News Message
百度发布全球首个百亿参数对话预训练生成模型PLATO-XL
- by wittx 2021-09-25
百度发布新一代对话生成模型 PLATO-XL,一举超过 Facebook Blender、谷歌 Meena 和微软 DialoGPT,成为全球首个百亿参数中英文对话预训练生成模型,再次刷新了开放域对话效果,打开了对话模型的想象空间。
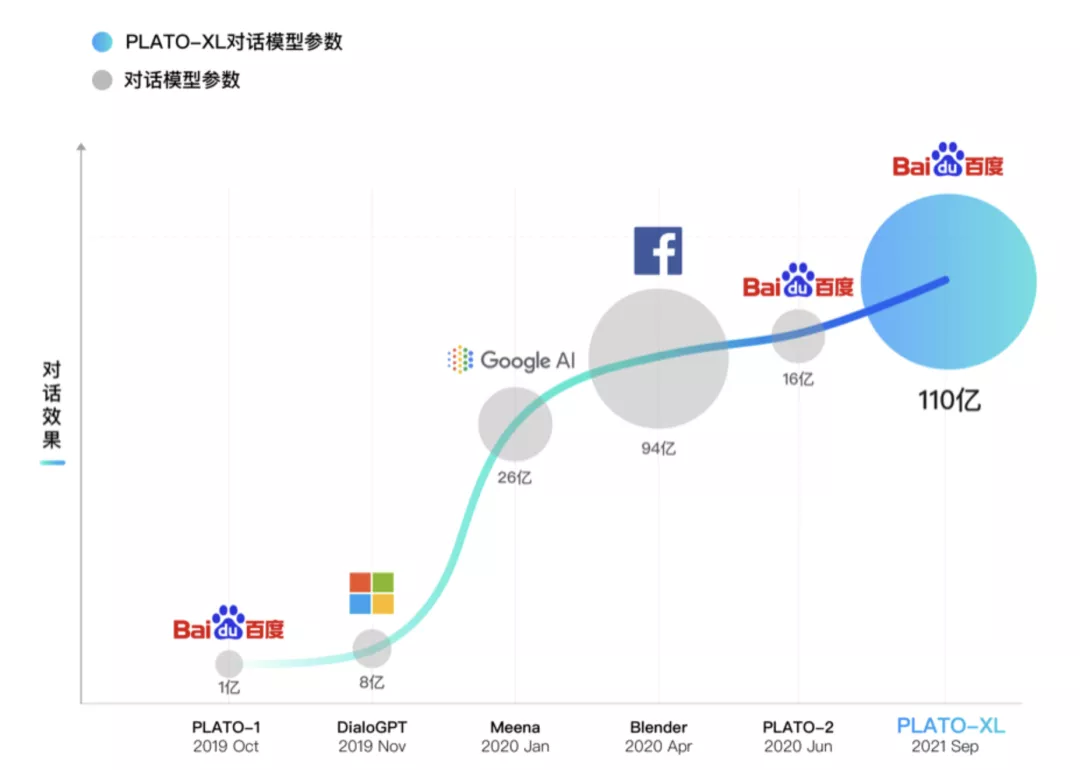
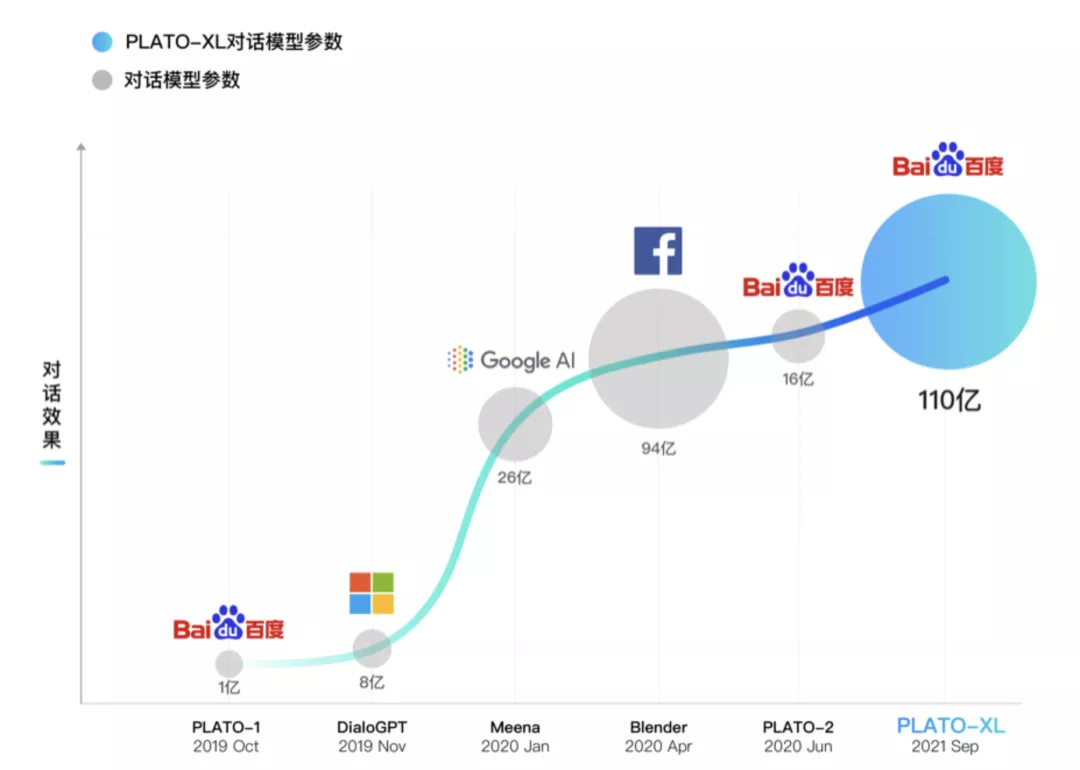
尽管大规模参数的模型在自然语言处理领域如雨后春笋出现,并且在多个自然语言理解和生成任务上取得了很多成果,但多轮开放域对话的主动性和常识性问题一直无法很好解决。百度 NLP 于 2019 年 10 月预发布了通用领域的对话生成预训练模型 PLATO,在 ACL 2020 正式展示。2020 年升级为超大规模模型 PLATO-2,参数规模扩大到 16 亿,涵盖中英文版本,可就开放域话题深度畅聊。如今,百度 全新发布 PLATO-XL,参数规模首次突破百亿达到 110 亿,是当前最大规模的中英文对话预训练生成模型。
- 论文名称 : PLATO-XL: Exploring the Large-scale Pre-training of Dialogue Generation
- 论文地址:https://arxiv.org/abs/2109.09519
PLATO-XL,全球首个百亿参数对话预训练生成模型
让机器进行像人一样有逻辑、有知识、有情感的对话,一直是人机智能交互的重要技术挑战;另一方面,开放域对话能力是实现机器人情感陪伴、智能陪护、智能助理的核心,被寄予了很高的期望。
预训练技术大幅提升了模型对大规模无标注数据的学习能力,如何更高效、充分的利用大规模数据提升开放域对话能力,成为主流的研究方向。
从谷歌 Meena、脸书 Blender 到百度 PLATO,开放域对话效果不断提升。在全球对话技术顶级比赛 DSTC-9 上,百度 PLATO-2 创造了一个基础模型取得 5 项不同对话任务第一的历史性成绩。
如今,百度发布 PLATO-XL,参数达到了 110 亿,超过之前最大的对话模型 Blender(最高 94 亿参数),是当前最大规模的中英文对话生成模型,并再次刷新了开放域对话效果。
百度 PLATO 一直有其独特的从数据到模型结构到训练方式上的创新。PLATO-1, PLATO-2 不仅刷新了开放域对话效果,也具有非常好的参数性价比,即在同等参数规模下效果超越其他模型。PLATO-XL 在参数规模达到新高的同时,其对话效果也不出意外地再次达到新高。下面,我们将展开介绍 PLATO-XL 模型的核心技术特点。
PLATO-XL 模型:更高参数性价比,大幅提升训练效果
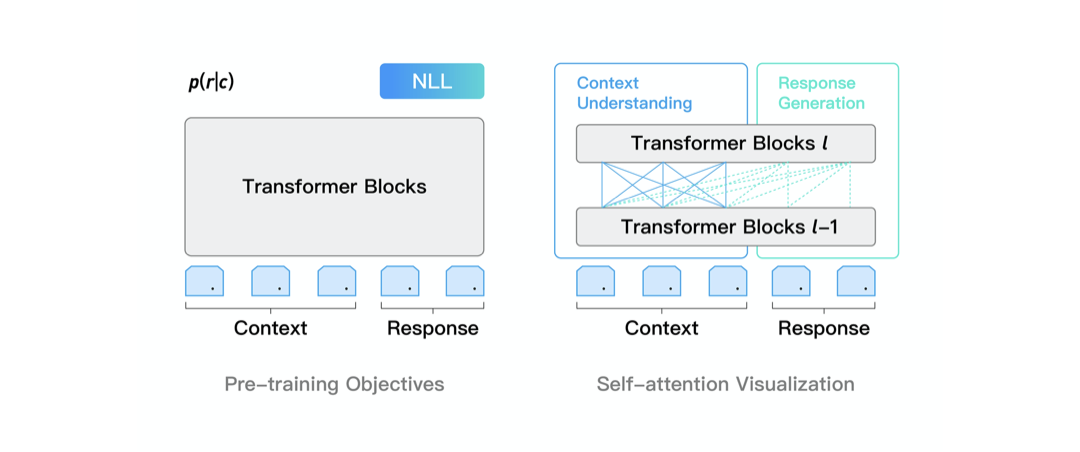
PLATO-XL 网络架构上承袭了 PLATO unified transformer 结构,可同时进行对话理解和回复生成的联合建模,参数性价比很高。通过灵活的注意力机制,模型对上文进行了双向编码,充分利用和理解上文信息;对回复进行了单向解码,适应回复生成的 auto-regressive 特性。此外,unified transformer 结构在对话上训练效率很高,这是由于对话样本长短不一,训练过程中 padding 补齐会带来大量的无效计算,unified transformer 可以对输入样本进行有效的排序,大幅提升训练效率。
为了进一步改善对话模型有时候自相矛盾的问题,PLATO-XL 引入了多角色感知的输入表示,以提升多轮对话上的一致性。对话模型所用的预训练语料大多是社交媒体对话,通常有多个用户参与,表述和交流一些观点和内容。在训练时,模型较难区分对话上文中不同角度的观点和信息,容易产生一些自相矛盾的回复。针对社交媒体对话多方参与的特点,PLATO-XL 进行了多角色感知的预训练,对多轮对话中的各个角色进行清晰区分,辅助模型生成更加连贯、一致的回复。
PLATO-XL 包括中英文 2 个对话模型,预训练语料规模达到千亿级 token,模型规模高达 110 亿参数。PLATO-XL 也是完全基于百度自主研发的飞桨深度学习平台,利用了飞桨 FleetX 库的并行能力,使用了包括 recompute、sharded data parallelism 等策略,基于高性能 GPU 集群进行了训练。
PLATO-XL 效果:多种类型、多种任务,对话效果全面领先
为了全面评估模型能力,PLATO-XL 与当前开源的中英文对话模型进行了对比,评估中采用了两个模型针对开放域进行相互对话(self-chat)的形式,然后再通过人工来评估效果。PLATO-XL 与脸书 Blender、微软 DialoGPT、清华 EVA 模型相比,取得了更优异的效果,也进一步超越了之前 PLATO-2 取得的最好成绩。此外,PLATO-XL 也显著超越了目前主流的商用聊天机器人。
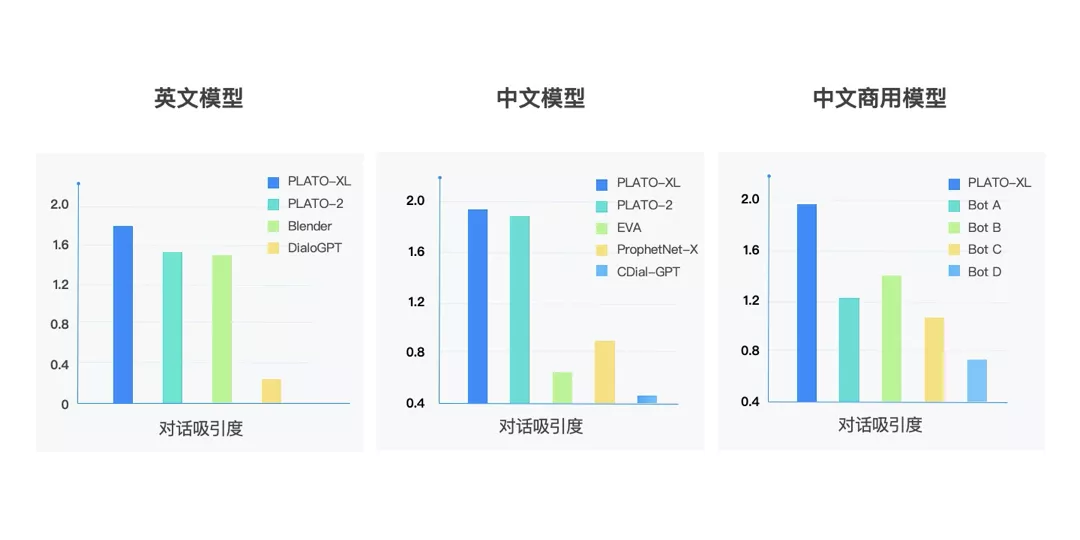
除了开放域闲聊对话,模型也可以很好的支持知识型对话和任务型对话,在多种对话任务上效果全面领先。
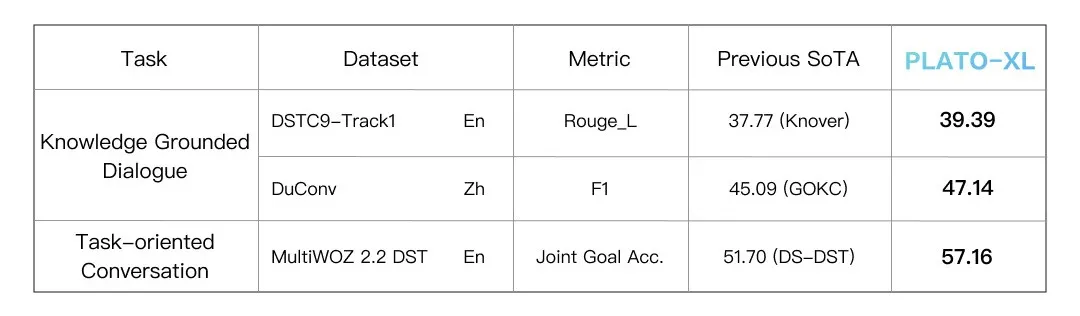
PLATO 系列涵盖了不同规模的对话模型,参数规模从 9300 万到 110 亿。下图可以看出,模型规模扩大对于效果提升也有显著作用,呈现较稳定的正相关关系。

PLATO-XL 不管是在英文,还是中文上的多轮对话,模型都可以与用户进行有逻辑、有内容且有趣的深入聊天。
 百度 PLATO-XL 模型英文对话效果
百度 PLATO-XL 模型英文对话效果 百度 PLATO-XL 模型中文对话效果
百度 PLATO-XL 模型中文对话效果结语
让机器用自然语言与人自由地交流,是人工智能的终极目标之一。百度 PLATO-XL 的发布,是开放域对话在大模型上的一次深入探索。相信在不久的将来,更加强大的对话预训练模型将会陆续发布。未来,对话模型可以更加拟人、更有知识。
百度开放接口服务供大家体验最新中文 PLATO 百亿模型的效果,对智能对话感兴趣的小伙伴一定不能错过。
更多的 PLATO 技术交流或应用需求可发送邮件到:plato@baidu.com;未来 PLATO 技术还将开放更多能力,敬请关注百度大脑 UNIT 平台。
百度大脑 UNIT:https://ai.baidu.com/unit/home
英文体验方式:https://nlp.baidu.com/special/plato/englishDemo
中文体验方式:关注 “百度 PLATO” 微信公众号,进行深度畅聊。
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=839


Best Last Month

Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning


Supercapatteries as High‑Performance Electrochemical Energy Storage Devices


DeepFM: A Factorization-Machine based Neural Network for CTR Prediction