
-
News Message
协同过滤算法
- by show 2021-02-15
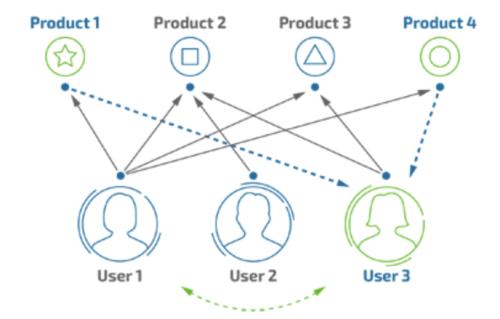
1 协同过滤
- 获取所有物品的用户反馈,包括点赞、评价等等。
- 以上数据存储为矩阵形式,用户为行坐标,物品为列坐标,例如只统计点赞的数据,将点赞设为1,点踩设为-1,没有点赞或者点踩的设为0。这个矩阵被称为“共现矩阵”。
- 比如目标是预测 用户c 对 物品a 是否喜欢,由此就问题就转换为计算 (用户c , 物品a) 坐标上的数值,接近1就是喜欢,接近-1就是不喜欢。
- 计算每个用户跟目标用户的相似度,选出相似度最大的 Top
个用户,然后根据这
个用户对目标商品的点赞情况,来预测目标用户对这个物品是否感兴趣。
- 如果预测接近1,则推荐;如果预测接近-1,则不推荐。
2 用户相似度计算
2.1 余弦相似度
2.2 Pearson相关系数
2.3 改良Pearson
3 最终结果排序
4 ItemCF
5 UserCF和ItemCF对比
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=696
Best Last Month

Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittxSuperconductor Pb10-xCux(PO4)6O showing levitation at room temperature and atmospheric pressure

Information industry by wittx
Information industry by wittx
Information industry by wittx

Information industry by wittx

Information industry by wittx
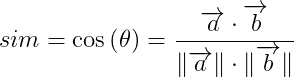
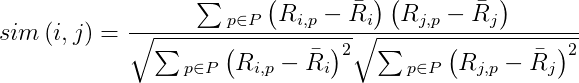
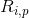 代表用户
代表用户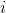 对
对 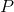 的评分,
的评分,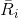 用户
用户 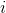 对所有物品的平均评分,
对所有物品的平均评分,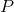 代表所有的物品集合。
代表所有的物品集合。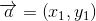 、
、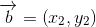 ,将这两个向量带入余弦相似度的公式中,计算两向量的余弦相似度可以得到:
,将这两个向量带入余弦相似度的公式中,计算两向量的余弦相似度可以得到: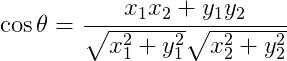
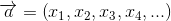 、
、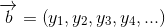 ,再次计算余弦相似度可以得到:
,再次计算余弦相似度可以得到: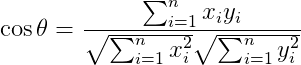
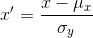 ,
,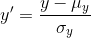 ,将
,将 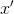 ,
, 带入上式中,可以得到:
带入上式中,可以得到: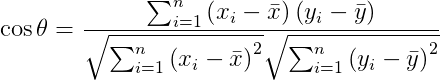
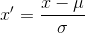 是对x进行了正态分布的标准化操作。由此,余弦相似度和Pearson相似度就关联起来了。
是对x进行了正态分布的标准化操作。由此,余弦相似度和Pearson相似度就关联起来了。![[0,1]](/images/download/1613376761512_96133) 这个范围内,或是将不同单位的数据无量纲化转化为纯数值,再或者在梯度下降时减少迭代次数以加快训练速度。举一个具体的例子,假如要求用户对商品进行打分,以用户对物品的打分构建共现矩阵。分值范围是0-100分,但是用户A习惯的打分区间是50-70分,而用户B的打分区间是80-100,假设用户AB真实的相似度极高,但是由于习惯的打分区间不同,这就会导致,两者的余弦夹角一定会存在一个相对来说较大的夹角,从而对相似度计算产生偏差,而标准化后,两者打分区间被映射到0-1这个区间里,则可以将这个夹角和真实的误差减小一些。同理,按照这个思路,用不同的数据标准化的方法是否可以推导出其他相似度计算的公式呢?
这个范围内,或是将不同单位的数据无量纲化转化为纯数值,再或者在梯度下降时减少迭代次数以加快训练速度。举一个具体的例子,假如要求用户对商品进行打分,以用户对物品的打分构建共现矩阵。分值范围是0-100分,但是用户A习惯的打分区间是50-70分,而用户B的打分区间是80-100,假设用户AB真实的相似度极高,但是由于习惯的打分区间不同,这就会导致,两者的余弦夹角一定会存在一个相对来说较大的夹角,从而对相似度计算产生偏差,而标准化后,两者打分区间被映射到0-1这个区间里,则可以将这个夹角和真实的误差减小一些。同理,按照这个思路,用不同的数据标准化的方法是否可以推导出其他相似度计算的公式呢?
 代表物品p得到的所有评分中的总评分。
代表物品p得到的所有评分中的总评分。 和
和 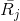 不同,会使用户评分的偏置对标准化的结果造成较大影响,因此改用了单个物品的所有用户评分的均分。
不同,会使用户评分的偏置对标准化的结果造成较大影响,因此改用了单个物品的所有用户评分的均分。 相似用户之后,要利用Top
相似用户之后,要利用Top  相似用户对目标用户进行推荐。首先要利用相似用户对商品已有的评价来对目标用户的喜好进行预测。预测方法常常使用加权平均:
相似用户对目标用户进行推荐。首先要利用相似用户对商品已有的评价来对目标用户的喜好进行预测。预测方法常常使用加权平均: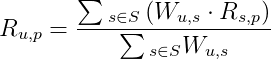
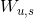 是用户
是用户 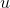 和用户相似度
和用户相似度  的相似度,
的相似度,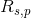 是用户
是用户  对物品
对物品 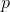 的评分。这里比较容易理解。
的评分。这里比较容易理解。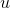 对物品的评价的预测后,根据预测的得分进行排序,最中获得全部的排序列表。以上,就是协同过滤推荐的全过程。
对物品的评价的预测后,根据预测的得分进行排序,最中获得全部的排序列表。以上,就是协同过滤推荐的全过程。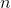 相似用户的时候,维护开销会过大,导致速度很慢,而且用户数量日益增长,导致用户相似度矩阵的存储所需空间几何倍增涨,难以存储。
相似用户的时候,维护开销会过大,导致速度很慢,而且用户数量日益增长,导致用户相似度矩阵的存储所需空间几何倍增涨,难以存储。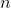 相似物品然后推荐。ItemCF算法具体流程如下:
相似物品然后推荐。ItemCF算法具体流程如下: