
-
News Message
相似向量检索
- by wittx 2023-07-30
前言
由于项目需要,需要对某些种子用户进行look-alike,找到相似用户,所以近期对相似向量检索库Faiss进行一定的了解,接下来,结合相关资料,把我对这个库的了解记录在这里,也希望对你有所帮助!
一:Faiss简介
Faiss全称(Facebook AI Similarity Search)是Facebook AI团队开源的针对聚类和相似性搜索库,为稠密向量提供高效相似度搜索和聚类,支持十亿级别向量的搜索,是目前较成熟的近似近邻搜索库。
它包含多种搜索任意大小向量集(备注:向量集大小由RAM内存决定)的算法,以及用于算法评估和参数调整的支持代码。
Faiss用C++编写,并提供与Numpy完美衔接的Python接口。除此以外,对一些核心算法提供了GPU实现。
二:Faiss 原理
2.1 整体流程图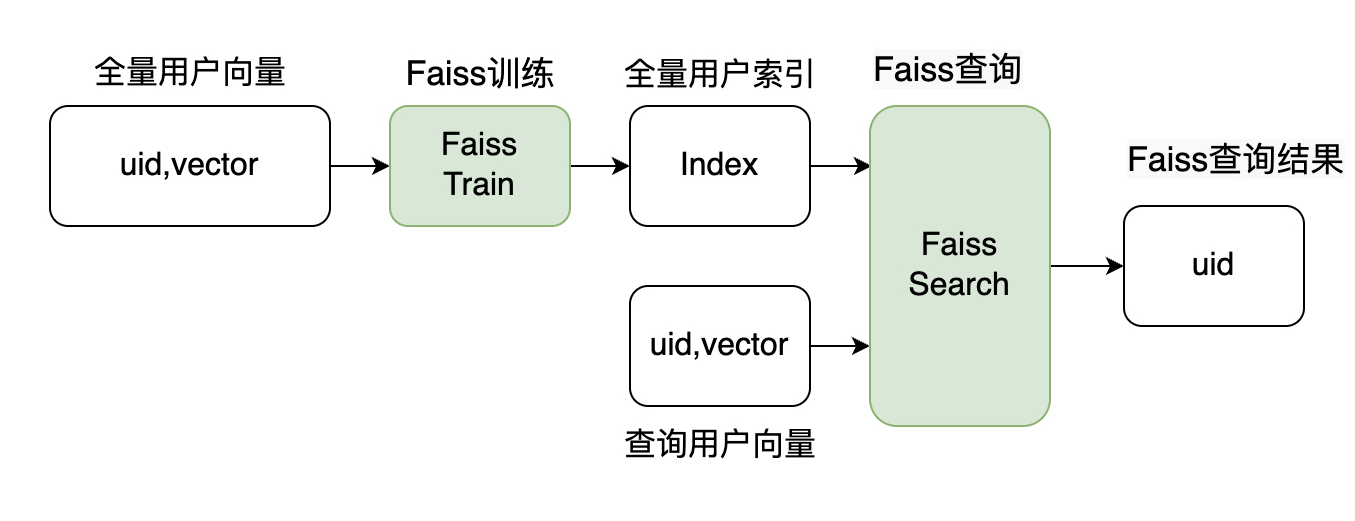
Faiss核心原理就两个,倒排索引 IVF和乘积量化 PQ,这两个方法是Faiss实现高速,少内存以及精确检索的主要手段。
2.2 倒排索引 IVF(Inverted File System)
IVF其实很好理解,假如我们想要在全国范围内找到一个给定年龄,性别,身高体重等信息的人,那么其中的一个办法是,拿这些信息和全国的人都一一对比,然后找到和这个条件最相近的一类人。但是如果我们先把全国的人按照省份进行划分,先看这个人是哪个省份的,接着从这个省份里去全量搜,那么计算了一下子降了一个数量级,如果是按城市划分,则计算量可以降低好几个量级,这就是IVF的基本原理。
暴力搜索的方式是在全空间进行搜索,为了加快查找速度,几乎所有的ANN方法都是通过对全空间进行分割(聚类),将其分割成很多小的子空间,在搜索时,通过某种方式快速锁定在某一(几)个子空间,然后在这几个子空间中进行遍历。IVF流程图:
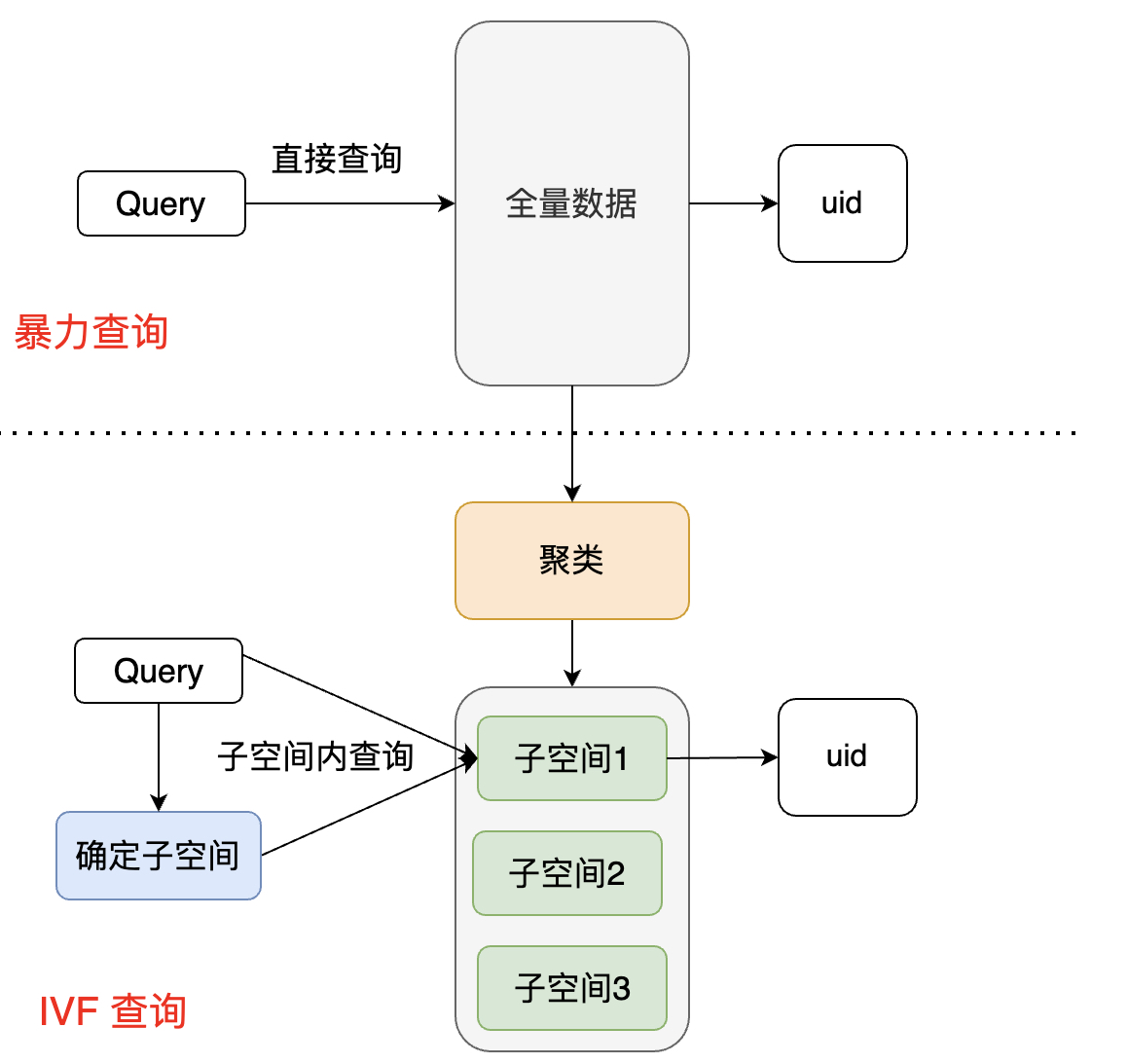
确定子空间: 通过计算query向量和所有子空间中心(如子空间内所有向量的均值)的距离,选出距离最近的K个子空间,表示和该query最相近的向量,最有可能在这几个子空间里。
缺点:
可能会损失精度,找到的是局部解,不是全局最优
很可能更相近的向量不在遍历的这几个空间内,因此找到的相似向量不是全局最优的,在faiss中有两个参数,分别是nlist 和 nprobe ,其中前者决定了对全量用户聚类的个数,一般来说聚类个数越大,训练过程越慢,检索速度越快(每个子空间需要遍历的向量变少),后者nprobe决定了每次检索几个子空间,一般来说,检索的子空间越多,检索越精确,但是检索速度越慢。两者需要做一定的权衡。特别地,当两者相等时,等价于暴力检索。
检索速度可能不太稳定
一般来说,在进行聚类后,检索的速度应该是暴力检索的 1/nlist ,但是由于聚类算法不可能保证每个类包含的向量数量都是一样的,实际直觉上各个类的大小也不应该一样(如每个省份的人有多有少),因此在需要对较大的子空间进行遍历时,需要消耗较多的时间,反之则速度更快。一般有个常量C来表示,整体的查询效率为 C/nlist 。
内存消耗较大
无论是训练还是最后的检索,为了提升速度,都需要把全量数据加载到内存中,这种方法没有对向量进行压缩,内存消耗较大。
2.3 乘积量化
乘积量化的核心思想还是聚类。其主要分为两个步骤,Cluster 和 Assign,也即聚类和量化。
乘积量化示意图: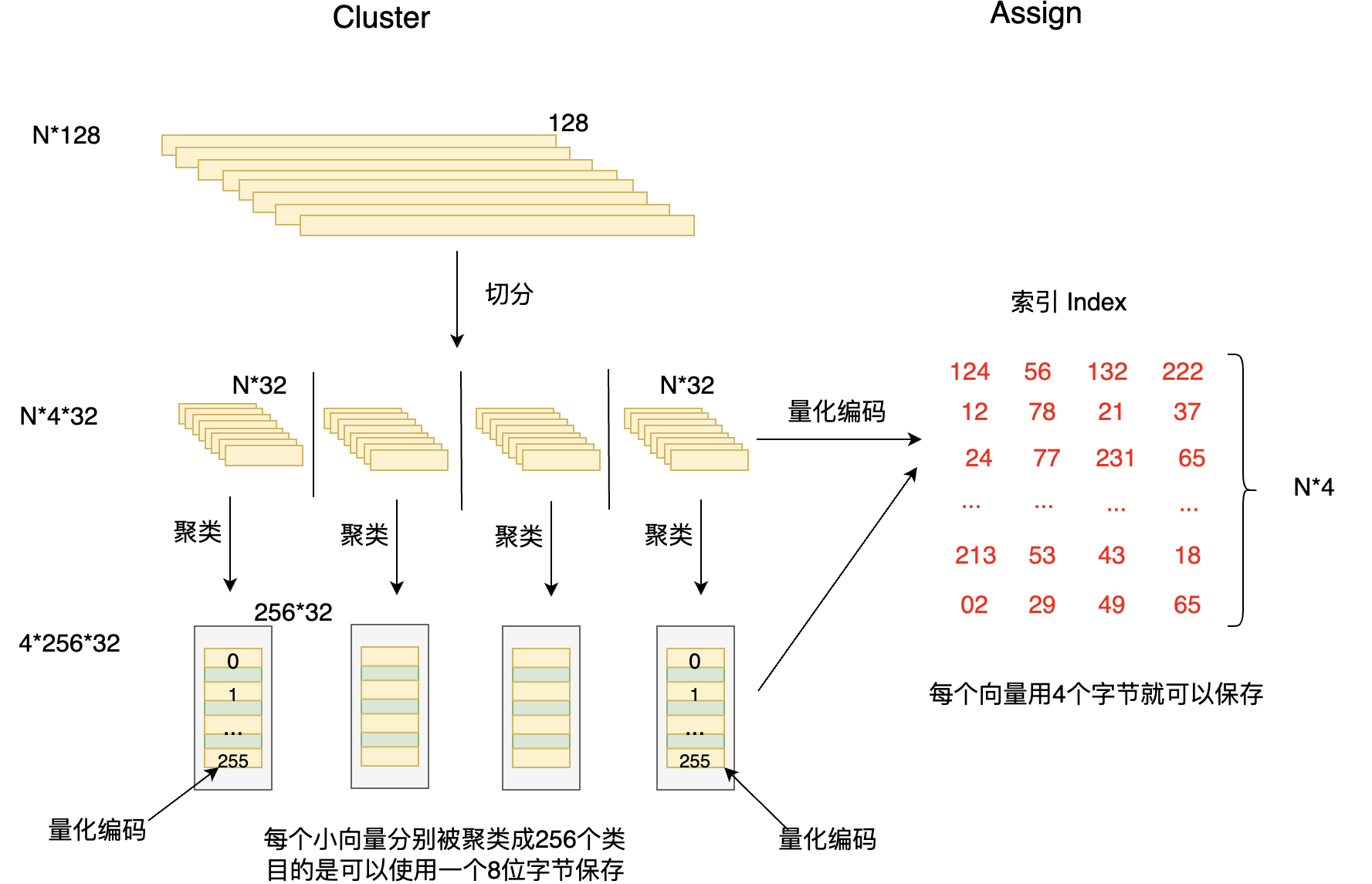
乘积量化有个重要的参数m_split ,这个参数控制着向量被切分的段数,如图所示,假设每个向量的维度为128,每个向量被切分为4段,这样就得到了4个小的向量,对每段小向量分别进行聚类,聚类个数为256个,这就完成了Cluster。然后做Assign操作,先每个聚类进行编码,然后分别对每个向量来说,先切分成四段小的向量,对每一段小向量,分别计算其对应的最近的簇心,然后使用这个簇心的ID当做该向量的第一个量化编码,依次类推,每个向量都可以由4个ID进行编码。
每个ID可以由一个字节保存,每个向量只需要用4个字节就可以编码,这样就完成的向量的压缩,节省了大量的内存,压缩比率2000+。
这一步其实就是Faiss训练的部分,目的是为了获取索引Index。在完成向量压缩,获取索引之后,就要考虑如何进行向量查询,下图表示了某个查询向量Query进行查询时的操作流程:
向量查询示意图: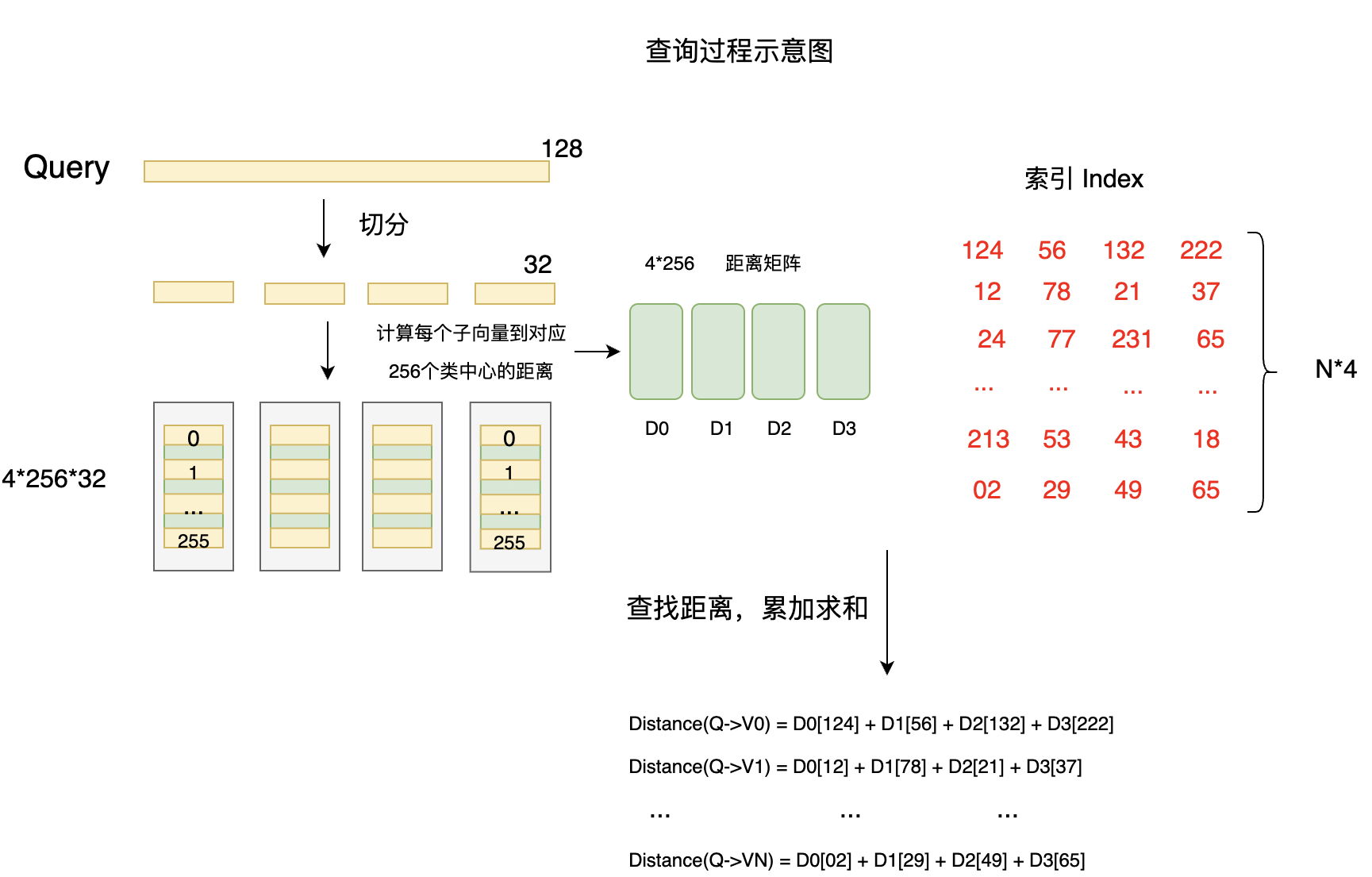
由上图可以看出,当来到一个查询向量后,和训练时一样,首先需要对这个向量进行切分,这样就可以得到四小段的向量,然后计算每个小向量和对应的256个类中心的距离,存在一个距离矩阵或者数组中,接着就可以通过查表,来计算查询向量Query和每个向量之间的距离。计算方式就是累加每个小向量之间的距离之和。
三:优化效率计算
由上可以看出,在原来的暴力算法下,进行一次查询需要的计算量是 N128次计算,但是使用PQ后,只需要 425632次计算,加上4N次查表计算,因此计算量之比为: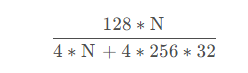
当N特别大时,425632 可以忽略,计算量减少32倍。(注:分母的查表操作耗时远小于分子的浮点乘法计算,因此计算效率会远大于32)
但是,考虑到3.2小节提到的IVF方法,先进行聚类,再进行PQ,那么计算量再次减少,变成 :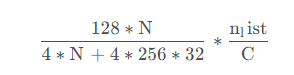
假设nlist设置为2000,常数c为5,则优化效率至少为1200,提升了3个数量级,计算量再次减少,最终可以实现快速,高效的相似向量查询。
四:总结
本文只着重讲解Faiss比较核心的原理,还有基于局部哈希敏感,基于图检索的分层小世界导航等方法,有兴趣的同学可以看它的github以及相关的博客等。另外具体使用方法也可自行查找相关资料。
Reference
[1] https://github.com/facebookresearch/faiss
[2] https://zhuanlan.zhihu.com/p/164888905
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1223
Best Last Month

Information industry by wittx

Information industry by wittx
Information industry by wittxNature High-efficiency solar thermoelectric conversion enabled by movable charging of molten salts

Information industry by wittx
Information industry by wittx

Information industry by wittx
Information industry by wittxThree dimensional architected thermoelectric devices with high toughness and power conversion effici

Information industry by wittx
Electronic electrician by wittx

Information industry by wittx
