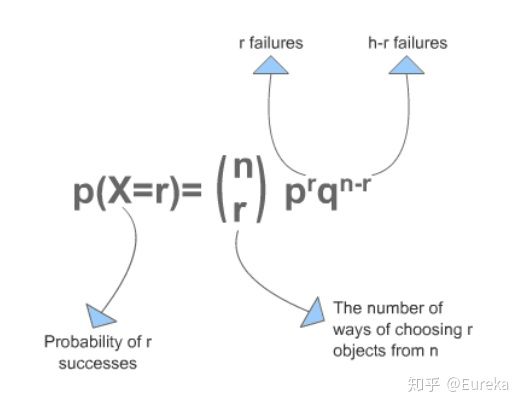
A方案的转化率分布就需要一个分布参数
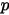 ,表示转化率的可能性。同样传统的频率学派会把实验总数中所有转化率的总数除以实验总数,得到这个
,表示转化率的可能性。同样传统的频率学派会把实验总数中所有转化率的总数除以实验总数,得到这个 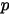 。以这个
。以这个 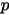 为峰值获得一个类似高斯分布。贝叶斯学派不会假设
为峰值获得一个类似高斯分布。贝叶斯学派不会假设 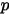 是固定不变的,他们会引入一个Beta分布作为二项分布的共轭先验,通过调整Beta分布参数,动态调整
是固定不变的,他们会引入一个Beta分布作为二项分布的共轭先验,通过调整Beta分布参数,动态调整 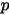 的值。
的值。通过前面我们已经知道
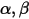 的含义,
的含义, 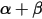 是实验的总次数,
是实验的总次数, 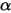 与
与  分别是实验不同结果的次数。下面我们看看
分别是实验不同结果的次数。下面我们看看 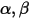 同比例增加会出现什么情况。
同比例增加会出现什么情况。import numpy as np from scipy.stats import beta from matplotlib import pyplot as plt x = np.linspace(0, 1, 1002)[1:-1] fig, ax = plt.subplots(figsize=(10,6)) dist = beta(16, 84) plt.plot(x, dist.pdf(x), c='b',label=r'$\alpha=%.1f,\ \beta=%.1f$' % (16, 84)) dist = beta(8, 42) plt.plot(x, dist.pdf(x), c='r',label=r'$\alpha=%.1f,\ \beta=%.1f$' % (8, 42)) plt.xlim(0, .5) plt.ylim(0, 13) plt.xlabel('$x$') plt.ylabel(r'$p(x|\alpha,\beta)$') plt.title('Beta Distribution') plt.legend(loc=0) plt.show()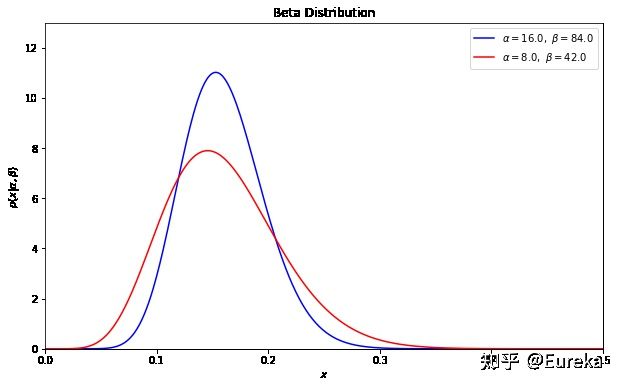
假设上图是一枚硬币抛100次有16次正面,和抛50次有8次正面的两个实验各自的Beta分布,可以看到虽然只是实验规模不同,但是分布密度图是不一样的:
第一:频率学派观点是应该猜测正面概率p=0.16;贝叶斯学派观点是,以上两种情况的猜测到正面概率都小于0.16,因为实验次数越少,真实的正面和反面的差距就可能越大!
第二:实验次数越小,上面概率密度图应该越平缓(红线),因为少的实验次数不能增大决策信心。而蓝色的100次实验,明显有更大的信心猜测正面概率更接近0.16.
第三:实验次数越大,上面概率密度图的均值更应该接近0.16,符合大数定律。
是不是相当合理!
from scipy.stats import beta import matplotlib.pyplot as plt import numpy as np import pandas as pd import seaborn as sns #考虑50人有8人转化成功 people_in_branch = 50 #控制组与实验组 control, experiment = np.random.rand(2, people_in_branch) #控制组转化率是16% c_successes = sum(control < 0.16) #实验组要比控制组好10% e_successes = sum(experiment < 0.176) c_failures = people_in_branch - c_successes e_failures = people_in_branch - e_successes #先验 prior_successes = 8 prior_failures = 42 fig, ax = plt.subplots(figsize=(12,8)) #控制组 c_alpha, c_beta = c_successes + prior_successes, c_failures + prior_failures #实验组 e_alpha, e_beta = e_successes + prior_successes, e_failures + prior_failures x = np.linspace(0., 0.5, 1000) c_distribution = beta(c_alpha, c_beta) e_distribution = beta(e_alpha, e_beta) ax.plot(x, c_distribution.pdf(x),label='Control') ax.plot(x, e_distribution.pdf(x),label='Experient') plt.legend() ax.set(xlabel='conversion rate', ylabel='density') plt.show()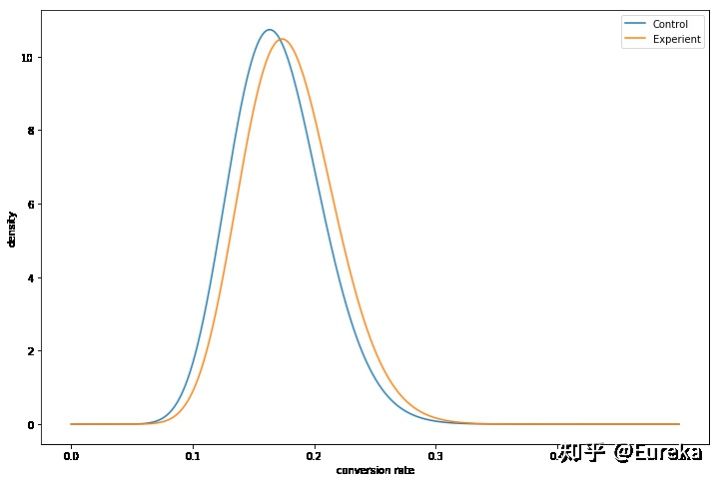
上图很多都重叠,我们无法说那个更好,下面我们增加数据量来得到更精确的信息:
#增加到4000人 more_people_in_branch = 4000 #控制组与实验组 control, experiment = np.random.rand(2, more_people_in_branch) #加上已有的数据 c_successes += sum(control < 0.16) e_successes += sum(experiment < 0.176) c_failures += more_people_in_branch - sum(control < 0.16) e_failures += more_people_in_branch - sum(experiment < 0.176) fig, ax = plt.subplots(figsize=(12,8)) #控制组 c_alpha, c_beta = c_successes + prior_successes, c_failures + prior_failures #实验组 e_alpha, e_beta = e_successes + prior_successes, e_failures + prior_failures x = np.linspace(0., 0.5, 1000) # Generate and plot the distributions! c_distribution = beta(c_alpha, c_beta) e_distribution = beta(e_alpha, e_beta) ax.plot(x, c_distribution.pdf(x),label='Control') ax.plot(x, e_distribution.pdf(x),label='Experient') plt.legend() ax.set(xlabel='conversion rate', ylabel='density') plt.show()
可以看出实验组要更好,又更高的转化率。
3: Dirichlet分布
3.1 认识Dirichlet分布
问题三:
1.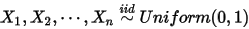 ;
;
2. 排序后对应的顺序统计量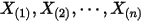 ;
;
3. 问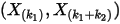 的联合分布是什么
的联合分布是什么
同上面的推导:
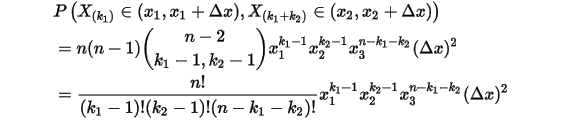
得到
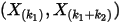 的联合分布:
的联合分布: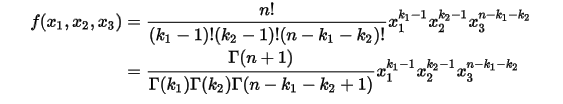
上面这个分布其实就是3维形式的Dirichlet分布
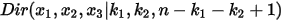 。令
。令 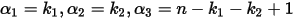 ,于是概率密度函数:
,于是概率密度函数: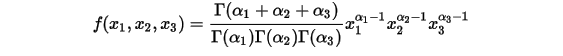
其中
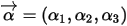 延拓到非负实数集合,以上概率分布也是良定义的。
延拓到非负实数集合,以上概率分布也是良定义的。3.2 可视化Dirichlet分布
Dirichlet概率密度函数定义:一个连续随机向量
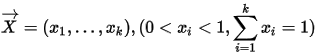 , 的
, 的 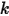 维Dirchlet分布,参数为
维Dirchlet分布,参数为 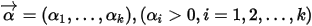 ,它的概率密度函数如下:
,它的概率密度函数如下: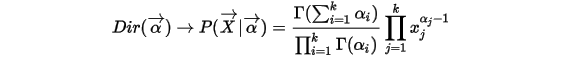
其中
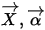 维数是一样的。
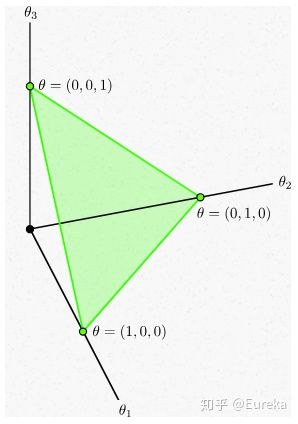
维数是一样的。由于Dirichlet分布描述的是多个定义于区间
![[0,1]](/Witty_Finance/images/download/1554175207806_84416.png) 的随机变量的概率分布,所以通常将其用作多项分布参数
的随机变量的概率分布,所以通常将其用作多项分布参数 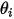 的概率分布。
的概率分布。下面考虑个三维的多项式分布,参数
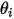 在如下平面上(2-simplex):
在如下平面上(2-simplex):下面我们可视化Dirichlet概率密度函数,当
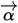 给定时,看看
给定时,看看 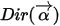 在2-simplex上如何变化。
在2-simplex上如何变化。%matplotlib inline import numpy as np import matplotlib.pyplot as plt import matplotlib.tri as tri #生成等边三角形 corners = np.array([[0, 0], [1, 0], [0.5, 0.75**0.5]]) triangle = tri.Triangulation(corners[:, 0], corners[:, 1]) #每条边中点位置 midpoints = [(corners[(i + 1) % 3] + corners[(i + 2) % 3]) / 2.0 for i in range(3)] def xy2bc(xy, tol=1.e-3): #将三角形顶点的笛卡尔坐标映射到重心坐标系 s = [(corners[i] - midpoints[i]).dot(xy - midpoints[i]) / 0.75 for i in range(3)] return np.clip(s, tol, 1.0 - tol) #有了重心坐标,可以计算Dirichlet概率密度函数的值 class Dirichlet(object): def __init__(self, alpha): from math import gamma from operator import mul from functools import reduce self._alpha = np.array(alpha) self._coef = gamma(np.sum(self._alpha)) / reduce(mul, [gamma(a) for a in self._alpha]) #reduce:sequence连续使用function def pdf(self, x): #返回概率密度函数值 from operator import mul from functools import reduce return self._coef * reduce(mul, [xx ** (aa - 1) for (xx, aa)in zip(x, self._alpha)]) def draw_pdf_contours(dist, nlevels=200, subdiv=8, **kwargs): import math #细分等边三角形网格 refiner = tri.UniformTriRefiner(triangle) trimesh = refiner.refine_triangulation(subdiv=subdiv) pvals = [dist.pdf(xy2bc(xy)) for xy in zip(trimesh.x, trimesh.y)] plt.tricontourf(trimesh, pvals, nlevels, **kwargs) plt.axis('equal') plt.xlim(0, 1) plt.ylim(0, 0.75**0.5) plt.axis('off')让我们看看几个对称的Dirichlet分布,第一个
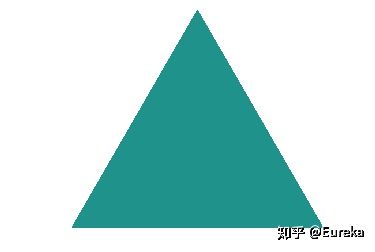
![\alpha=[1, 1, 1]](/Witty_Finance/images/download/1554175209361_37420.png) 产生一个均匀分布,所有点在simplex上概率相同。
产生一个均匀分布,所有点在simplex上概率相同。draw_pdf_contours(Dirichlet([1, 1, 1]))对于
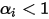 ,分布集中在角落和和simplex边界。(黄色概率最大,蓝色概率最小)
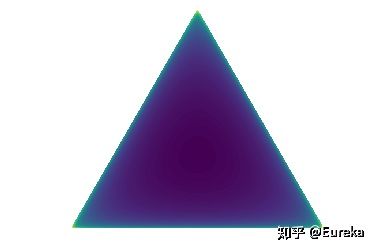
,分布集中在角落和和simplex边界。(黄色概率最大,蓝色概率最小)draw_pdf_contours(Dirichlet([0.999, 0.999, 0.999]))对于
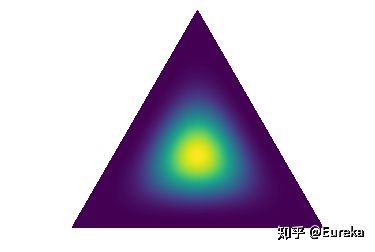
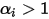 ,分布集中在simplex中心。
,分布集中在simplex中心。draw_pdf_contours(Dirichlet([5, 5, 5]))随着
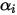 的增大,分布更加集中在simplex的中心
的增大,分布更加集中在simplex的中心draw_pdf_contours(Dirichlet([50, 50, 50]))当
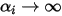 ,多项式分布的参数值将相等。
,多项式分布的参数值将相等。对于不对成的Dirichlet分布,如下
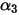 较其他值更大。
较其他值更大。draw_pdf_contours(Dirichlet([30, 30, 50]))下面看看
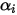 的其他变化。
的其他变化。draw_pdf_contours(Dirichlet([1, 2, 3]))draw_pdf_contours(Dirichlet([2, 5, 15]))3.3 Dirichlet-Multinomial共轭
问题四:
1.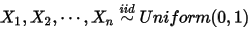 ,排序后对应的顺序统计量
,排序后对应的顺序统计量 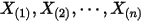 ;
;
2. 令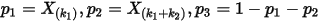 ,我们要猜测
,我们要猜测 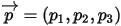 ;
;
3.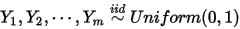 ,
, 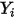 中落到
中落到 ![[0,p_1),[p_1,p_2),[p_2,1]](/Witty_Finance/images/download/1554175213665_78506.png) 三个区间的个数分别是
三个区间的个数分别是 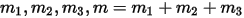 ;
;
4. 问后验分布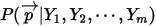 的分布是什么
的分布是什么为了方便我们记:
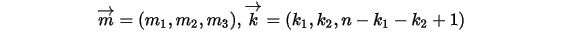
我们可以推理得到
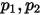 在
在  ,这
,这  个数中分别成为了第
个数中分别成为了第 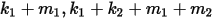 大的数。于是后验分布
大的数。于是后验分布 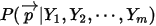 应该是
应该是 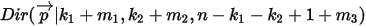 ,即
,即 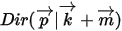 。
。按贝叶斯推导的逻辑:
1):我们要猜测的参数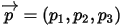 ,
, 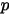 的先验分布为
的先验分布为 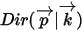 ;
;
2):数据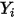 落到
落到 ![[0,p_1),[p_1,p_2),[p_2,1]](/Witty_Finance/images/download/1554175218153_18595.png) 三个区间的个数分别是
三个区间的个数分别是 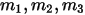 ,所以
,所以 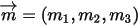 服从多项分布
服从多项分布 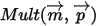 。
。
3):在给定来自数据的提供的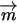 知识后,
知识后, 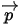 的后验分布为
的后验分布为 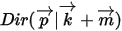
以上贝叶斯分析过程的简单表述为:
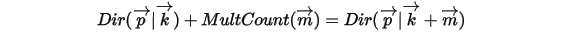
令
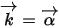 ,把
,把  从整数集合延拓到实数集合,更一般的可以证明有如下关系:
从整数集合延拓到实数集合,更一般的可以证明有如下关系: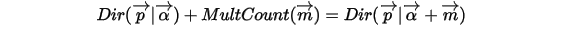
以上式子实际上描述的就是Dirichlet-Multinomial共轭,而我们从以上过程可以看到,Dirichlet分布中的参数
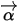 都可以理解为物理计数。类似于Beta分布,我们也可以把
都可以理解为物理计数。类似于Beta分布,我们也可以把 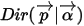 作如下分解:
作如下分解: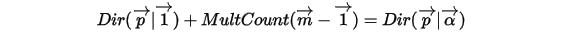
此处
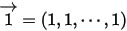 。
。当然对于高维的Dirichlet与Multinomial也共轭。
Dirichlet分布是分布的分布的原因:前面知道Dirichlet分布得到的向量各个分量的和是1,这个向量可以作为Multinomial分布的参数,所以我们说Dirichlet能够生成Multinomial分布,也就是分布的分布。Dirichlet分布和Multinomial分布式共轭的,所以Dirichlet和Multinomial这个组合总是经常被使用,Dirichlet分布在这里的角色就是分布的分布(Multinomial分布的分布)。在可视化部分也可以看到,Dirichlet不同的参数,Dirichlet分布得到的向量值不一样,可以对称,也可以不是对称的。
3.4 Beta/Dirichlet 分布的一个性质
如果
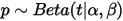 ,则:
,则: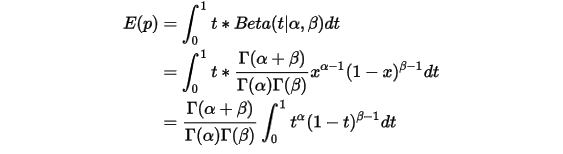
上式右边的积分对应到概率分布
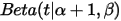 ,对于这个分布,我们有:
,对于这个分布,我们有: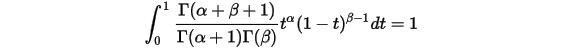
把上式带入
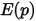 的计算式,得到
的计算式,得到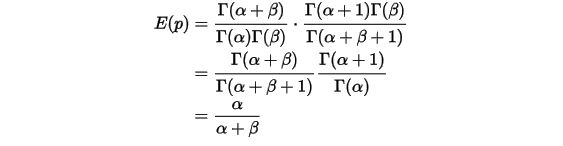
这说明,对于Beta分布的随机变量,其均值可以用
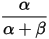 来估计。Dirichlet分布也有类似的结论,如果
来估计。Dirichlet分布也有类似的结论,如果 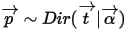 ,同样可以证明:
,同样可以证明:
4:参考文献
LDA-math-认识Beta/Dirichlet分布 | 统计之都
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=145
Best Last Month

Information industry by wittx
Computer software and hardware by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx
Information industry by wittx

Information industry by wittx
Information industry by wittx

Information industry by wittx
Medical science by wittx