-
News Message
基于深度强化学习的大规模推荐系统
- by wittx 2022-03-19
论文已经公布在Arxiv上:
https://arxiv.org/abs/1811.05869
在个性化推荐系统中,一个非常重要的目标是准确预测用户对物品的喜好程度,这不仅影响到用户体验,同时直接影响企业的收益。因此,用户行为预测有重要意义,而目前基础、主流的预测方法都是基于监督学习(supervised learning)的模型。用监督学习建模的主要问题是:
将推荐过程看做是一个静态的预测过程,但是实际上应该是一个动态的序列决策过程(用户的兴趣可以被推荐系统改变);
最大化推荐结果的即时利益,而很多时候那些即时利益很小但是未来回报很好的物品也应该考虑被推荐。
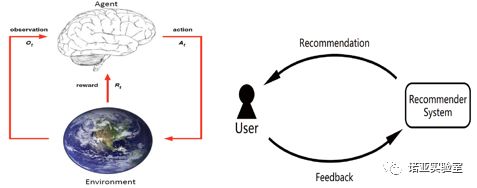
强化学习在许多动态交互、长期规划的场景中(如无人驾驶、游戏),取得了巨大成功,而最近互联网公司也尝试将强化学习应用于推荐搜索系统。强化学习模型是智能体(agent)的策略,是智能体(agent)在和环境(environment)之间的交互过程中学习而得。在推荐系统中,用户与推荐系统也是互相交互的。将强化学习应用于推荐系统时,智能体(agent)是推荐系统,而环境(Environment)是所有的用户。
强化学习包含5个要素:状态(state)、动作(action)、转移(transition)、奖励函数(reward)、折扣(discount rate)。基于强化学习的推荐过程可以抽象成这样:根据用户当前的状态(如,该用户过去与物品的一些交互行为,以及用户本身的画像信息等),推荐系统依据学习到的策略,做出一个动作(如,推荐一个商品、一组商品,或者生成一个排序函数等);用户根据该动作对应的推荐结果,给出自己的反馈(根据用户的反馈,推荐系统得到奖励),而推荐系统根据该奖励来估算该动作的长期(折扣)价值,从而更新策略;用户则进入到一个新的状态。
强化学习模型可以分为以下两类:
基于值的方法(value-based):学习一个Q函数,根据当前状态,计算所有动作的Q值,每次推荐都选取Q值最大的动作;
基于策略的方法(policy-based):学习一个策略函数,根据当前状态,策略决定最优动作或者其分布;
▶ Deterministic policy: 策略给出最优的动作,一般为连续型动作,如空调的温度或者函数参数等;
▶ Stochastic policy: 策略给出最优动作的分布,一般为连续型动作或者离散型动作,如推荐物品等。
在推荐场景中,很多时候推荐候选集的数量较大(成千上万的物品待推荐),是大规模离散动作的应用场景。现有的强化学习模型均无法在这种场景下进行高效的训练和决策。Value-based方法更新时需要计算target Q值,需要遍历所有的动作;而决策时需要计算所有动作的Q值来决定最好的动作。Stochastic policy方法更新时需要遍历所有动作去计算softmax函数;而决策时也需要计算softmax函数去进行采样以得到执行的动作。Deterministic policy方法在训练和决策时,需要将生成的动作与所有候选集中的商品进行计算得到排序分数,因此需要遍历大量的物品。TPGR模型与现有基于强化学习推荐模型[1-5]的区别如下表所示。 [5]虽然也适用于大规模离散动作,但是模型本身有着很大的设计缺陷,详情请看我们的论文。
基于现有工作的缺陷,我们提出了一种能够在大规模离散动作的场景下高效工作的强化学习模型TPGR (Tree-structured Policy Gradient for Recommendation)。这个模型分为两步:第一步,对于所有物品,构造一棵平衡层次聚类树;第二步,对该树的每一个非叶子节点,构造一个policy network并联合训练。下面我们对这两步进行详细地介绍。
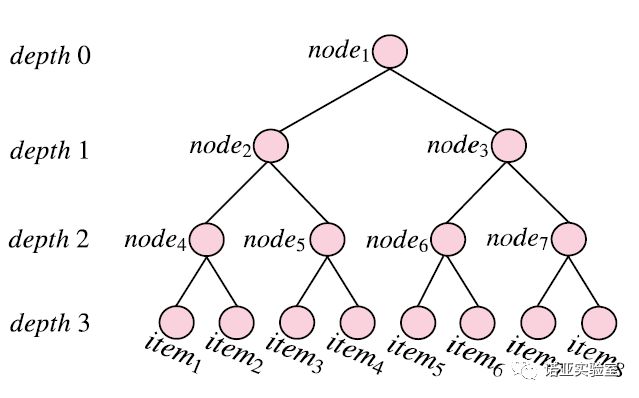
第一步,对所有物品,构造一棵平衡层次聚类树。其中,这棵树的叶子节点表示一个待推荐的物品,非叶子节点表示一些中间信息。推荐一个物品即为从根节点沿着某一条路径走向一个叶子节点的过程,一条路径与一个物品是一一对应的关系。平衡层次聚类树指的是:每个非叶子节点的下属子树也是平衡的,且这些子树的高度差距不大于1。我们构造平衡层次聚类树的目的是为了限制找到某一个物品而在该树里游走的最大步数,从而为复杂度找到一个合理的上限值。在代码实现过程中,为了简化,我们假设该树是一棵c叉树,即每个非叶子节点都有c个孩子节点(除了叶子节点的父亲节点)。构造平衡层次聚类树的方法有多种,包括K-means方法和PCA方法,详细过程可以参考我们的论文。下图所示即为我们为8个物品构造的一棵平衡层次聚类树。
第二步,对于树中所有的非叶子节点,构造一个policy network。其中,每个policy network负责决定下一步走向该非叶子节点的哪一个孩子节点;则推荐一个物品的概率即为沿着该路径每一个概率的乘积。下图展示了一个选择item 8进行推荐过程。树中每一个非叶子节点(从node 1到node 7)都有一个独立的policy network。从根节点node 1出发,policy network 1选择了node 3,而policy network 3选择了node 7,接下去policy network 7最终选择了item 8。Item 8被选择的概率即为policy network 1选择node 3、policy network 3选择node 7、policy network 7选择item 8的概率乘积。我们用REINFORCE方法对所有的policy network进行联合训练。详细的训练过程可以参考我们的论文。
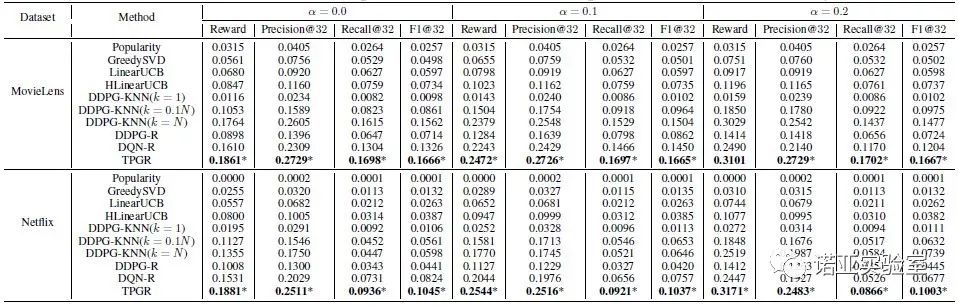
我们在MovieLens和Netflix两个数据集上对TPGR和其他的模型进行了对比。其他的模型包括普通模型(Popularity, GreedySVD),MAB模型(LinearUCB, HLinearUCB),强化学习模型(DDPG-KNN, DDPG-R, DQN-R)。评价指标有传统的推荐评价指标(Precision, Recall, F1)和online learning的评价指标(Reward)。我们发现,TPGR模型在两个数据集上相比于其他模型,可以大幅提升评价指标,如下表所示。
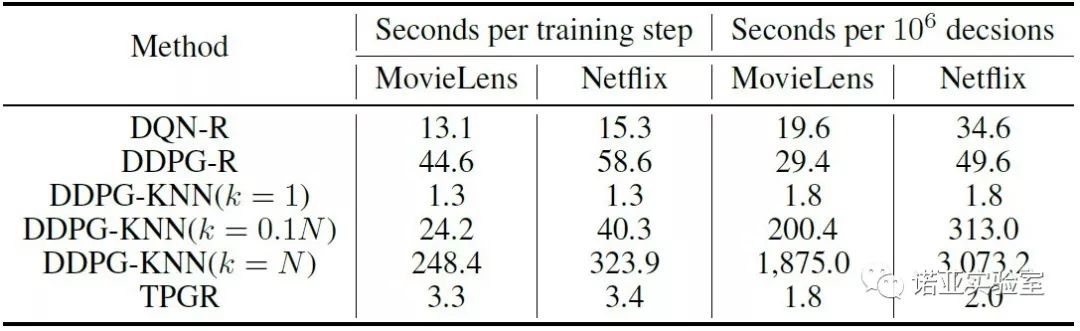
同时我们还测试了不同模型之间的训练和决策时间对比,我们发现TPGR模型更加高效。
我们现在正在尝试将这个模型应用于华为应用市场的推荐业务中,以给广大用户更好的体验。大家如果有任何问题,欢迎联系我们。我们将一直致力于产学结合的研究,欢迎各位有志之士的加入!
References
[1] Xiangyu Zhao et al. Recommendation with Negative Feedback via Pairwise Deep ReinforcementLearning. KDD 2018.
[2] Guanjie Zheng et al. A Deep Reinforcement Learning Framework for News Recommendation.WWW 2018.
[3] Xiangyu Zhao et al. Deep Reinforcement Learning for Page-wiseRecommendation. RecSys 2018.
[4] Yujing Hu et al. Reinforcement Learning to Ranking in E-commerce Search Engine:Formalization, Analysis, and Application. KDD 2018.
[5] Gabriel Dulac-Arnold et al. Deep Reinforcement Learning in LargeDiscrete Action Spaces. arXiv 1512.07679.
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=918
Best Last Month
Information industry by wittx
Information industry by wittx

Information industry by wittx
Medical science by wittx

Information industry by wittx
Information industry by wittx
Information industry by wittx
Information industry by wittx

Information industry by wittx
Information industry by wittx