
-
News Message
强化学习领域约301篇Accept论文汇总
- by wittx 2024-01-27
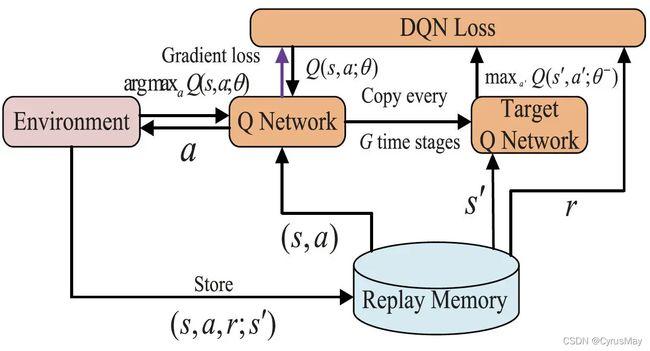
Accept-Oral
[1]. Predictive auxiliary objectives in deep RL mimic learning in the brain [2]. Pre-Training Goal-based Models for Sample-Efficient Reinforcement Learning [3]. Efficient Episodic Memory Utilization of Cooperative Multi-Agent Reinforcement Learning [4]. SWE-bench: Can Language Models Resolve Real-world Github Issues? [5]. MetaGPT: Meta Programming for Multi-Agent Collaborative Framework [6]. METRA: Scalable Unsupervised RL with Metric-Aware Abstraction [7]. Mastering Memory Tasks with World Models [8]. Monte Carlo guided Denoising Diffusion models for Bayesian linear inverse problems. [9]. Learning Interactive Real-World Simulators [10]. Robust agents learn causal world models [11]. A Real-World WebAgent with Planning, Long Context Understanding, and Program Synthesis Accept-Spotlight
[1]. Generalized Policy Iteration using Tensor Approximation for Hybrid Control
[2]. A Theoretical Explanation of Deep RL Performance in Stochastic Environments
[3]. A Benchmark on Robust Semi-Supervised Learning in Open Environments
[4]. Generative Adversarial Inverse Multiagent Learning
[5]. AMAGO: Scalable In-Context Reinforcement Learning for Adaptive Agents
[6]. Confronting Reward Model Overoptimization with Constrained RLHF
[7]. Improved Efficiency Based on Learned Saccade and Continuous Scene Reconstruction From Foveated Visual Sampling
[8]. Harnessing Density Ratios for Online Reinforcement Learning
[9]. Proximal Policy Gradient Arborescence for Quality Diversity Reinforcement Learning
[10]. Social Reward: Evaluating and Enhancing Generative AI through Million-User Feedback from an Online Creative Community
[11]. Improving Offline RL by Blending Heuristics
[12]. Tool-Augmented Reward Modeling
[13]. Reward-Consistent Dynamics Models are Strongly Generalizable for Offline Reinforcement Learning
[14]. Towards Optimal Regret in Adversarial Linear MDPs with Bandit Feedback
[15]. Dual RL: Unification and New Methods for Reinforcement and Imitation Learning
[16]. Stabilizing Contrastive RL: Techniques for Robotic Goal Reaching from Offline Data
[17]. Safe RLHF: Safe Reinforcement Learning from Human Feedback
[18]. Cross$Q$: Batch Normalization in Deep Reinforcement Learning for Greater Sample Efficiency and Simplicity
[19]. Blending Imitation and Reinforcement Learning for Robust Policy Improvement
[20]. On the Role of General Function Approximation in Offline Reinforcement Learning
[21]. Beyond Worst-case Attacks: Robust RL with Adaptive Defense via Non-dominated Policies
[22]. Massively Scalable Inverse Reinforcement Learning for Route Optimization
[23]. Bandits Meet Mechanism Design to Combat Clickbait in Online Recommendation
[24]. Towards Principled Representation Learning from Videos for Reinforcement Learning
[25]. TorchRL: A data-driven decision-making library for PyTorch
[26]. Towards Robust Offline Reinforcement Learning under Diverse Data Corruption
[27]. DyST: Towards Dynamic Neural Scene Representations on Real-World Videos
[28]. Impact of Computation in Integral Reinforcement Learning for Continuous-Time Control
[29]. Maximum Entropy Heterogeneous-Agent Reinforcement Learning
[30]. Learning Hierarchical World Models with Adaptive Temporal Abstractions from Discrete Latent Dynamics
[31]. Text2Reward: Dense Reward Generation with Language Models for Reinforcement Learning
[32]. Submodular Reinforcement Learning
[33]. Query-Policy Misalignment in Preference-Based Reinforcement Learning
[34]. Kernel Metric Learning for In-Sample Off-Policy Evaluation of Deterministic RL Policies
[35]. Provable Offline Preference-Based Reinforcement Learning
[36]. Provable Reward-Agnostic Preference-Based Reinforcement Learning
[37]. Entity-Centric Reinforcement Learning for Object Manipulation from Pixels
[38]. Constrained Bi-Level Optimization: Proximal Lagrangian Value function Approach and Hessian-free Algorithm
[39]. Addressing Signal Delay in Deep Reinforcement Learning
[40]. DrM: Mastering Visual Reinforcement Learning through Dormant Ratio Minimization
[41]. RealChat-1M: A Large-Scale Real-World LLM Conversation Dataset
[42]. EfficientDM: Efficient Quantization-Aware Fine-Tuning of Low-Bit Diffusion Models
[43]. SocioDojo: Building Lifelong Analytical Agents with Real-world Text and Time Series
[44]. Quasi-Monte Carlo for 3D Sliced Wasserstein
[45]. Cascading Reinforcement Learning
[46]. Task Adaptation from Skills: Information Geometry, Disentanglement, and New Objectives for Unsupervised Reinforcement Learning
[47]. Efficient Distributed Training with Full Communication-Computation Overlap
[48]. PTaRL: Prototype-based Tabular Representation Learning via Space Calibration
[49]. $\mathcal{B}$-Coder: On Value-Based Deep Reinforcement Learning for Program Synthesis
[50]. Physics-Regulated Deep Reinforcement Learning: Invariant Embeddings
[51]. Retroformer: Retrospective Large Language Agents with Policy Gradient Optimization
[52]. Open-ended VQA benchmarking of Vision-Language models by exploiting Classification datasets and their semantic hierarchy
[53]. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
[54]. SEAL: A Framework for Systematic Evaluation of Real-World Super-Resolution
[55]. BarLeRIa: An Efficient Tuning Framework for Referring Image Segmentation
[56]. Q-Bench: A Benchmark for General-Purpose Foundation Models on Low-level Vision
[57]. TD-MPC2: Scalable, Robust World Models for Continuous Control
[58]. Adaptive Rational Activations to Boost Deep Reinforcement Learning
[59]. Robust Adversarial Reinforcement Learning via Bounded Rationality Curricula
Accept-poster
[1]. Locality Sensitive Sparse Encoding for Learning World Models Online
[2]. Demonstration-Regularized RL
[3]. KoLA: Carefully Benchmarking World Knowledge of Large Language Models
[4]. On Representation Complexity of Model-based and Model-free Reinforcement Learning
[5]. RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems
[6]. Policy Rehearsing: Training Generalizable Policies for Reinforcement Learning
[7]. NP-GL: Extending Power of Nature from Binary Problems to Real-World Graph Learning
[8]. Pessimistic Nonlinear Least-Squares Value Iteration for Offline Reinforcement Learning
[9]. Improving Language Models with Advantage-based Offline Policy Gradients
[10]. Dichotomy of Early and Late Phase Implicit Biases Can Provably Induce Grokking
[11]. PromptAgent: Strategic Planning with Language Models Enables Expert-level Prompt Optimization
[12]. Large Language Models as Automated Aligners for benchmarking Vision-Language Models
[13]. Reverse Diffusion Monte Carlo
[14]. PlaSma: Procedural Knowledge Models for Language-based Planning and Re-Planning
[15]. Towards Foundational Models for Molecular Learning on Large-Scale Multi-Task Datasets
[16]. Training Diffusion Models with Reinforcement Learning
[17]. Finite-Time Analysis of On-Policy Heterogeneous Federated Reinforcement Learning
[18]. Federated Q-Learning: Linear Regret Speedup with Low Communication Cost
[19]. The Trickle-down Impact of Reward Inconsistency on RLHF
[20]. Maximum Entropy Model Correction in Reinforcement Learning
[21]. Simple Hierarchical Planning with Diffusion
[22]. Regularized Robust MDPs and Risk-Sensitive MDPs: Equivalence, Policy Gradient, and Sample Complexity
[23]. Curriculum reinforcement learning for quantum architecture search under hardware errors
[24]. Variance-aware Regret Bounds for Stochastic Contextual Dueling Bandits
[25]. Directly Fine-Tuning Diffusion Models on Differentiable Rewards
[26]. Tree Search-Based Policy Optimization under Stochastic Execution Delay
[27]. Offline RL with Observation Histories: Analyzing and Improving Sample Complexity
[28]. Understanding Hidden Context in Preference Learning: Consequences for RLHF
[29]. Eureka: Human-Level Reward Design via Coding Large Language Models
[30]. Active Retrosynthetic Planning Aware of Route Quality
[31]. Fiber Monte Carlo
[32]. Retrieval-Guided Reinforcement Learning for Boolean Circuit Minimization
[33]. Provable Benefits of Multi-task RL under Non-Markovian Decision Making Processes
[34]. Follow-the-Perturbed-Leader for Adversarial Bandits: Heavy Tails, Robustness, and Privacy
[35]. ViLMA: A Zero-Shot Benchmark for Linguistic and Temporal Grounding in Video-Language Models
[36]. Score Models for Offline Goal-Conditioned Reinforcement Learning
[37]. A Policy Gradient Method for Confounded POMDPs
[38]. Achieving Fairness in Multi-Agent MDP Using Reinforcement Learning
[39]. Escape Sky-high Cost: Early-stopping Self-Consistency for Multi-step Reasoning
[40]. Customizable Combination of Parameter-Efficient Modules for Multi-Task Learning
[41]. Hindsight PRIORs for Reward Learning from Human Preferences
[42]. Reward Model Ensembles Help Mitigate Overoptimization
[43]. Feasibility-Guided Safe Offline Reinforcement Learning
[44]. Compositional Conservatism: A Transductive Approach in Offline Reinforcement Learning
[45]. Flow to Better: Offline Preference-based Reinforcement Learning via Preferred Trajectory Generation
[46]. PAE: Reinforcement Learning from External Knowledge for Efficient Exploration
[47]. Yet Another ICU Benchmark: A Flexible Multi-Center Framework for Clinical ML
[48]. Identifying Policy Gradient Subspaces
[49]. Contextual Bandits with Online Neural Regression
[50]. PARL: A Unified Framework for Policy Alignment in Reinforcement Learning
[51]. SafeDreamer: Safe Reinforcement Learning with World Models
[52]. MetaCoCo: A New Few-Shot Classification Benchmark with Spurious Correlation
[53]. GnnX-Bench: Unravelling the Utility of Perturbation-based GNN Explainers through In-depth Benchmarking
[54]. Confidence-aware Reward Optimization for Fine-tuning Text-to-Image Models
[55]. Provably Efficient Iterated CVaR Reinforcement Learning with Function Approximation and Human Feedback
[56]. Goodhart's Law in Reinforcement Learning
[57]. Score Regularized Policy Optimization through Diffusion Behavior
[58]. Making RL with Preference-based Feedback Efficient via Randomization
[59]. Adaptive Regret for Bandits Made Possible: Two Queries Suffice
[60]. Negatively Correlated Ensemble Reinforcement Learning for Online Diverse Game Level Generation
[61]. Achieving Sample and Computational Efficient Reinforcement Learning by Action Space Reduction via Grouping
[62]. Demystifying Linear MDPs and Novel Dynamics Aggregation Framework
[63]. PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization
[64]. Steve-Eye: Equipping LLM-based Embodied Agents with Visual Perception in Open Worlds
[65]. Consistency Models as a Rich and Efficient Policy Class for Reinforcement Learning
[66]. Contrastive Preference Learning: Learning from Human Feedback without Reinforcement Learning
[67]. Privileged Sensing Scaffolds Reinforcement Learning
[68]. Learning Planning Abstractions from Language
[69]. Tailoring Self-Rationalizers with Multi-Reward Distillation
[70]. Building Cooperative Embodied Agents Modularly with Large Language Models
[71]. A Black-box Approach for Non-stationary Multi-agent Reinforcement Learning
[72]. CrossLoco: Human Motion Driven Control of Legged Robots via Guided Unsupervised Reinforcement Learning
[73]. Let Models Speak Ciphers: Multiagent Debate through Embeddings
[74]. Learning interpretable control inputs and dynamics underlying animal locomotion
[75]. Does Progress On Object Recognition Benchmarks Improve Generalization on Crowdsourced, Global Data?
[76]. Jumanji: a Diverse Suite of Scalable Reinforcement Learning Environments in JAX
[77]. Searching for High-Value Molecules Using Reinforcement Learning and Transformers
[78]. Exploiting Causal Graph Priors with Posterior Sampling for Reinforcement Learning
[79]. Towards Diverse Behaviors: A Benchmark for Imitation Learning with Human Demonstrations
[80]. Privately Aligning Language Models with Reinforcement Learning
[81]. On the Expressivity of Objective-Specification Formalisms in Reinforcement Learning
[82]. S$2$AC: Energy-Based Reinforcement Learning with Stein Soft Actor Critic
[83]. Robust Model-Based Optimization for Challenging Fitness Landscapes
[84]. Replay across Experiments: A Natural Extension of Off-Policy RL
[85]. BEND: Benchmarking DNA Language Models on Biologically Meaningful Tasks
[86]. Piecewise Linear Parametrization of Policies: Towards Interpretable Deep Reinforcement Learning
[87]. Time-Efficient Reinforcement Learning with Stochastic Stateful Policies
[88]. Open the Black Box: Step-based Policy Updates for Temporally-Correlated Episodic Reinforcement Learning
[89]. Incentivized Truthful Communication for Federated Bandits
[90]. Diffusion Generative Flow Samplers: Improving learning signals through partial trajectory optimization
[91]. On Trajectory Augmentations for Off-Policy Evaluation
[92]. Understanding the Effects of RLHF on LLM Generalisation and Diversity
[93]. Beyond Stationarity: Convergence Analysis of Stochastic Softmax Policy Gradient Methods
[94]. Delphic Offline Reinforcement Learning under Nonidentifiable Hidden Confounding
[95]. Prioritized Soft Q-Decomposition for Lexicographic Reinforcement Learning
[96]. GlucoBench: Curated List of Continuous Glucose Monitoring Datasets with Prediction Benchmarks
[97]. Incentive-Aware Federated Learning with Training-Time Model Rewards
[98]. Early Neuron Alignment in Two-layer ReLU Networks with Small Initialization
[99]. Sample-Efficiency in Multi-Batch Reinforcement Learning: The Need for Dimension-Dependent Adaptivity
[100]. Off-Policy Primal-Dual Safe Reinforcement Learning
[101]. STARC: A General Framework For Quantifying Differences Between Reward Functions
[102]. GAIA: a benchmark for General AI Assistants
[103]. Unleashing the Power of Pre-trained Language Models for Offline Reinforcement Learning
[104]. Discovering Temporally-Aware Reinforcement Learning Algorithms
[105]. Revisiting Data Augmentation in Deep Reinforcement Learning
[106]. Reward-Free Curricula for Training Robust World Models
[107]. Provable and Practical: Efficient Exploration in Reinforcement Learning via Langevin Monte Carlo
[108]. CPPO: Continual Learning for Reinforcement Learning with Human Feedback
[109]. Game-Theoretic Robust Reinforcement Learning Handles Temporally-Coupled Perturbations
[110]. Bandits with Replenishable Knapsacks: the Best of both Worlds
[111]. A Study of Generalization in Offline Reinforcement Learning
[112]. Diverse Projection Ensembles for Distributional Reinforcement Learning
[113]. MIntRec2.0: A Large-scale Benchmark Dataset for Multimodal Intent Recognition and Out-of-scope Detection in Conversations
[114]. RLIF: Interactive Imitation Learning as Reinforcement Learning
[115]. Bongard-OpenWorld: Few-Shot Reasoning for Free-form Visual Concepts in the Real World
[116]. Uni-O4: Unifying Online and Offline Deep Reinforcement Learning with Multi-Step On-Policy Optimization
[117]. FFB: A Fair Fairness Benchmark for In-Processing Group Fairness Methods
[118]. EasyTPP: Towards Open Benchmarking Temporal Point Processes
[119]. Uni-O4: Unifying Online and Offline Deep Reinforcement Learning with Multi-Step On-Policy Optimization
[120]. FFB: A Fair Fairness Benchmark for In-Processing Group Fairness Methods
[121]. EasyTPP: Towards Open Benchmarking Temporal Point Processes
[122]. Combinatorial Bandits for Maximum Value Reward Function under Value-Index Feedback
[123]. Alice Benchmarks: Connecting Real World Object Re-Identification with the Synthetic
[124]. Video Language Planning
[125]. Transformers as Decision Makers: Provable In-Context Reinforcement Learning via Supervised Pretraining
[126]. Learning Over Molecular Conformer Ensembles: Datasets and Benchmarks
[127]. Free from Bellman Completeness: Trajectory Stitching via Model-based Return-conditioned Supervised Learning
[128]. Diffusion Models for Multi-Task Generative Modeling
[129]. Neural Active Learning Beyond Bandits
[130]. Revisiting Plasticity in Visual Reinforcement Learning: Data, Modules and Training Stages
[131]. Sample-efficient Learning of Infinite-horizon Average-reward MDPs with General Function Approximation
[132]. Offline Data Enhanced On-Policy Policy Gradient with Provable Guarantees
[133]. SALMON: Self-Alignment with Principle-Following Reward Models
[134]. Test-Time Adaptation with CLIP Reward for Zero-Shot Generalization in Vision-Language Models
[135]. SemiReward: A General Reward Model for Semi-supervised Learning
[136]. Horizon-Free Regret for Linear Markov Decision Processes
[137]. On Differentially Private Federated Linear Contextual Bandits
[138]. Neural Neighborhood Search for Multi-agent Path Finding
[139]. Understanding when Dynamics-Invariant Data Augmentations Benefit Model-free Reinforcement Learning Updates
[140]. Sample Efficient Myopic Exploration Through Multitask Reinforcement Learning with Diverse Tasks
[141]. The Update Equivalence Framework for Decision-Time Planning
[142]. Learning Reusable Dense Rewards for Multi-Stage Tasks
[143]. Time Fairness in Online Knapsack Problems
[144]. On the Hardness of Constrained Cooperative Multi-Agent Reinforcement Learning
[145]. RLCD: Reinforcement Learning from Contrastive Distillation for LM Alignment
[146]. Reasoning with Latent Diffusion in Offline Reinforcement Learning
[147]. Low Rank Matrix Completion via Robust Alternating Minimization in Nearly Linear Time
[148]. Belief-Enriched Pessimistic Q-Learning against Adversarial State Perturbations
[149]. SmartPlay : A Benchmark for LLMs as Intelligent Agents
[150]. SOHES: Self-supervised Open-world Hierarchical Entity Segmentation
[151]. Robust NAS benchmark under adversarial training: assessment, theory, and beyond
[152]. SCHEMA: State CHangEs MAtter for Procedure Planning in Instructional Videos
[153]. DNABERT-2: Efficient Foundation Model and Benchmark For Multi-Species Genomes
[154]. Reward Design for Justifiable Sequential Decision-Making
[155]. Fast Value Tracking for Deep Reinforcement Learning
[156]. MAMBA: an Effective World Model Approach for Meta-Reinforcement Learning
[157]. Tree-Planner: Efficient Close-loop Task Planning with Large Language Models
[158]. LOQA: Learning with Opponent Q-Learning Awareness
[159]. Intelligent Switching for Reset-Free RL
[160]. On the Limitations of Temperature Scaling for Distributions with Overlaps
[161]. True Knowledge Comes from Practice: Aligning Large Language Models with Embodied Environments via Reinforcement Learning
[162]. Skill Machines: Temporal Logic Skill Composition in Reinforcement Learning
[163]. Who to imitate: Imitating desired behavior from divserse multi-agent datasets
[164]. SweetDreamer: Aligning Geometric Priors in 2D diffusion for Consistent Text-to-3D
[165]. Uni-RLHF: Universal Platform and Benchmark Suite for Reinforcement Learning with Diverse Human Feedback
[166]. Vision-Language Models are Zero-Shot Reward Models for Reinforcement Learning
[167]. Learning Multi-Agent Communication from Graph Modeling Perspective
[168]. Efficient Multi-agent Reinforcement Learning by Planning
[169]. Sample-Efficient Multi-Agent RL: An Optimization Perspective
[170]. CausalTime: Realistically Generated Time-series for Benchmarking of Causal Discovery
[171]. SRL: Scaling Distributed Reinforcement Learning to Over Ten Thousand Cores
[172]. Plan-Seq-Learn: Language Model Guided RL for Solving Long Horizon Robotics Tasks
[173]. Robust Model Based Reinforcement Learning Using $\mathcal{L}_1$ Adaptive Control
[174]. Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion
[175]. Parameter-Efficient Multi-Task Model Fusion with Partial Linearizeation
[176]. Horizon-free Reinforcement Learning in Adversarial Linear Mixture MDPs
[177]. Multi-task Learning with 3D-Aware Regularization
[178]. DMBP: Diffusion model based predictor for robust offline reinforcement learning against state observation perturbations
[179]. Alignment as Reward-Guided Search
[180]. Multi-Task Reinforcement Learning with Mixture of Orthogonal Experts
[181]. Retro-fallback: retrosynthetic planning in an uncertain world
[182]. Duolando: Follower GPT with Off-Policy Reinforcement Learning for Dance Accompaniment
[183]. AdaMerging: Adaptive Model Merging for Multi-Task Learning
[184]. MetaTool Benchmark: Deciding Whether to Use Tools and Which to Use
[185]. AdjointDPM: Adjoint Sensitivity Method for Gradient Backpropagation of Diffusion Probabilistic Models
[186]. Integrating Planning and Deep Reinforcement Learning via Automatic Induction of Task Substructures
[187]. LoTa-Bench: Benchmarking Language-oriented Task Planners for Embodied Agents
[188]. Outliers with Opposing Signals Have an Outsized Effect on Neural Network Optimization
[189]. Threshold-Consistent Margin Loss for Open-World Deep Metric Learning
[190]. Rethinking Adversarial Policies: A Generalized Attack Formulation and Provable Defense in RL
[191]. Learning Multi-Agent Communication with Contrastive Learning
[192]. Closing the Gap between TD Learning and Supervised Learning - A Generalisation Point of View.
[193]. On Stationary Point Convergence of PPO-Clip
[194]. Provably Efficient CVaR RL in Low-rank MDPs
[195]. COPlanner: Plan to Roll Out Conservatively but to Explore Optimistically for Model-Based RL
[196]. Transport meets Variational Inference: Controlled Monte Carlo Diffusions
[197]. In-context Exploration-Exploitation for Reinforcement Learning
[198]. The All-Seeing Project: Towards Panoptic Visual Recognition and Understanding of the Open World
[199]. TASK PLANNING FOR VISUAL ROOM REARRANGEMENT UNDER PARTIAL OBSERVABILITY
[200]. Optimal Sample Complexity for Average Reward Markov Decision Processes
[201]. DreamSmooth: Improving Model-based Reinforcement Learning via Reward Smoothing
[202]. Meta Inverse Constrained Reinforcement Learning: Convergence Guarantee and Generalization Analysis
[203]. Cleanba: A Reproducible and Efficient Distributed Reinforcement Learning Platform
[204]. Combining Spatial and Temporal Abstraction in Planning for Better Generalization
[205]. Decision Transformer is a Robust Contender for Offline Reinforcement Learning
[206]. ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
[207]. Bridging State and History Representations: Understanding Self-Predictive RL
[208]. InstructDET: Diversifying Referring Object Detection with Generalized Instructions
[209]. Deep Reinforcement Learning Guided Improvement Heuristic for Job Shop Scheduling
[210]. GRAPH-CONSTRAINED DIFFUSION FOR END-TO-END PATH PLANNING
[211]. Efficient Backdoor Attacks for Deep Neural Networks in Real-world Scenarios
[212]. VertiBench: Advancing Feature Distribution Diversity in Vertical Federated Learning Benchmarks
[213]. Grounding Multimodal Large Language Models to the World
[214]. VFLAIR: A Research Library and Benchmark for Vertical Federated Learning
[215]. Stylized Offline Reinforcement Learning: Extracting Diverse High-Quality Behaviors from Heterogeneous Datasets
[216]. Sample-Efficient Learning of POMDPs with Multiple Observations In Hindsight
[217]. Pre-training with Synthetic Data Helps Offline Reinforcement Learning
[218]. AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors
[219]. Efficient Planning with Latent Diffusion
[220]. A Benchmark Study on Calibration
[221]. Attention-Guided Contrastive Role Representations for Multi-agent Reinforcement Learning
[222]. Query-Dependent Prompt Evaluation and Optimization with Offline Inverse RL
[223]. Quantifying the Sensitivity of Inverse Reinforcement Learning to Misspecification
[224]. Byzantine Robust Cooperative Multi-Agent Reinforcement Learning as a Bayesian Game
[225]. AutoVP: An Automated Visual Prompting Framework and Benchmark
[226]. AutoCast++: Enhancing World Event Prediction with Zero-shot Ranking-based Context Retrieval
[227]. REValueD: Regularised Ensemble Value-Decomposition for Factorisable Markov Decision Processes
[228]. Language Model Self-improvement by Reinforcement Learning Contemplation
[229]. Towards Offline Opponent Modeling with In-context Learning
[230]. Early Stopping Against Label Noise Without Validation Data
[231]. Langevin Monte Carlo for strongly log-concave distributions: Randomized midpoint revisited
Accept-Oral
[1]. Predictive auxiliary objectives in deep RL mimic learning in the brain [2]. Pre-Training Goal-based Models for Sample-Efficient Reinforcement Learning [3]. Efficient Episodic Memory Utilization of Cooperative Multi-Agent Reinforcement Learning [4]. SWE-bench: Can Language Models Resolve Real-world Github Issues? [5]. MetaGPT: Meta Programming for Multi-Agent Collaborative Framework [6]. METRA: Scalable Unsupervised RL with Metric-Aware Abstraction [7]. Mastering Memory Tasks with World Models [8]. Monte Carlo guided Denoising Diffusion models for Bayesian linear inverse problems. [9]. Learning Interactive Real-World Simulators [10]. Robust agents learn causal world models [11]. A Real-World WebAgent with Planning, Long Context Understanding, and Program Synthesis Accept-Spotlight
[1]. Generalized Policy Iteration using Tensor Approximation for Hybrid Control
[2]. A Theoretical Explanation of Deep RL Performance in Stochastic Environments
[3]. A Benchmark on Robust Semi-Supervised Learning in Open Environments
[4]. Generative Adversarial Inverse Multiagent Learning
[5]. AMAGO: Scalable In-Context Reinforcement Learning for Adaptive Agents
[6]. Confronting Reward Model Overoptimization with Constrained RLHF
[7]. Improved Efficiency Based on Learned Saccade and Continuous Scene Reconstruction From Foveated Visual Sampling
[8]. Harnessing Density Ratios for Online Reinforcement Learning
[9]. Proximal Policy Gradient Arborescence for Quality Diversity Reinforcement Learning
[10]. Social Reward: Evaluating and Enhancing Generative AI through Million-User Feedback from an Online Creative Community
[11]. Improving Offline RL by Blending Heuristics
[12]. Tool-Augmented Reward Modeling
[13]. Reward-Consistent Dynamics Models are Strongly Generalizable for Offline Reinforcement Learning
[14]. Towards Optimal Regret in Adversarial Linear MDPs with Bandit Feedback
[15]. Dual RL: Unification and New Methods for Reinforcement and Imitation Learning
[16]. Stabilizing Contrastive RL: Techniques for Robotic Goal Reaching from Offline Data
[17]. Safe RLHF: Safe Reinforcement Learning from Human Feedback
[18]. Cross$Q$: Batch Normalization in Deep Reinforcement Learning for Greater Sample Efficiency and Simplicity
[19]. Blending Imitation and Reinforcement Learning for Robust Policy Improvement
[20]. On the Role of General Function Approximation in Offline Reinforcement Learning
[21]. Beyond Worst-case Attacks: Robust RL with Adaptive Defense via Non-dominated Policies
[22]. Massively Scalable Inverse Reinforcement Learning for Route Optimization
[23]. Bandits Meet Mechanism Design to Combat Clickbait in Online Recommendation
[24]. Towards Principled Representation Learning from Videos for Reinforcement Learning
[25]. TorchRL: A data-driven decision-making library for PyTorch
[26]. Towards Robust Offline Reinforcement Learning under Diverse Data Corruption
[27]. DyST: Towards Dynamic Neural Scene Representations on Real-World Videos
[28]. Impact of Computation in Integral Reinforcement Learning for Continuous-Time Control
[29]. Maximum Entropy Heterogeneous-Agent Reinforcement Learning
[30]. Learning Hierarchical World Models with Adaptive Temporal Abstractions from Discrete Latent Dynamics
[31]. Text2Reward: Dense Reward Generation with Language Models for Reinforcement Learning
[32]. Submodular Reinforcement Learning
[33]. Query-Policy Misalignment in Preference-Based Reinforcement Learning
[34]. Kernel Metric Learning for In-Sample Off-Policy Evaluation of Deterministic RL Policies
[35]. Provable Offline Preference-Based Reinforcement Learning
[36]. Provable Reward-Agnostic Preference-Based Reinforcement Learning
[37]. Entity-Centric Reinforcement Learning for Object Manipulation from Pixels
[38]. Constrained Bi-Level Optimization: Proximal Lagrangian Value function Approach and Hessian-free Algorithm
[39]. Addressing Signal Delay in Deep Reinforcement Learning
[40]. DrM: Mastering Visual Reinforcement Learning through Dormant Ratio Minimization
[41]. RealChat-1M: A Large-Scale Real-World LLM Conversation Dataset
[42]. EfficientDM: Efficient Quantization-Aware Fine-Tuning of Low-Bit Diffusion Models
[43]. SocioDojo: Building Lifelong Analytical Agents with Real-world Text and Time Series
[44]. Quasi-Monte Carlo for 3D Sliced Wasserstein
[45]. Cascading Reinforcement Learning
[46]. Task Adaptation from Skills: Information Geometry, Disentanglement, and New Objectives for Unsupervised Reinforcement Learning
[47]. Efficient Distributed Training with Full Communication-Computation Overlap
[48]. PTaRL: Prototype-based Tabular Representation Learning via Space Calibration
[49]. $\mathcal{B}$-Coder: On Value-Based Deep Reinforcement Learning for Program Synthesis
[50]. Physics-Regulated Deep Reinforcement Learning: Invariant Embeddings
[51]. Retroformer: Retrospective Large Language Agents with Policy Gradient Optimization
[52]. Open-ended VQA benchmarking of Vision-Language models by exploiting Classification datasets and their semantic hierarchy
[53]. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
[54]. SEAL: A Framework for Systematic Evaluation of Real-World Super-Resolution
[55]. BarLeRIa: An Efficient Tuning Framework for Referring Image Segmentation
[56]. Q-Bench: A Benchmark for General-Purpose Foundation Models on Low-level Vision
[57]. TD-MPC2: Scalable, Robust World Models for Continuous Control
[58]. Adaptive Rational Activations to Boost Deep Reinforcement Learning
[59]. Robust Adversarial Reinforcement Learning via Bounded Rationality Curricula
Accept-poster
[1]. Locality Sensitive Sparse Encoding for Learning World Models Online
[2]. Demonstration-Regularized RL
[3]. KoLA: Carefully Benchmarking World Knowledge of Large Language Models
[4]. On Representation Complexity of Model-based and Model-free Reinforcement Learning
[5]. RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems
[6]. Policy Rehearsing: Training Generalizable Policies for Reinforcement Learning
[7]. NP-GL: Extending Power of Nature from Binary Problems to Real-World Graph Learning
[8]. Pessimistic Nonlinear Least-Squares Value Iteration for Offline Reinforcement Learning
[9]. Improving Language Models with Advantage-based Offline Policy Gradients
[10]. Dichotomy of Early and Late Phase Implicit Biases Can Provably Induce Grokking
[11]. PromptAgent: Strategic Planning with Language Models Enables Expert-level Prompt Optimization
[12]. Large Language Models as Automated Aligners for benchmarking Vision-Language Models
[13]. Reverse Diffusion Monte Carlo
[14]. PlaSma: Procedural Knowledge Models for Language-based Planning and Re-Planning
[15]. Towards Foundational Models for Molecular Learning on Large-Scale Multi-Task Datasets
[16]. Training Diffusion Models with Reinforcement Learning
[17]. Finite-Time Analysis of On-Policy Heterogeneous Federated Reinforcement Learning
[18]. Federated Q-Learning: Linear Regret Speedup with Low Communication Cost
[19]. The Trickle-down Impact of Reward Inconsistency on RLHF
[20]. Maximum Entropy Model Correction in Reinforcement Learning
[21]. Simple Hierarchical Planning with Diffusion
[22]. Regularized Robust MDPs and Risk-Sensitive MDPs: Equivalence, Policy Gradient, and Sample Complexity
[23]. Curriculum reinforcement learning for quantum architecture search under hardware errors
[24]. Variance-aware Regret Bounds for Stochastic Contextual Dueling Bandits
[25]. Directly Fine-Tuning Diffusion Models on Differentiable Rewards
[26]. Tree Search-Based Policy Optimization under Stochastic Execution Delay
[27]. Offline RL with Observation Histories: Analyzing and Improving Sample Complexity
[28]. Understanding Hidden Context in Preference Learning: Consequences for RLHF
[29]. Eureka: Human-Level Reward Design via Coding Large Language Models
[30]. Active Retrosynthetic Planning Aware of Route Quality
[31]. Fiber Monte Carlo
[32]. Retrieval-Guided Reinforcement Learning for Boolean Circuit Minimization
[33]. Provable Benefits of Multi-task RL under Non-Markovian Decision Making Processes
[34]. Follow-the-Perturbed-Leader for Adversarial Bandits: Heavy Tails, Robustness, and Privacy
[35]. ViLMA: A Zero-Shot Benchmark for Linguistic and Temporal Grounding in Video-Language Models
[36]. Score Models for Offline Goal-Conditioned Reinforcement Learning
[37]. A Policy Gradient Method for Confounded POMDPs
[38]. Achieving Fairness in Multi-Agent MDP Using Reinforcement Learning
[39]. Escape Sky-high Cost: Early-stopping Self-Consistency for Multi-step Reasoning
[40]. Customizable Combination of Parameter-Efficient Modules for Multi-Task Learning
[41]. Hindsight PRIORs for Reward Learning from Human Preferences
[42]. Reward Model Ensembles Help Mitigate Overoptimization
[43]. Feasibility-Guided Safe Offline Reinforcement Learning
[44]. Compositional Conservatism: A Transductive Approach in Offline Reinforcement Learning
[45]. Flow to Better: Offline Preference-based Reinforcement Learning via Preferred Trajectory Generation
[46]. PAE: Reinforcement Learning from External Knowledge for Efficient Exploration
[47]. Yet Another ICU Benchmark: A Flexible Multi-Center Framework for Clinical ML
[48]. Identifying Policy Gradient Subspaces
[49]. Contextual Bandits with Online Neural Regression
[50]. PARL: A Unified Framework for Policy Alignment in Reinforcement Learning
[51]. SafeDreamer: Safe Reinforcement Learning with World Models
[52]. MetaCoCo: A New Few-Shot Classification Benchmark with Spurious Correlation
[53]. GnnX-Bench: Unravelling the Utility of Perturbation-based GNN Explainers through In-depth Benchmarking
[54]. Confidence-aware Reward Optimization for Fine-tuning Text-to-Image Models
[55]. Provably Efficient Iterated CVaR Reinforcement Learning with Function Approximation and Human Feedback
[56]. Goodhart's Law in Reinforcement Learning
[57]. Score Regularized Policy Optimization through Diffusion Behavior
[58]. Making RL with Preference-based Feedback Efficient via Randomization
[59]. Adaptive Regret for Bandits Made Possible: Two Queries Suffice
[60]. Negatively Correlated Ensemble Reinforcement Learning for Online Diverse Game Level Generation
[61]. Achieving Sample and Computational Efficient Reinforcement Learning by Action Space Reduction via Grouping
[62]. Demystifying Linear MDPs and Novel Dynamics Aggregation Framework
[63]. PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization
[64]. Steve-Eye: Equipping LLM-based Embodied Agents with Visual Perception in Open Worlds
[65]. Consistency Models as a Rich and Efficient Policy Class for Reinforcement Learning
[66]. Contrastive Preference Learning: Learning from Human Feedback without Reinforcement Learning
[67]. Privileged Sensing Scaffolds Reinforcement Learning
[68]. Learning Planning Abstractions from Language
[69]. Tailoring Self-Rationalizers with Multi-Reward Distillation
[70]. Building Cooperative Embodied Agents Modularly with Large Language Models
[71]. A Black-box Approach for Non-stationary Multi-agent Reinforcement Learning
[72]. CrossLoco: Human Motion Driven Control of Legged Robots via Guided Unsupervised Reinforcement Learning
[73]. Let Models Speak Ciphers: Multiagent Debate through Embeddings
[74]. Learning interpretable control inputs and dynamics underlying animal locomotion
[75]. Does Progress On Object Recognition Benchmarks Improve Generalization on Crowdsourced, Global Data?
[76]. Jumanji: a Diverse Suite of Scalable Reinforcement Learning Environments in JAX
[77]. Searching for High-Value Molecules Using Reinforcement Learning and Transformers
[78]. Exploiting Causal Graph Priors with Posterior Sampling for Reinforcement Learning
[79]. Towards Diverse Behaviors: A Benchmark for Imitation Learning with Human Demonstrations
[80]. Privately Aligning Language Models with Reinforcement Learning
[81]. On the Expressivity of Objective-Specification Formalisms in Reinforcement Learning
[82]. S$2$AC: Energy-Based Reinforcement Learning with Stein Soft Actor Critic
[83]. Robust Model-Based Optimization for Challenging Fitness Landscapes
[84]. Replay across Experiments: A Natural Extension of Off-Policy RL
[85]. BEND: Benchmarking DNA Language Models on Biologically Meaningful Tasks
[86]. Piecewise Linear Parametrization of Policies: Towards Interpretable Deep Reinforcement Learning
[87]. Time-Efficient Reinforcement Learning with Stochastic Stateful Policies
[88]. Open the Black Box: Step-based Policy Updates for Temporally-Correlated Episodic Reinforcement Learning
[89]. Incentivized Truthful Communication for Federated Bandits
[90]. Diffusion Generative Flow Samplers: Improving learning signals through partial trajectory optimization
[91]. On Trajectory Augmentations for Off-Policy Evaluation
[92]. Understanding the Effects of RLHF on LLM Generalisation and Diversity
[93]. Beyond Stationarity: Convergence Analysis of Stochastic Softmax Policy Gradient Methods
[94]. Delphic Offline Reinforcement Learning under Nonidentifiable Hidden Confounding
[95]. Prioritized Soft Q-Decomposition for Lexicographic Reinforcement Learning
[96]. GlucoBench: Curated List of Continuous Glucose Monitoring Datasets with Prediction Benchmarks
[97]. Incentive-Aware Federated Learning with Training-Time Model Rewards
[98]. Early Neuron Alignment in Two-layer ReLU Networks with Small Initialization
[99]. Sample-Efficiency in Multi-Batch Reinforcement Learning: The Need for Dimension-Dependent Adaptivity
[100]. Off-Policy Primal-Dual Safe Reinforcement Learning
[101]. STARC: A General Framework For Quantifying Differences Between Reward Functions
[102]. GAIA: a benchmark for General AI Assistants
[103]. Unleashing the Power of Pre-trained Language Models for Offline Reinforcement Learning
[104]. Discovering Temporally-Aware Reinforcement Learning Algorithms
[105]. Revisiting Data Augmentation in Deep Reinforcement Learning
[106]. Reward-Free Curricula for Training Robust World Models
[107]. Provable and Practical: Efficient Exploration in Reinforcement Learning via Langevin Monte Carlo
[108]. CPPO: Continual Learning for Reinforcement Learning with Human Feedback
[109]. Game-Theoretic Robust Reinforcement Learning Handles Temporally-Coupled Perturbations
[110]. Bandits with Replenishable Knapsacks: the Best of both Worlds
[111]. A Study of Generalization in Offline Reinforcement Learning
[112]. Diverse Projection Ensembles for Distributional Reinforcement Learning
[113]. MIntRec2.0: A Large-scale Benchmark Dataset for Multimodal Intent Recognition and Out-of-scope Detection in Conversations
[114]. RLIF: Interactive Imitation Learning as Reinforcement Learning
[115]. Bongard-OpenWorld: Few-Shot Reasoning for Free-form Visual Concepts in the Real World
[116]. Uni-O4: Unifying Online and Offline Deep Reinforcement Learning with Multi-Step On-Policy Optimization
[117]. FFB: A Fair Fairness Benchmark for In-Processing Group Fairness Methods
[118]. EasyTPP: Towards Open Benchmarking Temporal Point Processes
[119]. Uni-O4: Unifying Online and Offline Deep Reinforcement Learning with Multi-Step On-Policy Optimization
[120]. FFB: A Fair Fairness Benchmark for In-Processing Group Fairness Methods
[121]. EasyTPP: Towards Open Benchmarking Temporal Point Processes
[122]. Combinatorial Bandits for Maximum Value Reward Function under Value-Index Feedback
[123]. Alice Benchmarks: Connecting Real World Object Re-Identification with the Synthetic
[124]. Video Language Planning
[125]. Transformers as Decision Makers: Provable In-Context Reinforcement Learning via Supervised Pretraining
[126]. Learning Over Molecular Conformer Ensembles: Datasets and Benchmarks
[127]. Free from Bellman Completeness: Trajectory Stitching via Model-based Return-conditioned Supervised Learning
[128]. Diffusion Models for Multi-Task Generative Modeling
[129]. Neural Active Learning Beyond Bandits
[130]. Revisiting Plasticity in Visual Reinforcement Learning: Data, Modules and Training Stages
[131]. Sample-efficient Learning of Infinite-horizon Average-reward MDPs with General Function Approximation
[132]. Offline Data Enhanced On-Policy Policy Gradient with Provable Guarantees
[133]. SALMON: Self-Alignment with Principle-Following Reward Models
[134]. Test-Time Adaptation with CLIP Reward for Zero-Shot Generalization in Vision-Language Models
[135]. SemiReward: A General Reward Model for Semi-supervised Learning
[136]. Horizon-Free Regret for Linear Markov Decision Processes
[137]. On Differentially Private Federated Linear Contextual Bandits
[138]. Neural Neighborhood Search for Multi-agent Path Finding
[139]. Understanding when Dynamics-Invariant Data Augmentations Benefit Model-free Reinforcement Learning Updates
[140]. Sample Efficient Myopic Exploration Through Multitask Reinforcement Learning with Diverse Tasks
[141]. The Update Equivalence Framework for Decision-Time Planning
[142]. Learning Reusable Dense Rewards for Multi-Stage Tasks
[143]. Time Fairness in Online Knapsack Problems
[144]. On the Hardness of Constrained Cooperative Multi-Agent Reinforcement Learning
[145]. RLCD: Reinforcement Learning from Contrastive Distillation for LM Alignment
[146]. Reasoning with Latent Diffusion in Offline Reinforcement Learning
[147]. Low Rank Matrix Completion via Robust Alternating Minimization in Nearly Linear Time
[148]. Belief-Enriched Pessimistic Q-Learning against Adversarial State Perturbations
[149]. SmartPlay : A Benchmark for LLMs as Intelligent Agents
[150]. SOHES: Self-supervised Open-world Hierarchical Entity Segmentation
[151]. Robust NAS benchmark under adversarial training: assessment, theory, and beyond
[152]. SCHEMA: State CHangEs MAtter for Procedure Planning in Instructional Videos
[153]. DNABERT-2: Efficient Foundation Model and Benchmark For Multi-Species Genomes
[154]. Reward Design for Justifiable Sequential Decision-Making
[155]. Fast Value Tracking for Deep Reinforcement Learning
[156]. MAMBA: an Effective World Model Approach for Meta-Reinforcement Learning
[157]. Tree-Planner: Efficient Close-loop Task Planning with Large Language Models
[158]. LOQA: Learning with Opponent Q-Learning Awareness
[159]. Intelligent Switching for Reset-Free RL
[160]. On the Limitations of Temperature Scaling for Distributions with Overlaps
[161]. True Knowledge Comes from Practice: Aligning Large Language Models with Embodied Environments via Reinforcement Learning
[162]. Skill Machines: Temporal Logic Skill Composition in Reinforcement Learning
[163]. Who to imitate: Imitating desired behavior from divserse multi-agent datasets
[164]. SweetDreamer: Aligning Geometric Priors in 2D diffusion for Consistent Text-to-3D
[165]. Uni-RLHF: Universal Platform and Benchmark Suite for Reinforcement Learning with Diverse Human Feedback
[166]. Vision-Language Models are Zero-Shot Reward Models for Reinforcement Learning
[167]. Learning Multi-Agent Communication from Graph Modeling Perspective
[168]. Efficient Multi-agent Reinforcement Learning by Planning
[169]. Sample-Efficient Multi-Agent RL: An Optimization Perspective
[170]. CausalTime: Realistically Generated Time-series for Benchmarking of Causal Discovery
[171]. SRL: Scaling Distributed Reinforcement Learning to Over Ten Thousand Cores
[172]. Plan-Seq-Learn: Language Model Guided RL for Solving Long Horizon Robotics Tasks
[173]. Robust Model Based Reinforcement Learning Using $\mathcal{L}_1$ Adaptive Control
[174]. Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion
[175]. Parameter-Efficient Multi-Task Model Fusion with Partial Linearizeation
[176]. Horizon-free Reinforcement Learning in Adversarial Linear Mixture MDPs
[177]. Multi-task Learning with 3D-Aware Regularization
[178]. DMBP: Diffusion model based predictor for robust offline reinforcement learning against state observation perturbations
[179]. Alignment as Reward-Guided Search
[180]. Multi-Task Reinforcement Learning with Mixture of Orthogonal Experts
[181]. Retro-fallback: retrosynthetic planning in an uncertain world
[182]. Duolando: Follower GPT with Off-Policy Reinforcement Learning for Dance Accompaniment
[183]. AdaMerging: Adaptive Model Merging for Multi-Task Learning
[184]. MetaTool Benchmark: Deciding Whether to Use Tools and Which to Use
[185]. AdjointDPM: Adjoint Sensitivity Method for Gradient Backpropagation of Diffusion Probabilistic Models
[186]. Integrating Planning and Deep Reinforcement Learning via Automatic Induction of Task Substructures
[187]. LoTa-Bench: Benchmarking Language-oriented Task Planners for Embodied Agents
[188]. Outliers with Opposing Signals Have an Outsized Effect on Neural Network Optimization
[189]. Threshold-Consistent Margin Loss for Open-World Deep Metric Learning
[190]. Rethinking Adversarial Policies: A Generalized Attack Formulation and Provable Defense in RL
[191]. Learning Multi-Agent Communication with Contrastive Learning
[192]. Closing the Gap between TD Learning and Supervised Learning - A Generalisation Point of View.
[193]. On Stationary Point Convergence of PPO-Clip
[194]. Provably Efficient CVaR RL in Low-rank MDPs
[195]. COPlanner: Plan to Roll Out Conservatively but to Explore Optimistically for Model-Based RL
[196]. Transport meets Variational Inference: Controlled Monte Carlo Diffusions
[197]. In-context Exploration-Exploitation for Reinforcement Learning
[198]. The All-Seeing Project: Towards Panoptic Visual Recognition and Understanding of the Open World
[199]. TASK PLANNING FOR VISUAL ROOM REARRANGEMENT UNDER PARTIAL OBSERVABILITY
[200]. Optimal Sample Complexity for Average Reward Markov Decision Processes
[201]. DreamSmooth: Improving Model-based Reinforcement Learning via Reward Smoothing
[202]. Meta Inverse Constrained Reinforcement Learning: Convergence Guarantee and Generalization Analysis
[203]. Cleanba: A Reproducible and Efficient Distributed Reinforcement Learning Platform
[204]. Combining Spatial and Temporal Abstraction in Planning for Better Generalization
[205]. Decision Transformer is a Robust Contender for Offline Reinforcement Learning
[206]. ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
[207]. Bridging State and History Representations: Understanding Self-Predictive RL
[208]. InstructDET: Diversifying Referring Object Detection with Generalized Instructions
[209]. Deep Reinforcement Learning Guided Improvement Heuristic for Job Shop Scheduling
[210]. GRAPH-CONSTRAINED DIFFUSION FOR END-TO-END PATH PLANNING
[211]. Efficient Backdoor Attacks for Deep Neural Networks in Real-world Scenarios
[212]. VertiBench: Advancing Feature Distribution Diversity in Vertical Federated Learning Benchmarks
[213]. Grounding Multimodal Large Language Models to the World
[214]. VFLAIR: A Research Library and Benchmark for Vertical Federated Learning
[215]. Stylized Offline Reinforcement Learning: Extracting Diverse High-Quality Behaviors from Heterogeneous Datasets
[216]. Sample-Efficient Learning of POMDPs with Multiple Observations In Hindsight
[217]. Pre-training with Synthetic Data Helps Offline Reinforcement Learning
[218]. AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors
[219]. Efficient Planning with Latent Diffusion
[220]. A Benchmark Study on Calibration
[221]. Attention-Guided Contrastive Role Representations for Multi-agent Reinforcement Learning
[222]. Query-Dependent Prompt Evaluation and Optimization with Offline Inverse RL
[223]. Quantifying the Sensitivity of Inverse Reinforcement Learning to Misspecification
[224]. Byzantine Robust Cooperative Multi-Agent Reinforcement Learning as a Bayesian Game
[225]. AutoVP: An Automated Visual Prompting Framework and Benchmark
[226]. AutoCast++: Enhancing World Event Prediction with Zero-shot Ranking-based Context Retrieval
[227]. REValueD: Regularised Ensemble Value-Decomposition for Factorisable Markov Decision Processes
[228]. Language Model Self-improvement by Reinforcement Learning Contemplation
[229]. Towards Offline Opponent Modeling with In-context Learning
[230]. Early Stopping Against Label Noise Without Validation Data
[231]. Langevin Monte Carlo for strongly log-concave distributions: Randomized midpoint revisited
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1301
Best Last Month

Information industry by wittx
Information industry by wittx
Information industry by wittx

Information industry by wittx

Information industry by wittx
Information industry by wittx

Information industry by wittx
Information industry by wittx

Information industry by wittx
Information industry by wittx
