
-
News Message
ChatGPT GPT-4 技术原理
- by wittx 2023-03-17

用户发布的文档
加载速度比较慢比较慢,请稍等,手机环境下,有可能无法显示! " width="100%" height="800">前言
昨晚,OpenAI放出了最新一代的双模态超大规模预训练模型GPT-4。之前ChatGPT出来之后的那种震撼还没完全消散,多模态的GPT-4就到来了。怀着激动的心情看完了这篇GPT-4的技术报告。相比chatGPT更新的点是:
- 支持text 和 visual双模态的输入,但是输出只支持text(网页版还没完全支持)
- 拓展了token限制,从8,192拓展到了3w➕
- 数理化能力大幅提升(不再是ChatGPT那样的文科生了)
- 以及更加安全的AI助手(想让模型说出邪恶 回答更难了)
首先贴一下报告原文
模型架构
OpenAI考虑到竞争以及安全问题没有透露任何模型架构和参数量(猜测模型的参数量应该是非常可观),数据集构建以及训练时间以及代价的细节信息,只说明了仍然是Transformer-style的预训练模型。数据来自于互联网以及部分的第三方提供者。模型微调部分和InstructGPT以及ChatGPT一样是采用RLHF(Reinforcement Learning from Human Feedback)训练的。
Predictable Scaling
对于GPT-4这样的大规模的模型,进行特定模型的调优几乎是不可能的。作者为了解决这个问题,开发了多个尺度的可预测工具,使得可以利用小尺度的GPT-based模型来预测GPT-4在某些方面上的性能。
Loss Prediction
在之前一些工作发现经过适当训练的大型语言模型的final loss可以很好地来逼近模拟训练模型的计算量的幂律级数。
下面这个图是GPT-4和更小型号性能的图表,ChatGPT被归一化为1的绿点,点是观测到的不同规模模型的在未出现在训练数据中的codebase的Final Loss ,虚线是预测的曲线。可以看到,预测的曲线,在不同尺度上模型的Final Loss的准确率非常之高。预测曲线公式:
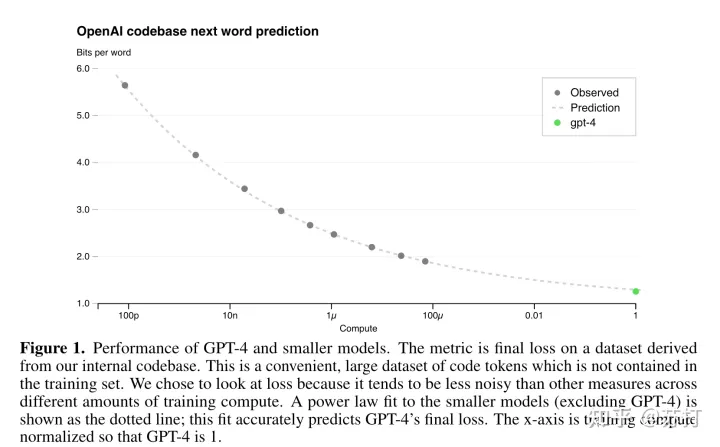
下面这张图y轴代表不同模型性能在HumanEval(code任务)上的性能,可以看到预测曲线准确率稍稍不如上面的图,但是也已经很高的。这说明通过预测曲线,可以通过小规模模型在不同方面(数据集,或者具体任务,或者某一垂直领域)的性能,来相对准确地预测通过放大千倍万倍之后的大模型的性能。
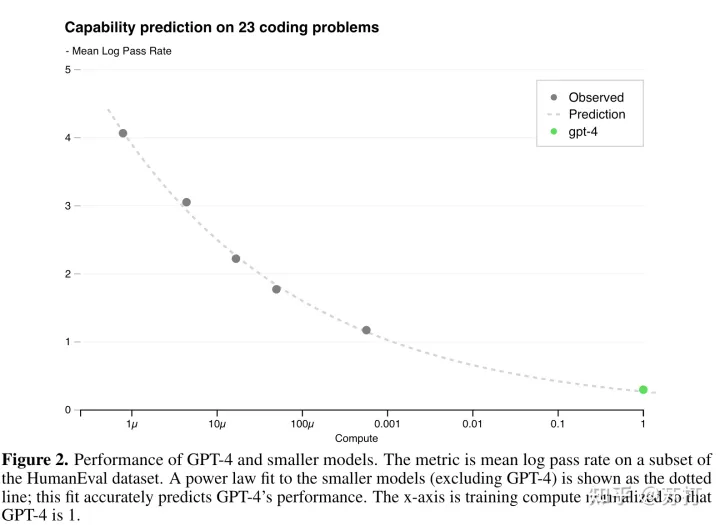
文中也说明了,不是所有任务都能有这种比较精确的幂律预测曲线,比如下面这个Hindsight Neglect 任务,随着模型规模的扩大准确率在慢慢下降没有超过50,但是在GPT-4上出现了一个巨大跃升,达到了100%的准确率。(又是大模型的涌现能力吗?)
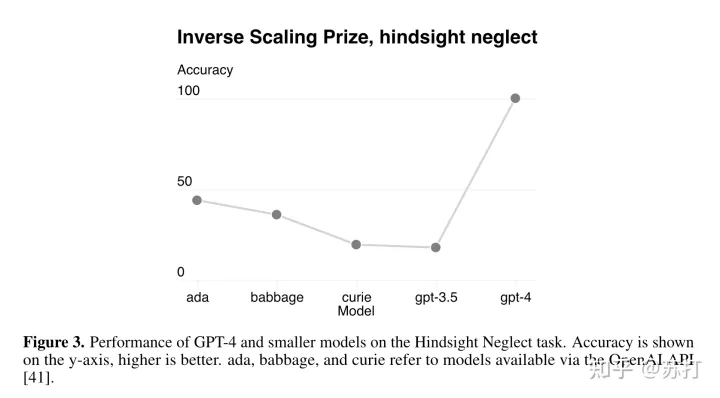
作者认为,准确预测未来大模型的能力对安全非常重要。作者计划在大型模型训练开始之前改进这些方法,并在各种任务和方面上记录性能预测,希望这成为该领域的共同目标。
Capabilities
下面就到了这篇论文的重头戏,展示GPT-4在各个方面、各个任务上的惊艳结果。
各类考试
首先是在各类考试上的结果(GPT-4是文本图像双模态训练,GPT-4(no vision)是文本单一模态训练)

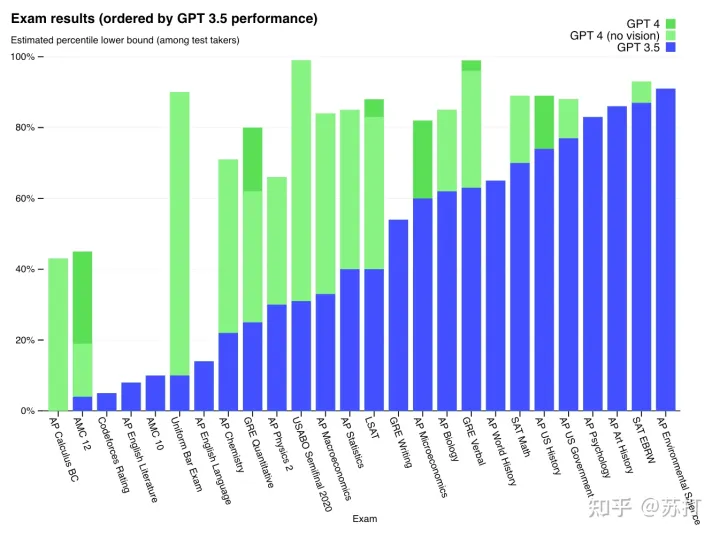
可以看到GPT-4在各类考试测试上的超强的能力(做题家狂哭),尤其是在数理化上相对于GPT-3.5的巨大提升。【附录中说明了,GPT-4在训练中混入了一部分的数学做题文本的数据集】文科的能力其实提升不大(其实是因为GPT-3.5在文科上已经很强了)。另外在Leetcode上,提升也是巨大,hard实现了从0-1的突破做出了3道题,GPT-3.5一道也没做出来,mid和easy题的准确率也是提升很明显。
附录中也给出了GPT-4对一道图文的物理应用题的解题过程,回答确实是非常让人惊艳,步骤清晰明了。

传统NLP任务
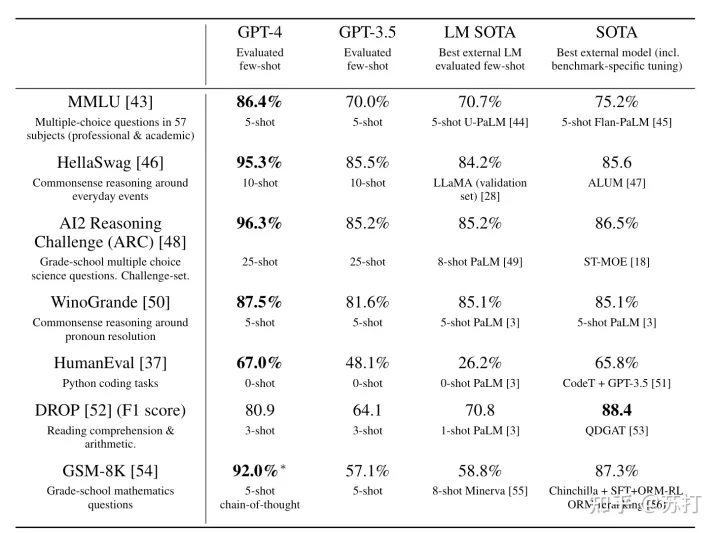
可以看到在各类NLP任务上的few-shot的能力都远远强于之前的大模型,只有DROP这个阅读理解数据集上的性能不如之前的有监督SOTA模型。【但是这个结果,每个任务的shot都不固定,个人认为有精心选择的嫌疑】
多语言能力
从之前的ChatGPT我们就已经发现了它极强的多语言能力(虽然在训练数据集中English占了95%以上)。因此,作者也评价了GPT-4在二十多种语言上的能力。作者将MMLU数据集通过Azure Translate把英文的数据集翻译成了二十多种语言,并对其进行测试。可以看到其多语言能力非常强悍,所有语言都达到了60以上,一半语言在80往上。很惊叹,但是由于OpenAI并没有公开其数据集的语言构成,所以实际上也无法得知GPT-4的多语言能力的强悍性是否来源于数据集中其他语言比例的上升。【而且,实际上机器翻译后的文本存在翻译腔问题,会使得模型性能存在被夸大问题】

图像输入
实际上GPT-4是图文双模态的语言模型,其多模态能力也是很让人惊艳,下面作者给了一个case,来说明GPT-4超强的多模态能力。作者让GPT-4说明下面这张图片有什么笑点。GPT-4很好的理解了其中的笑点,即蓝色的是VGA连接线,原本的VGA是很大的,却被用来给手机当充电线。

利用GPT-4的超强多模态能力也可以做很多事,比如下面几个例子,首先是图表的推理解读。
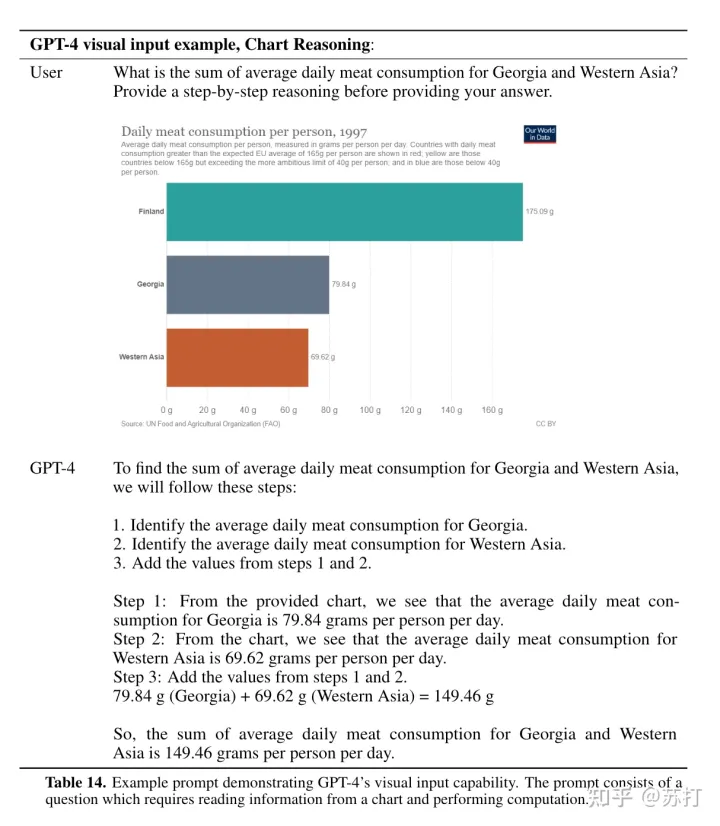
以及可以用它直接来进行图文PDF的阅读理解,帮你读论文。交互式帮助你阅读理解文本【这个期待了】

Limitations
炫完了GPT-4的强悍,作者也在这一章讲了GPT-4的局限性。
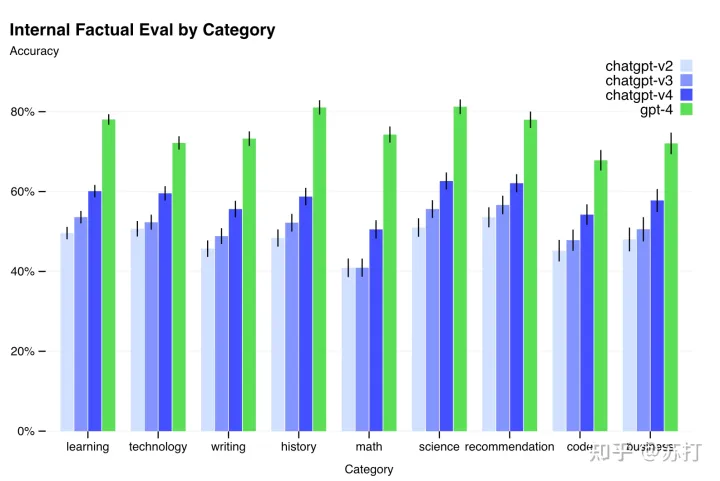
首先是GPT-4仍然会有“幻觉”,以及事实错误问题,但是相比GPT-3.5已经缓解很多。如下面这个表所见,是作者在将前三代的chatgpt与GPT-4在九项内部对抗性设计的真实性评估做对比,可以发现,GPT-4的准确率相比之前的三代chatgpt都有巨大的提升。
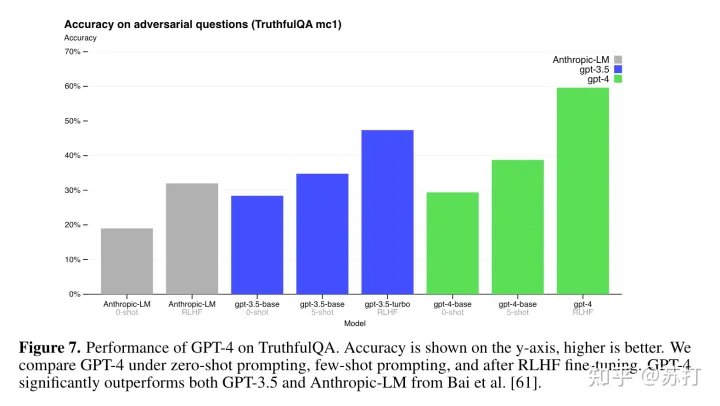
接下来是GPT-4在TruthfulQA上的对比,可以看到,GPT-4-base模型的0-shot准确率相比较前三个已经不相上下了,而经过RLHF训练的GPT-4获得了相比前作的巨大提升。但是仍然还是比较大的提升空间。
Risks & mitigations
这部分文中提出了一个rule-base reward model来自我提升安全性。
与之前的chatGPT一样,作者使用强化学习和人类反馈(RLHF)来微调模型的行为,以产生更好符合用户意图的回答。然而,在RLHF训练之后,模型在不安全输入上仍然很脆弱,有时在安全输入和不安全输入上都表现出不希望看到的行为。在RLHF pipiline的奖励模型数据收集部分,当对标签器的指令未指定时,就会出现这些不希望出现的行为。
当给出不安全的输入时,模型可能会生成不安全的内容,例如给出犯罪建议。此外,模型也可能对安全输入过于谨慎,拒绝无害的请求或过度对冲。为了在更细粒度的级别上引导模型走向适当的行为,作者利用模型本身作为工具。我们的安全方法包括两个主要组成部分,一套额外的安全相关RLHF训练提示(safety-relevant RLHF training prompts),以及基于规则的奖励模型(rule-based reward models (RBRMs))【这部分工作在Anthropic的工作红蓝对抗以及宪法AI中有比较详细的说明,下面贴出这两篇论文,大家有兴趣的话可以看一下。】
之前的文章也有对其中一篇的解读
RBRMs是一组zero-shot GPT-4-based分类器。这些分类器在RLHF针对正确行为(例如拒绝生成有害内容或不拒绝无害请求)进行微调期间向GPT-4策略模型提供额外的奖励信号。RBRM有三个输入:提示(可选)、policy model的输出和人类编写的用于如何评估输出的说明(例如,一组多项选择风格的说明)。然后,RBRM根据标题对输出进行分类。例如,我们可以提供一个规则,指示模型将 模型回答响应 分类为:(a)期望风格的拒绝,(b)不期望风格的拒绝(例如,逃避或语无伦次),(c)包含不允许的内容,或(d)安全的非拒绝响应。然后,在安全相关的训练prompt集上,可以奖励GPT-4拒绝回答这些有害内容,例如非法建议。
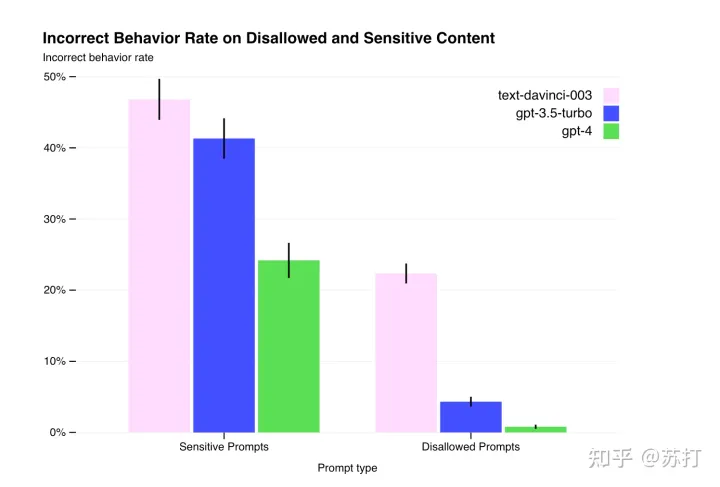
在模型安全性上的提升:可以看到GPT-4在不正确行为上的比例在两类prompts测试集上相较于之前的模型而言都得到了很大的下降。这是很可喜的。
总结
本文对图文多模态预训练语言模型GPT-4的各项能力进行了分析报告。在很多困难和专业性的任务上达到了人类的水平。其multilingual的能力,以及图文的理解能力确实是非常让人惊艳。对于安全性上来说,OpenAI也做了很多的努力。作为一个NLP的研究者,我也是怀着恐惧与兴奋并存的心情来看这篇报告,对于接下来的研究我的看法是,首先是拓展其更多的感知能力,目前仅仅是语言和视觉,触觉行动这个和Embodied AI相关的是未来的研究大方向。其次是要发掘其创造能力,在经过大规模的训练之后,GPT-4是否涌现出了一些令人惊艳的创造能力,这也是我觉得非常值得挖掘的内容。
总之,Ai的已经到了从“蒸汽时代”转向”电气时代“的关键时刻,摒弃之前研究的旧思想,站在大时代变化的浪潮前,拥抱大模型吧。
https://blog.csdn.net/v_JULY_v/article/details/128579457
https://zhuanlan.zhihu.com/p/614250117
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1159
Best Last Month

Information industry by wittx
Information industry by wittx
Information industry by wittx
Information industry by wittx
Computer software and hardware by wittx

Information industry by wittx

Information industry by wittx

Information industry by wittxFast cycling of lithium metal in solid-state batteries by constriction-susceptible anode materials

Information industry by wittx

Information industry by wittx



