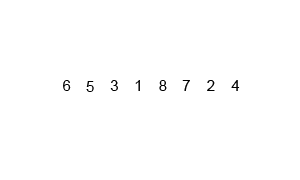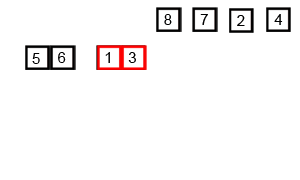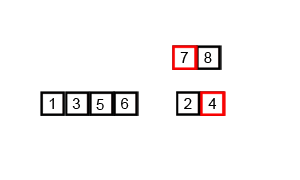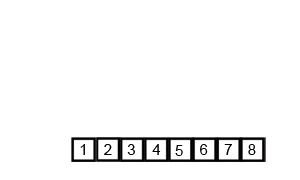-
News Message
线性时间排序
- by wittx 2021-02-15
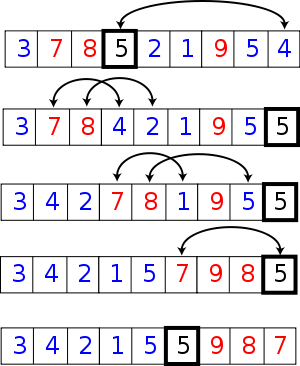
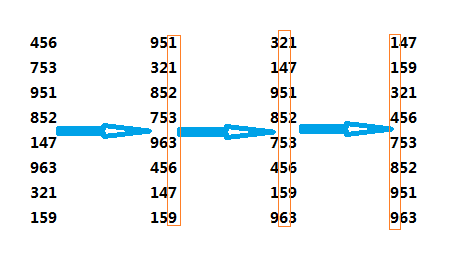
插入排序
在该系列的【算法】1中我们便介绍了这个基本的算法,它的比较过程如下:
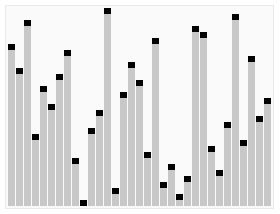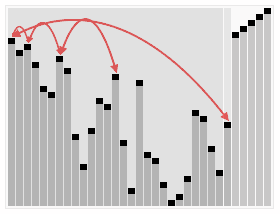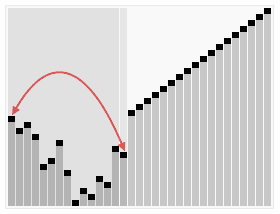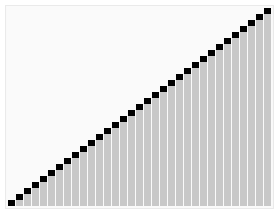
以下是用插入排序对30个元素的数组进行排序的动画:
选择排序
选择排序的比较过程如下:
其动画效果如下:
归并排序
前面多次写到归并排序,它的比较过程如下:
归并排序的动画如下:
堆排序
在该系列的【算法】4中我们便介绍了快排,构建堆的过程如下:
堆排序的动画如下:
快速排序
在该系列的【算法】5中我们便介绍了快排,它的比较过程如下:
快速排序的动画如下:
另外一些比较排序
以下这些排序同样也是比较排序,但该系列中之前并未提到。
Intro sort
该算法是一种混合排序算法,开始于快速排序,当递归深度超过基于正在排序的元素数目的水平时便切换到堆排序。它包含了这两种算法优良的部分,它实际的性能相当于在典型数据集上的快速排序和在最坏情况下的堆排序。由于它使用了两种比较排序,因而它也是一种比较排序。
冒泡排序
大家应该多少都听过冒泡排序(也被称为下沉排序),它是一个非常基本的排序算法。反复地比较相邻的两个元素并适当的互换它们,如果列表中已经没有元素需要互换则表示该列表已经排好序了。(看到列表就想到半年前在学的Scheme,欢迎大家也去看看,我开了2个专栏来介绍它们)
上面的描述中已经体现了比较的过程,因而冒泡排序也是一个比较排序,较小的元素被称为“泡(Bubble)”,它将“浮”到列表的顶端。
尽管这个算法非常简单,但大家应该也听说了,它真的非常的慢。
冒泡排序的过程如下:
冒泡排序的动画演示:
其最好情况、最坏情况的运行时间分别是:、。
奇偶排序
奇偶排序和冒泡排序有很多类似的特点,它通过比较在列表中所有的单双号索引的相邻元素,如果有一对是错误排序(也就是前者比后者大),那么将它们交换,之后不断的重复这一步骤,直到整个列表排好序。
而鉴于此,它的最好情况、最坏情况的运行时间均和冒泡排序相同:、。
奇偶排序的演示如下:
下面是C++中奇偶排序的示例:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
双向冒泡排序
双向冒泡排序也被称为鸡尾酒排序、鸡尾酒调酒器排序、摇床排序、涟漪排序、洗牌排序、班车排序等。(再多再华丽丽的名字也难以弥补它的低效)
和冒泡排序的区别在于它是在两个方向上遍历列表进行排序,虽然如此但并不能提高渐近性能,和插入排序比起来也没太多优势。
它的最好情况、最坏情况的运行时间均和冒泡排序相同:、。
排序算法的下界
我们可以将排序操作进行得多块?
这取决于计算模型,模型简单来说就是那些你被允许的操作。
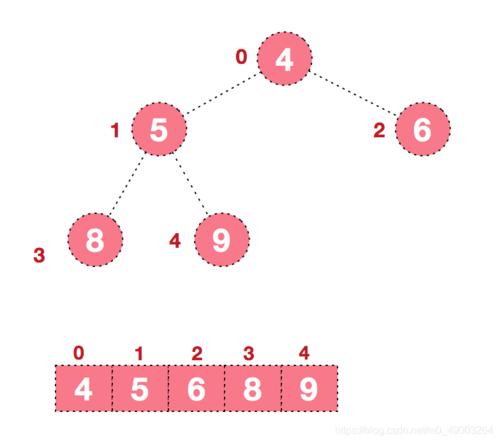
决策树
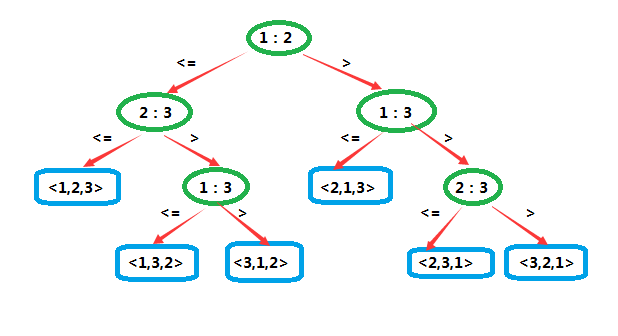
决策树(decision tree)是一棵完全二叉树,它可以表示在给定输入规模情况下,其一特定排序算法对所有元素的比较操作。其中的控制、数据移动等其他操作都被忽略了。
这是一棵作用于3个元素时的插入排序的决策树。标记为的内部结点表示和之间的比较。
由于它作用于3个元素,因此共有种可能的排列。也正因此,它并不具有一般性。
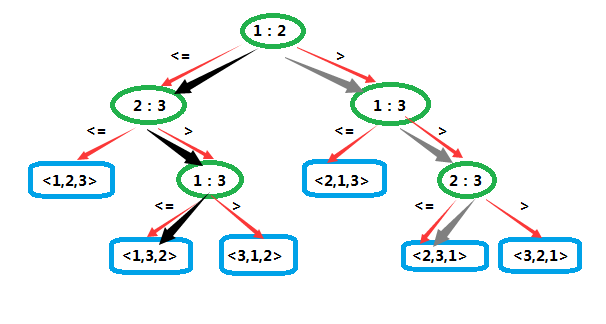
而对序列<script type="math/tex" id="MathJax-Element-11"> </script>和序列 <script type="math/tex" id="MathJax-Element-12"> </script>进行排序时所做的决策已经由灰色和黑色粗箭头指出了。
决策树排序的下界
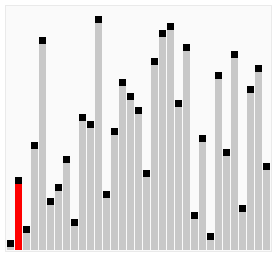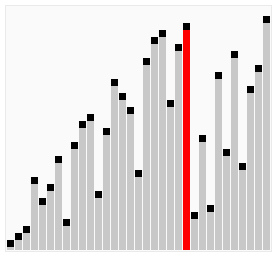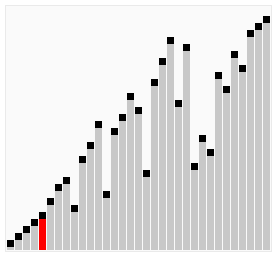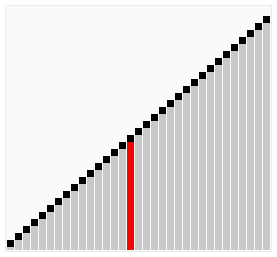
如果决策树是针对n个元素排序,那么它的高度至少是。
在最坏情况下,任何比较排序算法都需要做次比较。
因为输入数据的种可能的排列都是叶结点,所以,由于在一棵高位的二叉树中,叶结点的数目不多于,所以有:
对两边取对数:
=>
=>
又因为:
所以:
因为堆排序和归并排序的运行时间上界均为,因此它们都是渐近最优的比较排序算法。
线性时间排序
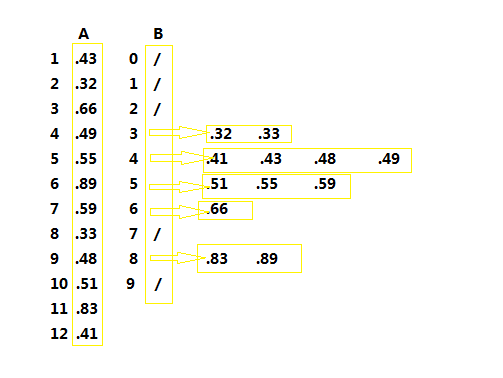
计数排序
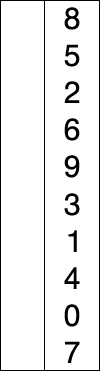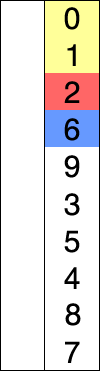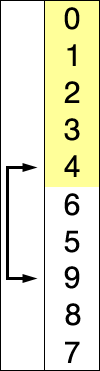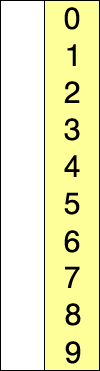
计数排序(counting sort)的思路很简单,就是确定比x小的数有多少个。加入有10个,那么x就排在第11位。
严谨来讲,在计算机科学中,计数排序是一个根据比较键值大小的排序算法,它也是一个整数排序算法。它通过比较对象的数值来操作,并通过这些计数来确定它们在即将输出的序列中的位置。它的运行时间是线性的且取决于最大值和最小值之间的差异,当值的变化明显大于数目时就不太适用了。而它也可以作为基排序的子程序。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
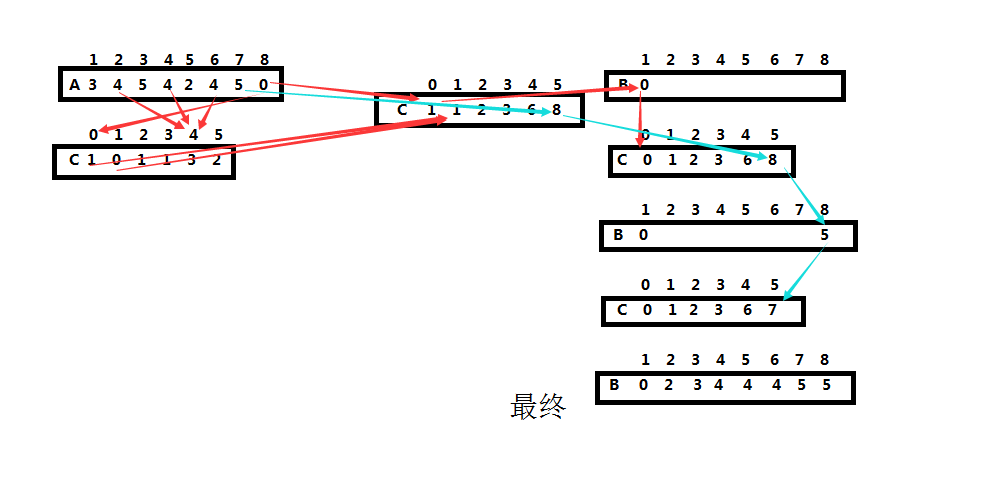
第2-3步,C数组的元素被全部初始化为0,此时耗费时间。
第4-5步,也许不太好想象,其实就是在C数组中来计数A数组中的数。比如说,数组中元素”3”有4个,那么。此时耗费时间。
第7-8步,也是不太好想象的计算,也就是说如果、,那么计算后的不变,。此时耗费时间。
第10-12步,把每个元素放到它在输出数组中的合适位置。比如此时的第一次循环,先找到,然后找到的值,此时的意义就在于应在B数组中的位置。完成这一步后将的值减一,因为它只是一个计数器。这里耗费的时间为。
当时,计数排序的运行时间为。
基数排序
基数排序(radix sort)是一个古老的算法,它用于卡片排序机上。说来也巧,写这篇博客的前一天晚上还在书上看到这种机器,它有80列,每一列都有12个孔可以打。
它可以使用前面介绍的计数排序作为子程序,然而它并不是原址排序;相比之下,很多运行时间为的比较排序却是原址排序。因此当数据过大而内存不太够时,使用它并不是一个明智的选择。
关键在于依次对从右往左每一列数进行排序,其他的列也相应移动。
桶排序
这倒是一个有趣的算法了,它充分利用了链表的思想。
桶排序(bucket sort)在平均情况下的运行时间为。
计数排序假设个输入元素中的每一个都在0和k之间,桶排序假设输入数据是均匀分布的,所以他们的速度都非常快。但并不能因为这些是假设就说它们不实用不准确,真正的意义在于你可以根据情况选择合适的算法。比如说,输入的n个元素并不是均匀分布的,但它们都在0到k之间,那么就可以用计数排序。
说到桶,我想到的是装满葡萄酒的酒桶以及装满火药的火药桶。这里是桶是指的算法将区域划分为了个相同大小的空间,它们被称为桶。
既然有了这个划分,那么就要用到它们。假设输入的是n个元素的数组A,且对于所有的i都有。你也许会觉得怎么可能输入的数组元素都凑巧满足呢,当然不会这么凑巧,但是你可以人为地改造它们呀。比如<script type="math/tex" id="MathJax-Element-50"><10,37,31,87></script>,你可以将它们都除以100,得到<script type="math/tex" id="MathJax-Element-51"><0.10,0.37,0.31,0.87></script>。
还需要一个临时的数组B[0…n-1]来保存这些桶(也就是链表),而链表支持搜索,删除和插入。关于链表的部分后面的博客中会有详细介绍。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
学习算法一定要体会到这种算法内每一步的改变,也要体会不同算法之间的演化和进步。在后面的链表中,我会更加侧重于思路以及算法的进化。
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=687
Best Last Month
.jpg)
Mechanical electromechanical by wittx

Information industry by wittx

Information industry by wittx
Information industry by wittx
Information industry by wittx
Information industry by show

Information industry by wittx

Water conservancy and hydropower by wittx
Information industry by wittx

Information industry by wittx