
-
News Message
LLM引擎把GPT-3调成ChatGPT
- by wittx 2023-05-01
用户发布的文档
加载速度比较慢比较慢,请稍等,手机环境下,有可能无法显示! " width="100%" height="800">https://github.com/lamini-ai/
斯坦福的一群开发者发布了 Lamini,号称可以为每个开发人员提供从 GPT-3 带到 ChatGPT 的超能力。
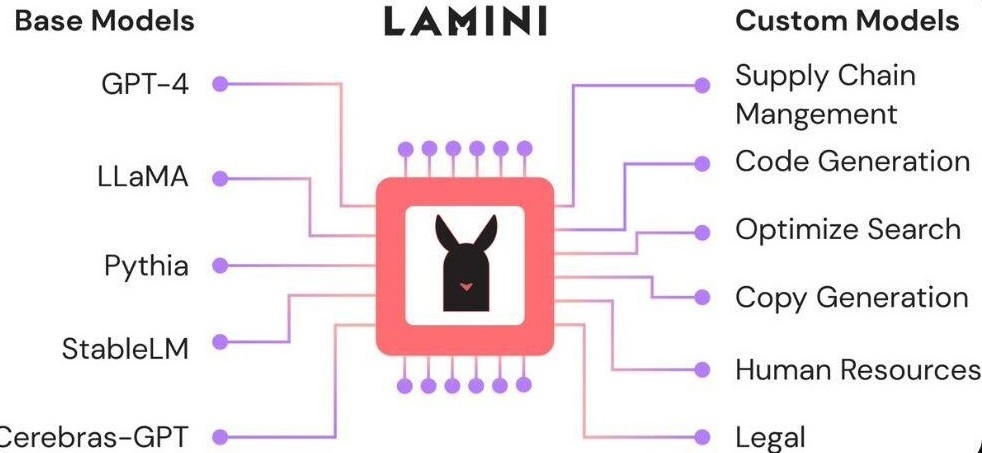
Lamini 是一个 LLM 引擎,供开发人员使用很多公司、机构的基础模型快速构建定制化模型:你可以用 OpenAI、EleutherAI、Cerebras、Databricks、HuggingFace、Meta 等公司的技术做自己的,只要他们开源就可以。
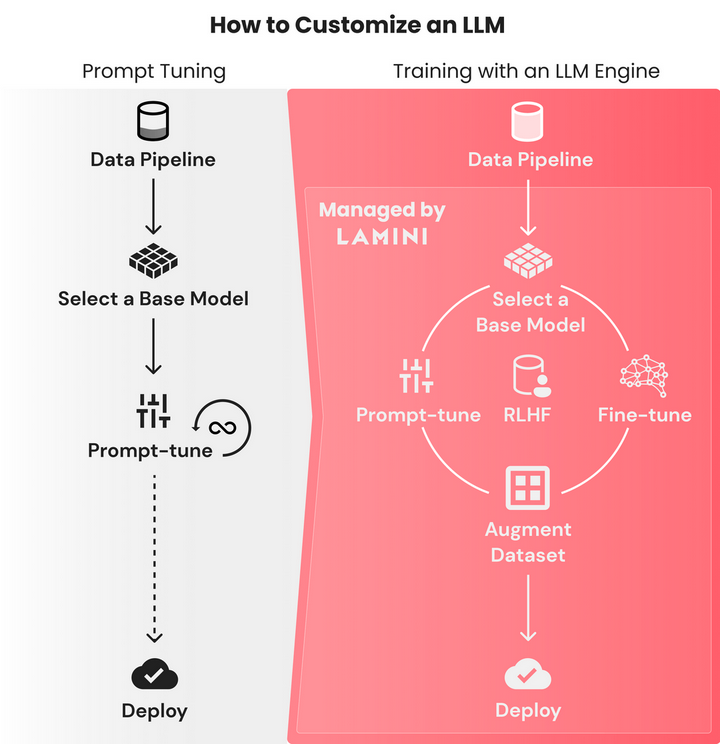
将基础模型构建成强大的语言模型是一个极具挑战性的过程,需要花费大量的时间和成本。首先,在特定数据集上进行微调的迭代周期以月为单位,需要花费大量时间找出微调模型失败的原因。虽然使用 prompt 调整迭代以秒计时,但微调之后的模型性能只能稳定几个小时,而且能融入 prompt 的数据量非常有限。
OpenAI 的机器学习团队花了几个月的时间在其基本模型 GPT-3 上进行微调,并使用 RLHF(基于人类反馈的强化学习方法)才构建出强大的 ChatGPT。这个过程需要消耗大量的计算资源,还要求团队具备专业的技术知识。
在 ChatGPT 开放 API 之后,很多公司都尝试使用 OpenAI 提供的微调 API,但结果却不尽如人意,一些基础模型经过微调之后,性能变得更差,无法投入使用。还有一些公司表示不知道如何充分利用数据。
现在,名为「Lamini」的新工具解决了这些问题。Lamini 将微调封装成一种服务,使开发人员可以轻松将 GPT-3 微调成 ChatGPT。

简单来说,Lamini 提供了一种托管化的数据生成器,只需执行 Lamini 库中的几行代码,用户就能训练自己的大型语言模型(LLM)及其权重,而无需使用任何 GPU。
速成强大的 LLM
Lamini 是一个 LLM 引擎,它允许开发人员只使用 Lamini 库中的几行代码,就能在大型数据集上训练出高性能的 LLM。Lamini 库涵盖对机器学习模型的多种优化,包括简单的优化(例如消除模型「幻觉」)和更具挑战性的优化(例如 RLHF)。
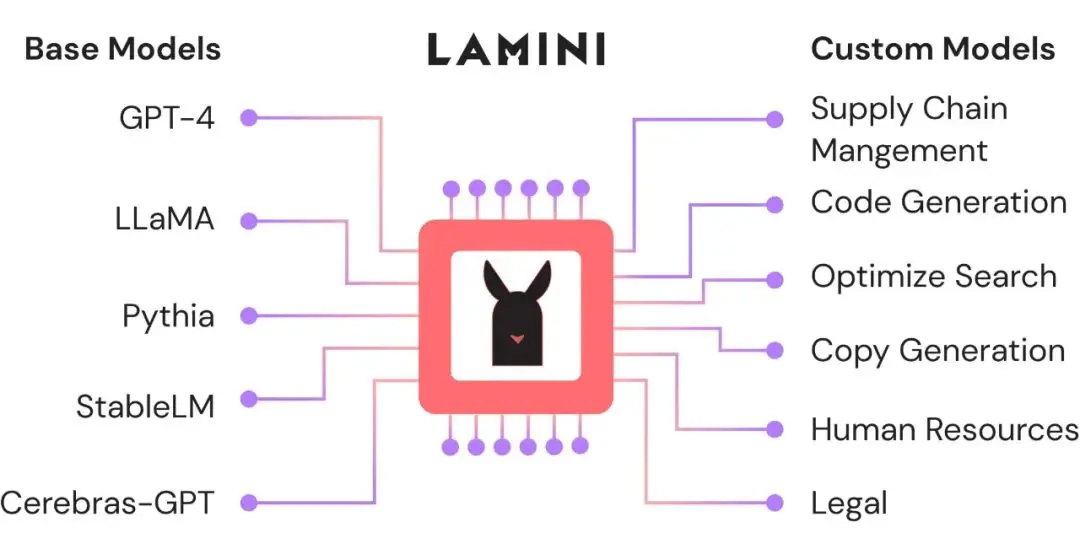
那么,Lamini 库在构建 ChatGPT 般强大的 LLM 时能起到哪些作用?按照 OpenAI 构建 ChatGPT 的流程,Lamini 的作用具体包括以下几点:

1. 对 ChatGPT 或其他模型进行 prompt 调整。Lamini 库的 API 提供快速调优功能,只需一行代码即可在 OpenAI 的模型和其他开源模型之间切换。Lamini 库还提供了优化之后的正确 prompt,以便于用户根据模型设置不同格式的 prompt。
2. 构建一个输入输出对的大型数据集。该数据集将让模型理解它应如何响应其输入。使用 Lamini 引擎,用户可以仅用几行代码就快速从 100 个数据点生成 50k 数据点,而无需启动任何 GPU。Lamini 也提供了一个 50k 的开源数据集。
3. 在数据集上微调基础模型。Lamini 的研究团队在其 50k 的开源数据集上微调出一个 LLM,后续他们将发布执行此操作的功能和代码。
4. 在经过微调的模型上运行 RLHF。Lamini 库让用户不再需要大型 ML 和人工标记团队来运行 RLHF。
5. 方便用户将模型部署到云端。
数据生成器
ChatGPT 风靡全球是因为它可以遵循用户的指令生成高质量内容,但其基础模型 GPT-3 却不总是能做到这一点。例如,向 GPT-3 提出一个问题,它可能会生成另一个问题而不是回答它。
ChatGPT 能做到这一点的原因是它使用了大量的「指令 - 执行」数据。但对于普通的开发人员来说,这些数据是难以获得的。
基于此,Lamini 提供了一个托管数据生成器,只需几行代码即可将 100 个样本变成超过 50k 个样本,而不需要启动任何 GPU,并且生成的数据是商业可用的。用户可以自定义最初的 100 多条指令,以便生成的 5 万条符合要求的指令,最终得到一个大型指令遵循数据集。
Lamini 的数据生成器是一个 LLM pipeline,其灵感来自斯坦福的开源模型 Alpaca。这个生成 pipeline 使用 Lamini 库来定义和调用 LLM,以生成不同但相似的指令 - 响应对。

托管数据生成器生成的数据质量参差不齐,有的数据很好,有的则很差。因此,Lamini 下一步将生成的数据过滤为高质量数据,这个过程只需要运行一个如下的简单脚本。
import jsonlines def main(): dataset = list(load_dataset("data/lamini_dataset.jsonl")) questions = set() filtered_dataset = [] for example in dataset: if example["question"] in questions: continue filtered_dataset.append(example) questions.add(example["question"]) print(f"Removed {len(dataset) - len(filtered_dataset)} duplicate questions") save_dataset("data/filtered_lamini_dataset.jsonl", filtered_dataset) def load_dataset(path): with open(path) as dataset_file: reader = jsonlines.Reader(dataset_file) for example in reader: yield example def save_dataset(path, dataset): with open(path, "w") as dataset_file: writer = jsonlines.Writer(dataset_file) for example in dataset: writer.write(example) main()然后,Lamini 通过在过滤后的高质量数据集上训练基础模型为用户创建自定义 LLM。
总的来说,Lamini 把微调模型封装成一种服务,让开发者们只用非常简单的步骤就能把基础模型微调成性能良好的垂类模型,这大幅降低了构建 LLM 的技术门槛。
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1173
Best Last Month
Information industry by wittx

Information industry by wittx

Information industry by wittx
Information industry by wittx
Information industry by wittx
Information industry by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittxTake a Step Back: Evoking Reasoning via Abstraction in Large Language Models
Information industry by wittx
