
-
News Message
基于策略搜索的强化学习方法(PG,TRPO,PPO,DPPO,AC,A3C,DDPG,TD3)
- by wittx 2022-06-20
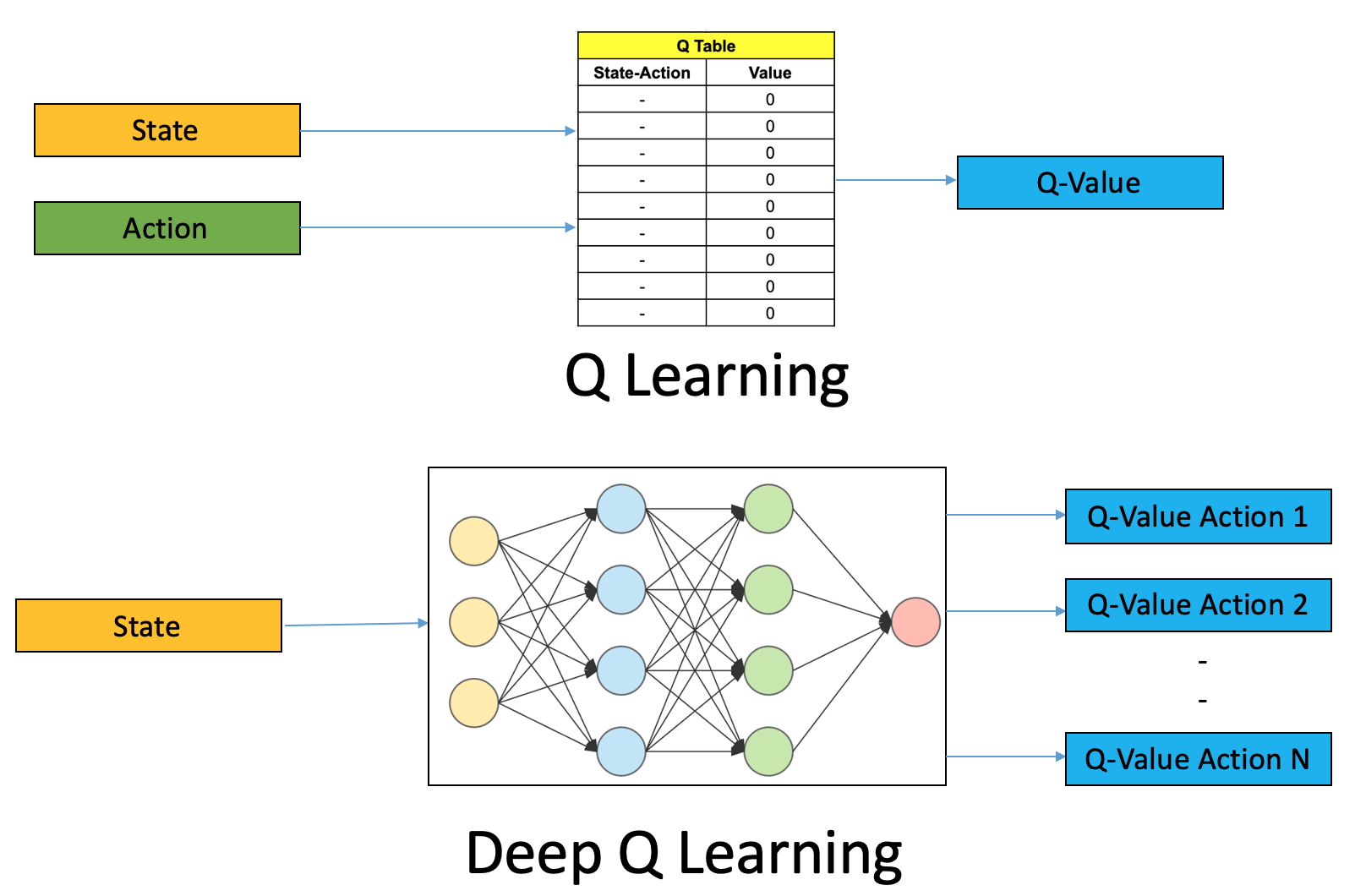
1.policy gridient
1.1 基础推导
1.2 Tip
Tip1: add a baseline(增加基线)
因为原来的梯度,一直都会取正数,不是特别合适,但是这样其实无可厚非,因为可以用过大小进行区分,但我们这里更好的办法是给他加入一个基线,让其有正有负。
Tip2:Assign Suitable Credit
因为如果对于每个执行的动作,都使用同样的全局reward,则会有损公平性,因为在同一个episode中,并不是所有的动作都是同样好的,所以我们这里使用的是从执行完该动作到结束这段过程中的reward来进行学习,并加入衰减参数。
1.3 仍然存在的问题
采用的全局reward,需要等待整局游戏结束后,才能对参数进行一次更新,效率十分的低
1.4 针对问题提出的改进方法
采用off-policy的方法进行采样,这样样本的利用效率则会高得多
2.TRPO PPO
2.1基础推导
2.2Tip
Tip1:采用重要性采样,这样就可以采用off-policy的更新方法,样本利用效率更高
Tip2:为了使得两种策略更加接近,我们这里采用一个KL散度来降低两者的差距。
PPO和TRPO十分类似,PPO是TRPO的改进版
DPPO的算法流程如下图所示,其中W是workers的数量;D是一个阈值,它指定更新全局网络参数时所需的workers的数量,也就是说如果有一定数量的worker的梯度是available时,就同步地更新全局网络参数,这一个全局网络参数等于各个worker的梯度的均值;M和B是在给定一把mini batch数据的条件下,更新actor和critic网络的迭代步数;T是每一个worker在参数更新之前的date points数量;K是K-steps return的数量。
3.Actor Critic
3.1 基本推导
Actor-Critic=Policy gradient(Actor)+Value based(Critic)
4个网络,动作估计、动作现实、状态估计、状态现实。
Policy gradient中的G(上文提及的reward)不稳定,在Policy gradient中引入Q value,advantage function改为q(s,a)-v(s)。
进一步改为(r+v(s t+1)-v(s t)),varience会降低。
3.2 Tip
用Q网络来计算序列的总回报,这样更加稳定和准确,而且还可以利用基于值的方法的每执行一次动作就可以更新的特性。
4.DDPG
也就是说动作-状态值函数Q只和环境有关系,也就意味着外面可以使用off-policy来更新值函数(比如使用Q-learning方法等)
与策略无关,所以可以用别的策略来更新值函数
5.TD3
TD3的技巧
技巧一:裁剪的双Q学习(Clipped Double-Q learning). 与DDPG学习一个Q函数不同的是,TD3学习两个Q函数(因此称为twin),并且利用这两个Q函数中较小的哪个Q值来构建贝尔曼误差函数中的目标网络。
技巧二:延迟的策略更新(“Delayed” Policy Updates). TD3算法中,策略(包括目标策略网络)更新的频率要低于Q函数的更新频率。文章建议Q网络每更新两次,策略网络才更新一次。
技巧三:目标策略平滑(Target Policy Smoothing). TD3在目标动作中也加入了噪声,通过平滑Q函数沿着不同动作的变化,使得策略更难利用Q函数的错误。
技巧三:目标策略平滑(Target Policy Smoothing). TD3在目标动作中也加入了噪声,通过平滑Q函数沿着不同动作的变化,使得策略更难利用Q函数的错误。
————————————————
版权声明:本文为CSDN博主「Enoch Liu98」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_41061258/article/details/108903305
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=957
Best Last Month
Computer software and hardware by wittx

Information industry by wittx

Material specialty by wittx
Information industry by wittx
Information industry by wittx
Information industry by wittx

Electronic electrician by wittx

Information industry by wittx
Information industry by wittx

Information industry by wittx
