News Message
AAAI 2020 三篇论文解读问答系统最新研究进展
- by wittx 2020-04-13
本篇聚焦 AAAI 2020 中与问答系统(Q&A)相关的文章。问答系统是自然语言处理领域的一个重要研究方向,近年来各大国际会议、期刊都发表了大量与问答系统相关的研究成果,实际工业界中也有不少落地的应用场景,核心算法涉及机器学习、深度学习等知识。问答系统(Q&A)的主要研究点包括模型构建、对问题/答案编码、引入语义特征、引入强化学习、内容选择、问题类型建模、引入上下文信息以及实际应用场景问题解决等。在本次 AAAI2020 中,直接以「Question/Answer」作为题目的论文就有 40 余篇。本文选取了其中三篇进行详细讨论,内容涉及语义特征匹配、模型构建和医学场景应用等。
1、Improving Question Generation with Sentence-level Semantic Matching and Answer Position Inferring
论文地址:https://arxiv.org/pdf/1912.00879.pdf

本文介绍的是佛罗里达大学吴大鹏教授组的工作,主要聚焦问答系统(Q&A)的反问题---问题生成(Question Generation,Q&G)。问题生成的目的是在给定上下文和相应答案的情况下生成语义相关的问题,问题生成在教育场景、对话系统、问答助手等应用领域具有巨大的潜力。问题生成任务可分为两类:一类是基于规则的方法,即在不深入理解上下文语义的情况下手动设计词汇规则或模板,将上下文转换成问题。另一类是基于神经网络的、直接从语句片段中生成问题词汇的方法,包括序列-序列模型(seq-to-seq)、编码器解码器(encoder-decoder)等。本文讨论的是后一种基于神经网络的问题生成方法。
目前,基于神经网络的问题生成模型主要面临以下两个问题:(1)错误的关键词和疑问词:模型可能会使用错误的关键词和疑问词来提问(见表 1);(2)糟糕的复制机制:模型复制与答案语义无关的上下文单词(见表 2)。表 1 和表 2 中使用的基线算法为 NQG++[1] 和 Pointer-generator[2]。

表 1. 关键词和疑问词错误的基线实验

表 2. 复制机制错误的基线实验
作者认为,现有的基于神经网络的问题生成模型之所以出现上述两个问题是因为:(1)解码器在生成过程中可能只关注局部词语义而忽略全局问题语义;(2)复制机制没有很好地利用答案位置感知特征,导致从输入中复制与答案无关的上下文单词。为了解决这两个问题,作者提出以多任务学习(Multi-Task Learning,MTL)的方式学习句子级语义,以及引入答案位置感知,如表 1 和表 2 所示,「Our model」为本文提出模型在相同实验条件下生成的问题。图 1 给出本文提出的具有句子级语义匹配、答案位置推断和门控融合的神经问题生成模型图。
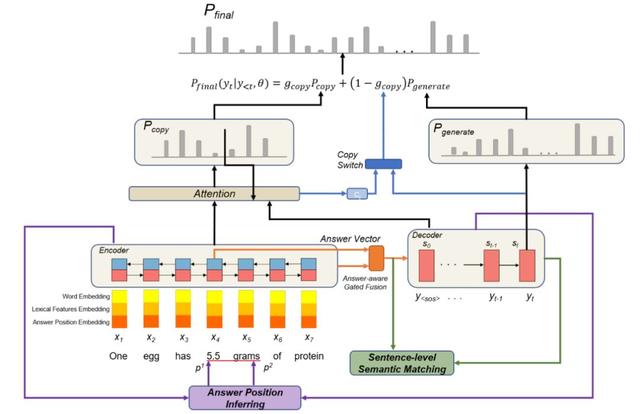
图 1. 本文提出的模型图
给定包含答案 A 的语句 X=[x1,x2,...,xm],基于连续扩展的语句,生成与 X 和 A 语义匹配的问题 Y。与文献 [1] 的方法一致,利用扩展的语义和词汇特征、部分语音标签、答案位置特征等作为 seq-to-seq 模型嵌入层的输入,利用双向 LSTM 作为编码器,通过链接前向隐藏状态和后向隐藏状态生成句子表示 H=[h1,h2,...,hm]:

答案感知门控融合(Answer-aware Gated Fusion):使用两个由 Sigmoid 函数计算的信息流门来控制句子向量和答案向量的信息流,将答案起始位置的隐藏状态作为答案向量 h_a,使用双向 LSTM 编码整个答案语义。
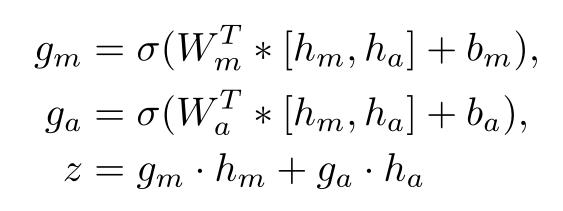
解码器(Decoder):以编码器的隐藏状态 H=[h1,h2,…,hm] 作为上下文和改进的答案感知句子向量 z 作为初始隐藏状态 s1,一层单向 LSTM 用先前解码的单词作为输入 wt 更新其当前隐藏状态 st。

利用注意力机制将当前解码器状态 s_t 赋给编码器上下文 H=[h1,h2,…,hm]。使用归一化处理后的注意向量α_t 的加权求和结果计算上下文向量 c_t。基于词典 V,计算问题单词 y_t:

其中,f 由两层前馈网络实现。
注意力机制(Copy Mechanism):使用注意力机制生成大小为 V 的单词,或从输入语句 X 中复制单词。在生成问题词 y_t 时,考虑到当前解码器的隐藏状态 s_t 和上下文向量 c_t,计算一个复制开关来确定生成的词是从字典生成的还是从源语句复制的。
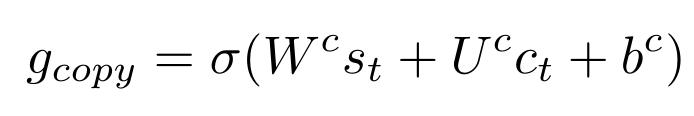
生成模式概率和复制模式概率相结合,得到最终的单词分布:
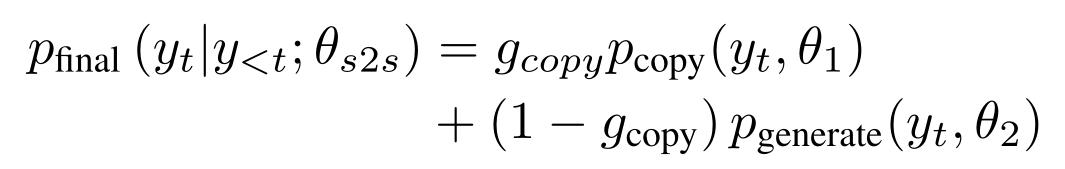
使用负对数似然来计算序列-序列的损失:

句子级语义匹配(Sentence-level Semantic Matching):通过门控融合得到了改进的答案感知句子向量 z。对于解码器(单向 LSTM),采用最后一个隐藏状态 s_n 作为问题向量。训练两个分类器,分别将非语义匹配对 [z,S』_n](S,Q』)和 [z』,S_n](S,Q)与语义匹配对 [z,S_n](S,Q)区分开来,其中 z』和 s』是同一段落中随机抽取的不匹配句子和问题的向量。
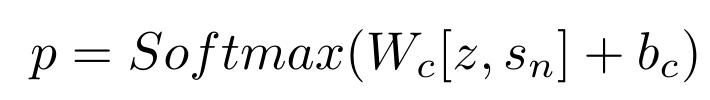
将两个分类器的二元交叉熵之和作为句子级语义匹配损失:

具体流程见图 2 所示。

图 2. 句子级语义匹配
答案位置推断(Answer Position Inferring):引入双向注意力流网络 [3] 推断答案位置,见图 3。
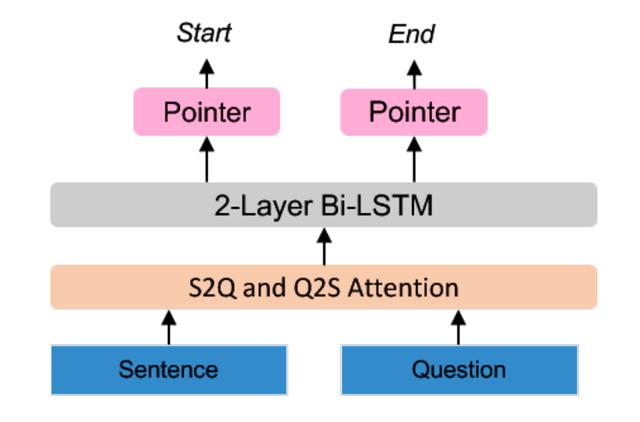
图 3. 答案位置推断框架
采用句子对问题(Sentence-to-Question,S2Q)注意和问题对句子(Question-to-Sentence,Q2S)注意来强调每个句子词和每个问题词之间的相互语义关联,并利用相似的注意机制得到了问题感知的句子表征 H 和句子感知的问题表征 S:
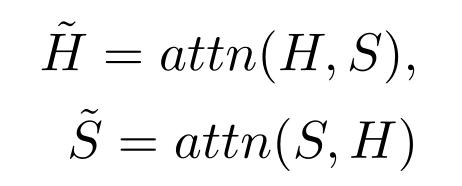
然后,使用两个两层双向 LSTMs 来捕获以问题为条件的句子词之间的相互作用。答案起始索引和结束索引由输出层使用 Softmax 函数预测:
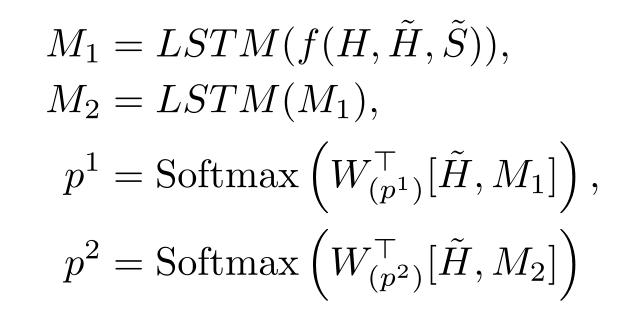
其中,f 函数是一个可训练的多层感知(MLP)网络。使用真值答案起始标记 y1 和结束标记的负对数似然来计算损失:

为了在多任务学习方法中联合训练生成模型和所提出的模块,训练过程中的总损失函数记为:

作者在 SQuAD 和 MARCO 两个数据集上进行了实验,使用 NQG++[1]、Point-generator[2] 以及 SOTA 模型、门控自注意力机制模型等作为基线对比算法。表 3 给出了 SQuAD 和 MS-MARCO 数据集上不同模型的主要指标,在文章所述的实验条件下,本文提出的模型在全部主要指标上都优于基线对比算法。

表 3. SQuAD 和 MARCO 数据集主要指标的模型性能比较
小结:与现有的问答系统、问题生成模型的处理方式不同,本文并不是通过引入更多的有效特征或者改进复制机制本身等来改进模型效果,而是直接在经典序列-序列模型(seq-to-seq)中增加了两个模块:句子级语义匹配模块和答案位置推断模块。此外,利用答案感知门控融合机制来增强解码器的初始状态,从而进一步改进模型的处理效果。
2、TANDA: Transfer and Adapt Pre-Trained Transformer Models for Answer Sentence Selection
论文地址:https://arxiv.org/pdf/1911.04118.pdf

这篇文章聚焦的是问答系统(Q&A)中的另外一个问题:回答句子选择(Answer Sentence Selection,AS2),给定一个问题和一组候选答案句子,选择出正确回答问题的句子(例如,由搜索引擎检索)。AS2 是目前虚拟客服中普遍采用的技术,例如 Google Home、Alexa、Siri 等,即采用搜索引擎+AS2 的模式。
在自然语言处理领域中使用基于神经网络的模型,通过对大量数据进行神经网络预训练来获取单词及其复合词之间的依赖关系,之后再做精调(fine-tuning)以满足在专门的目标领域中的应用。本文的主要工作包括两方面:一,提出一种基于变压器(Transformer-based)的 AS2 模型,为解决 AS2 的数据稀缺性问题和精调步骤的不稳定性提供了有效的解决方案。二,构建了一个应用于 AS2 的数据库 ASNQ(Answer Sentence Natural Questions)。
本文提出了一种用于自然语言任务的预训练变换模型精调的有效技术-TANDA( Transfer AND Adapt)。首先通过使用一个大而高质量的数据集对模型进行精调,将一个预先训练的模型转换为一个用于一般任务的模型。然后,执行第二个精调步骤,以使传输的模型适应目标域。TANDA 架构如图 4(以 BERT 为例)。
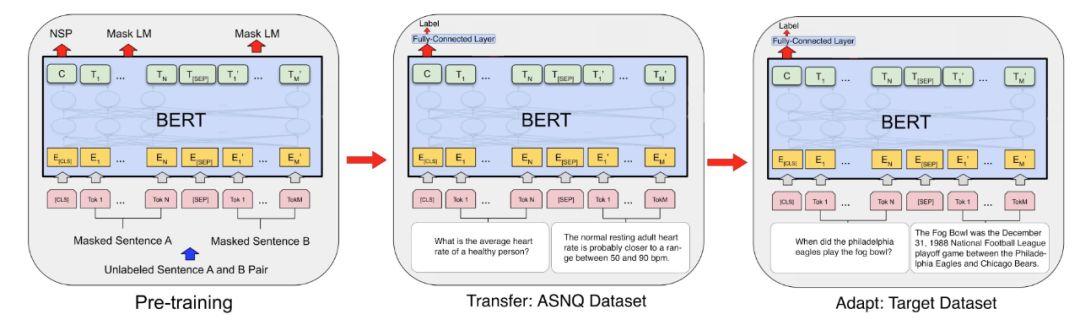
图 4. TANDA 整体架构
AS2 任务:给定问题 q 和答案句子库 S={s1,...,sn},AS2 任务目的是找到能够正确回答 q 的句子 s_k,r(q,S)=s_k,其中 k=argmax p(q,s_i),使用神经网络模型计算 p(q,s_i)。
变压器模型 (Transformer Model):变压器模型的目的是捕获单词间的依赖关系。图 5 给出文本对分类任务的变压器模型架构。输入包括两条文本,Tok^1 和 Tok^2,由三个标记 [CLS]、[SEP] 和 [EOS] 分隔。将根据令牌、段及其位置编码的嵌入向量作为输入,输入到多头注意力机制、归一化、前向反馈处理的神经网络中。输出为表征文本对的嵌入向量 x,x 描述单词、句子分段之间的依赖关系。将 x 输入到全连接层中,输出层用于最终的任务,例如,应用 softmax 对文本对分类的概率进行建模:
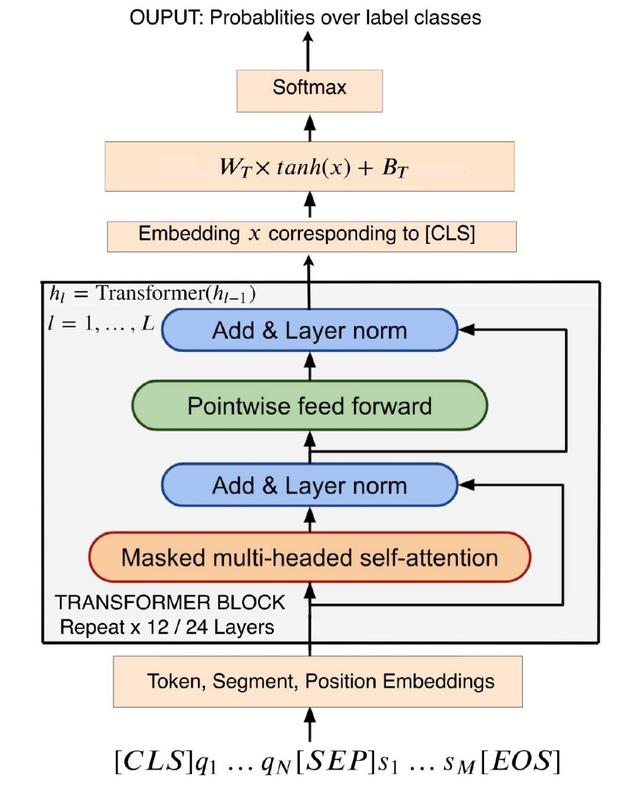
图 4. 带有线性分类器的变压器结构

其中,W_T、B_T 为全连接层的权重。在实际应用中,一般需要使用大量监督数据完成这一步的训练任务。
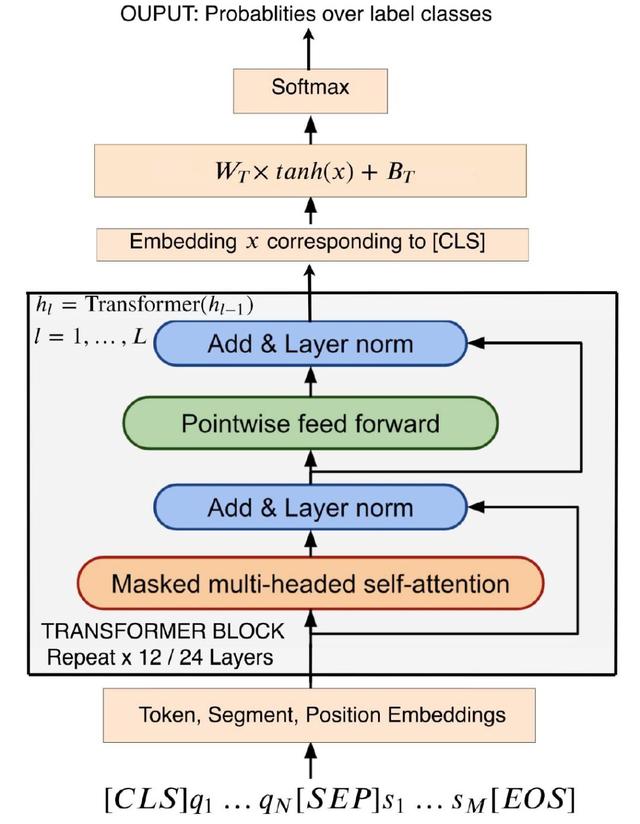
图 5. 使用线性分类器做 AS2 精调的变压器结构
TANDA:在经典的任务中,一般只针对目标任务和域进行一次模型精调。对于 AS2,训练数据是由问题和答案组成的包含正负标签(答案是否正确回答了问题)的句子对。当训练样本数据较少时,完成 AS2 任务的模型稳定性较差,此时在新任务中推广需要大量样本来精调大量的变压器参数。本文提出,将精调过程分为两个步骤:转移到任务,然后适应目标域。
首先,使用 AS2 的大型通用数据集完成标准的精调处理。这个步骤应该将语言模型迁移到具体的 AS2 任务。由于目标域的特殊性(AS2),所得到的模型在目标域的数据上无法达到最佳性能,此时采用第二个精调步骤使分类器适应目标域。
TANDA 的处理方式是在通用数据库和目标域数据库中分别做精调(一次 fine-tuning → 二次 fine-tuning)。这里有一个很直观的质疑,同时在通用数据库和目标数据库中训练+精调是否也可以达到同样的效果且节省处理时间?但是实际上,这样的组合很难优化,因为在精调模型步骤中,处理目标数据与处理通用数据所需要的权重并不相同。作者在后续的实验中专门针对这个问题进行了验证,即在通用、目标数据库中做两次精调处理的效果优于在合并的通用+目标数据库做一次精调处理的效果。
ASNQ:本文构建了一个专门适用于 AS2 任务的通用数据库 ASNQ。ASNQ 基于经典 NQ 语料库建设 [4],NQ 是用于机器阅读(Machine Reading,MR)任务的语料库,其中每个问题与一个 Wiki 页面关联。针对每一个问题,一个长段落 (long_answer) 包含从参考页面中提取的答案,其中包含多个标记为 short_answer 的段落。由于 long_answer 中包含多条语句,因此 NQ 并不直接适用于 AS2 任务。
在构建 ASNQ 的过程中,针对目标问题,正标签的答案数据表示在 NQ 中 long_answer 中出现的语句,它可能包含了多个 short answer;其余的语句均标记为负标签,具体包括:1)在 NQ 中 long_answer 中出现的语句但是不包括标记的 short answer;2)没在 NQ 中 long_answer 中出现的语句,但是包含了 short answer;3)没在 NQ 中 long_answer 中出现的语句,也不包含 short answer。
ASNQ 有四个标签,用来描述候选句子可能的混淆程度。对 NQ 的训练集和开发集执行相同的处理,图 6 中示出了一个示例,表 4 则给出了 ASNQ 统计信息。ASNQ 在训练集中包含 57242 个不同的问题,在开发集中包含 2672 个不同的问题,这比大多数公开的 AS2 数据集都大一个数量级。对于 TANDA 中的转移(Transfer)步骤,我们使用带有标签 1、2 和 3 的 ASNQ 句子对作为否定,标签 4 作为肯定。

图 6. 从 NQ 到 ASNQ 的数据转换示例

表 4. ASNQ 的标签说明。这里的 S、LA、SA 分别指的是回答句、长句和短句
本文分别在实验库和工业环境库中进行实验。其中,实验基准库为 WikiQA、TREC-QA 和 ONLI。在神经网络模型的选择上,使用预先训练的 BERT-Base(12 层)、BERT-Large(24 层)、RoBERTa-Base(12 层)和 RoBERTa-Large-MNLI(24 层)模型。训练阶段,采用 Adam 优化器,将 BERT/RoBERTa 的最大序列长度设为 128 个 Token。

表 5.WikiQA 数据集上不同模型的性能
表 5 给出 WikiQA 数据集上不同模型的性能,这里 Comp-Agg+LM+LC 是指 Y-oon 等人提出的具有语言建模和潜在聚类的比较格雷盖特模型 [5]。TL(QNLI)是指从 QNLI 语料库中进行的迁移学习。L 和 B 分别达标较大数据库和基线数据库。相较于其它算法,TANDA 获得了很大的改进,RoBERTa-Large TANDA 使用 ASNQ→WikiQA 在 WikiQA 上 MAP 为 0.920、MRR 为 0.933。最后,在本实验中,仅在 ASNQ 中的标准精调处理就已经超过了先前模型效果,这主要是因为 ASNQ 和 WikiQA 都是由 Wikipedia 的答案组成的。

表 6. 不同模型在 TREC-QA 数据集上的性能
表 6 给出不同模型在 TREC-QA 数据集上的性能,在本实验中,TANDA 的效果优于已有模型。另外,仅在 ASNQ 上使用精调(FT)得到的模型效果与预期相同,由于 TREC 问题的目标域与 ASNQ 的目标域显著不同,因此仅在 ASNQ 中的标准精调处理的性能远低于任何 TANDA 模型,也低于直接在 TREC-QA 上进行精调处理的性能。
本文还针对直接合并 ASNQ 和 TREC-QA 的数据集进行了精调测试,在 ASNQ->TREC-QA 上精调的 BERT-Base 模型得到的 MAP 和 MRR 分别为 0.898 和 0.929,明显低于表 6 中给出的 0.912 MAP 和 0.951 MRR 的值。
最后,本文选择亚马逊的 Alexa Visual Assistant 进行工业场景中的实验。基于三个带有信息意图的问题样本构建了三个测试集,这些问题可以用非结构化文本来回答。样本 1 的问题是从 NQ 问题中提取的,而样本 2 和样本 3 的问题是从 Alexa 用户的问题中生成的。对于每个问题,我们从搜索引擎检索的顶级文档中选择了 100 个句子候选:(i)对于生成样本 1 和样本 2,使用了一个弹性搜索系统,该系统包含多个 web 域,范围包括 Wikipedia、 toreference.com、coolantarctica.com、www.cia.gov/library 等;(ii)对于生成样本 3,使用一个商业搜索引擎以获得更高的检索质量。此外,使用与样本 2 相似的方法构建了一个噪声数据集(NAD),每个问题只检索 10 个候选。这使得对大量问题进行更便宜的注释成为可能,对于构建有效的训练集非常重要。表 7 给出数据库的情况。


表 7. 样本 1、2、3 统计精确测试集和添加噪声的数据集
使用 ASNQ 作为通用数据集,使用 NAD 作为自适应步骤的目标数据集。表 8 中所有使用 NAD 进行训练和精确数据集进行测试的实验均表明,TANDA 对真实的 NAD 噪声具有很强的鲁棒性,其效果总是优于简单的精调方法。
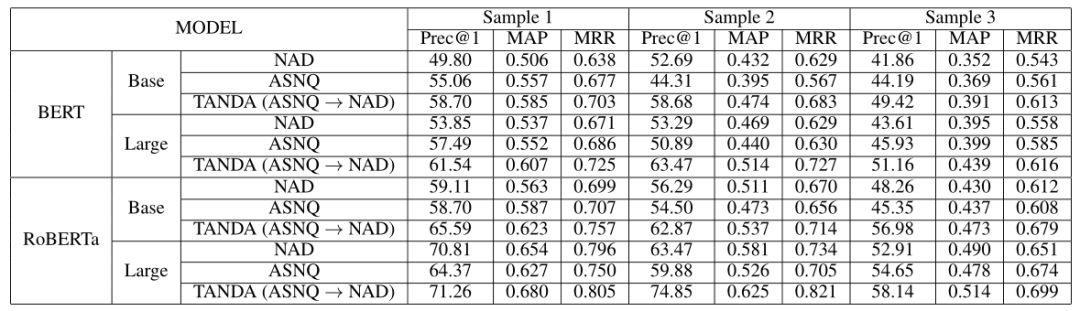
表 8. 基于 Alexa 真实数据集的精调 FT 与 TANDA 的比较
小结:本文的工作实际上是将经典的精调(fine-tuning)过程拆成了两次,其中一次针对通用数据集,另一次针对目标数据集,此外,还专门构建了适用于 AS2 任务的通用数据集 ASNQ。本文在两个著名的实验基准库:WikiQA 和 TREC-QA 上进行实验,分别达到了 92% 和 94.3% 的 MAP 分数,超过了近期获得的 83.4% 和 87.5% 的最高分数。本文还讨论了 TANDA 在受不同类型噪声影响的 Alexa 特定数据集中的实验,确认了 TANDA 在工业环境中的有效性。
3、On the Generation of Medical Question-Answer Pairs
论文地址:https://arxiv.org/pdf/1811.00681.pdf

这篇文章具体介绍问答系统(Q&A)在医学场景中的应用。随着网络发展,越来越多的人希望能够在线获取医疗健康相关的帮助,特别是对于医疗资源有限的地区,这种方式能够大大减少病人到医院就诊的次数,从而缓解医疗压力。尽管问答系统在诸多领域中应用都获得了很好的效果,但在医学场景中仍面临很多困难。首先,医疗在线问答依赖于准确、专业的医学知识;其次,用预训练模型的高质量的医学标记问答语句对非常少,基于神经网络的问答系统在缺少训练数据的情况下,很难生成有效模型。
本文的工作主要是生成医学问答语句对(QA 对)。假设每个医学答案对应一个有效问题的分布,而有效问题的分布应该受到外部医学知识的约束。遵循这一假设,如果能够在与原始 QA 对相同的知识基础上生成更多的高质量 QA 对,就可以补充现有医学 QA 对的潜在分布,从而使医学 QA 系统更容易学习无偏模型。医学 QA 对的生成面临的主要问题是很难同时保持生成 QA 对的多样性和有效性。
为了解决多样性和有效性的问题,本文提出了整合结构化和非结构化知识的两种机制来生成 QA 对。首先利用分层条件变分自动编码器(Conditional Variational Auto-encoder,CVAE)框架来解决全局短语级别的多样性和有效性问题,该框架模拟了原始医学 QA 对中的短语级别关系,在不破坏这些关系的情况下生成新的 QA 对。然后,本文提出了一个多通道解码器,其中所有的本地组件(短语类型、每个短语中的实体)耦合在一起,并以端到端的方式进行联合优化。框架整体结构见图 7,整个框架包括一个关键短语检测器和一个基于实体引导的 CVAE 生成器(eg-CVAE),最终将原始的和由该框架生成的 QA 对输入到 QA 系统中完成训练。

图 7. 本文提出的生成 QA 对的框架图示
由于医学问题的特殊性,在进行医学领域问答系统研究时,一般假定多个问题可能对应同一个答案。由此,生成医学 QA 对的问题可以看做:给定一个答案,生成可能的问题语句。本文提出的生成医学 QA 对的框架可以看做是给定答案和新问题样本的情况下,计算问题潜在可能性的问题。根据图 7 所示,该框架由下述几个部分组成。
关键短语检测器(Key Phrase Detector):每一条医学问题 Q 都由多个短语 Pk 组成,包括病人的症状、检查结果等,每个短语都包含若干个单词。所述关键短语是指与答案高度相关的短语。
首先使用每个医疗 QA 对作为查询,对给定的医疗信息执行基于 Elasticsearch 的检索 [6]。同时,使用规则来确保检索文本中存在答案,表示为 Ri, i∈[1,M](M 表示检索文本的数量)。本文提出了一种无监督的匹配策略,通过将某个短语的 Pk 与所有的 Ri 进行匹配,来建立该短语 Pk 与答案的相关性模型。具体来讲,将每个 Ri 划分为短语 P^(Ri)。通过对词嵌入特征 v_j, j∈[1,L] 进行多级池化处理,在同一个向量空间中表示 P^(Ri) 和 Pk[7]。计算每个 Pk 与其对应的 P^(Ri),i∈[1,M] 的 cosine 距离,将最高值存储为 (s_k)^(Ri)。QA 对中每个短语 Pk 的这些分数将被规范化为 s_k,s_k∈[0,1],以便使用最小-最大方法进行最终抽样决策。
基于实体引导的 CVAE 生成器(Entity-guided CVAE based Generator):一个医学问题有两个层次结构:一个结构存在于短语中,它由涉及的医疗实体的局部信息支配,另一个结构是一个独特的跨短语结构,它主要由短语类型和相应的答案等决定。本文在两个层次中探索答案条件下的医学问题生成:子序列(迭代短语生成过程)和单词子序列。首先,使用条件变分自动编码器(VAE)对整个问题进行约束建模,之后,再对每个短语的内部结构进行建模。在内部建模过程中引入了三步解码过程:先隐式类型(type)建模,然后显式实体(entity)建模,最后是短语解码。
(1)CVAE 生成器的整体结构见图 8。本文使用经典的 CAVE 框架 [7] 用于生成对话,该框架将生成过程看作是一个迭代的短语处理过程。使用三个随机变量表示每个短语生成过程:短语上下文 c、目标短语 x 和用于捕获所有有效短语的潜在分布的潜在变量 z。对于每个短语,c 由问题中其他短语的顺序和相应的答案组成。短语生成过程的条件分布为:P(x, z|c) = P(x|c, z) · P(z|c),学习目标则是通过神经网络优化逼近 P(z|c) 和 P(x|c, z)。令 P_θ(z|c) 作为先验网络,P_θ(x|c, z) 为目标短语解码器。目标短语 x 的生成过程为:首先从 P_θ(z|c) 抽样潜变量 z (假定为参数化高斯分布),然后通过 P_θ(x|c, z) 生成 x。
CVAE 的训练目标是,假设两个 z 都服从对角协方差矩阵的多元高斯分布,给定 c 最大化 x 的条件对数似然概率,同时最小化后验分布 P(z|x, c) 和先验分布 P(z|c) 之间的 KL 散度。此外, 引入一个识别网络 Q_φ(z | x, c) 来近似真实的后验分布 P (x, z | c)。通过最大化条件对数似然的变分下界实现 CVAE 训练:

在一个时间戳 k 的时间内,整个生成过程中产生一个问题短语,短语编码器是一种带有门控反复单元(GRU)的双向递归神经网络。通过将前向 RNN 和后向 RNN 的最后隐藏状态 (hv_k) 串联起来,将每个短语 Pk 编码成固定大小的向量。将短语文本编码器的最后一个隐藏层状态 hv^c 与对应的答案 a 串联起来生成 c=[hv^c,a]。假定 z 满足各向同性的高斯分布:
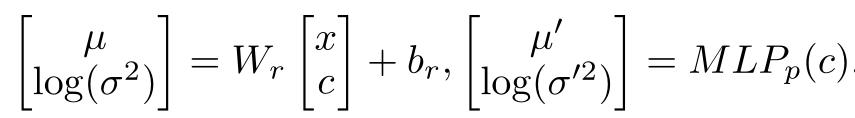
时间戳 k 的最后一个短语解码器是一个单层的 GRU 网络,初始状态设置为 W_k[z, c] + b_k。

图 8. CAVE 生成器整体结构
(2)短语增强编码器(Phrase-type Augmented Encoder)
短语包含两层特征:作为周围或上下文短语类型信息的全局特征,以及,每个短语中的实体类型知识的局部特征。由于直接从专家处获取已标记的医学数据非常困难,本文建议直接使用结构化实体词典并对短语类型进行建模。在预训练任务中,采用了一个 Bi-LSTM-CRF 模型,该模型以每个词在问题中的嵌入作为输入,词的类型作为输出。使用 Bi-LSTM 层来编码单词级的局部特征,使用 CRF 层来捕获句子级的类型信息。
每个单词 k 的 Bi-LSTM 隐藏层状态 h_k 可以通过上下文类型信息进行编码。考虑到每个短语都可以被分成多个单词,通过在每个单词的 h_k 上执行最大池化操作来引入短语类型信息。将时间戳 k 的上下文类型信息 t_k 与隐藏层状态级联后生成短语特征向量 hv_k。
(3)实体引导的解码器(Entity-guided Decoder)
在解码过程中,除了对相应的答案进行调节外,本文还对潜在 z 引入了额外的约束。本文提出了一种将短语层间信息和短语层内信息作为约束条件的多步解码方法。首先,对实体字典在第一次遍历时的上下文类型 t 进行建模,以确保跨短语的类型信息的一致性。然后,第二遍显式建模实体 e。通过在推理过程中添加实体级别的变化来促进生成过程的多样性,从而允许生成对相同答案具有相似语义但包含不同实体的短语。
我们假设短语 Pk 的生成取决于 c、z、t 和 e,其中 e 依赖于 c、z、t,t 依赖于 c、z。在训练过程中,最后一个解码器的初始状态为 d_k= W_k[z, c, t, e] + b_k,输入为 [w, t, e_k],其中 w 为 x 中单词的词嵌入,e_k 为 x 中完整实体嵌入的平均池化嵌入。在第一个类型预测阶段,基于 z 和 c 预测 t』:t『』= M LP_t(z, c)。在第二个实体预测阶段,基于 z、c、t,预测 e_softmax』 = M LP_e(z, c, t)。最后,e_softmax』与整个实体嵌入矩阵相乘,生成 e』_k 的聚合。在测试阶段,t』和 e』_k 用语最终的短语解码。
(4)训练目标函数
通过引入第一阶段训练的短语类型信息,没有实体建模的 eg-CVAE 的修正变分下界为:

为了在第二阶段训练中将短语类型信息细化为详细的实体,在假设 x 的生成分为两个阶段的基础上对 e 进行显式建模:利用短语类型生成 e;利用 e、t、c、z 生成 x,最终的 eg-CVAE 模型优化目标函数为:
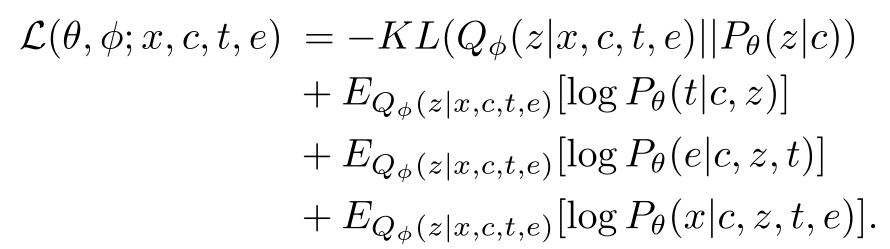
为了验证所提方法的有效性,本文在实验过程中收集了来自中国国家医疗执业资格考试 (NMLEC_QA) 的真实医学 QA 对。收集到的 NMLEC_QA 数据集包含 18,798 个 QA 对,作者根据这些原始的 QA 对生成新的 QA 对。使用 NMLEC 2017 作为评估 QA 系统的测试集,而不用于生成 QA 对。医学实体字典是从医学维基百科页面中提取出来的,构建的字典涵盖了 19 种类型的医学实体。非结构化医学教材由 2130128 篇医学领域发表的论文和 518 本专业医学教材组成。
作者在实验中选择 HRED(多级 RNN 编码器的序列到序列模型)[9] 和 VHRED(多级条件 VAE 模型)[10] 作为基线对比算法。自动评估指标下的性能比较见表 9。其中,BLEU 是一种常用的度量方法,用长度惩罚来度量修改后的 n-gram 精度的几何平均值;BOW Embedding 通过对短语中所有单词的平均、极端或贪婪策略来匹配短语嵌入的度量方式;Distinct:计算生成短语的多样性的度量,进一步将 intra-dist 定义为每个抽样短语中不同值的平均值,inter-dist 定义为所有抽样短语中不同值的平均值。

表 9. 不同方法的评估指标
在表 9 中,BLEU 和 BOW 度量的主要目的是检验结果的相似性。eg-CVAE 的设计目的是为了促进语义的多样性,因此语义相似度得分不是很高。基于 CVAE 的 VHRED 不涉及对 z 的潜在分布的任何约束,HRED 对解码过程进行了明确的建模,而没有对隐藏上下文进行进一步的操作,因此它们的语义相似度得分属于中等。本文提出的 type-CVAE 考虑了先验类型信息,entity-CVAE 则考虑了实体显示信息,这些约束有助于模型生成更多与原始 QA 对相似的 QA 对。另一方面,从多样性的角度来看,eg-CVAE 在不同的度量上得分最高。这是因为 eg-CVAE 基于潜在的答案条件分布,而不是一个确定的解码过程来分层生成新的问题。
本文还利用 NMLEC_QA 数据集中 10% 的样本进行人工评估。三位专家 (真正的医生) 被要求从三个角度来评估每一对 QA: 1) 一致性:生成的 QA 与原始的 QA 有多一致?2) 提供信息:生成的 QA 提供了多少信息?3)流利:生成的问题的短语有多流利? 每个问题都用 1(最差) 到 5(最好) 的分数进行评估。平均结果如表 10 所示。

表 10. 人工评价结果
表 10 中的结果表明,本文提出的方法效果优于 HRED 和 VHRED。通过对类型层次和实体层次的建模能够有效捕获关键信息,同时来自这两层建模的先验信息也保证了本文的模型产生信息丰富和流畅的问题的良好能力。
为了进一步研究生成的 QA 对的有效性,作者将这些生成的 QA 对集成到一个问答系统中,该系统是一个针对 NMLEC_QA 数据库的基于注意力机制的模型 [11]。结果如表 11 所示。本文提出的 eg-CVAE 方法结合了 entity-CVAE 和 type-CVAE 的优点,构建了一个三阶段解码流程,从而改进了 QA 系统,达到了最高的准确率。这些观察结果进一步证明了 eg-CVAE 生成的 QA 对的有效性。

表 11. 生成的 QA 对的有效性
小结:由于外部知识的需求和高质量培训数据的不足,在医学领域等现实场景中应用问答系统仍然具有挑战性。针对这些挑战,本文研究了生成医学 QA 对的任务。基于每个医学问题都可以看作是给定答案的潜在分布样本的观点,本文提出了一个自动的医学 QA 对生成框架,该框架由一个无监督的关键短语检测器组成,该检测器探索非结构化材料的有效性,以及包含多通解码器以整合结构知识以实现多样性的产生器。
总结
在本篇提前看中,我们选取了 AAAI2020 的三篇关于问答系统的文章进行分析。问答系统近年来广泛应用于很多实际场景,包括手机厂商的语音助手(Siri、Alexa、Bixby...)、APP 的各类问答应用(度秘、玩秘...)以及医学和教育学等专业领域的虚拟客服等。从 AAAI 2020 的录用论文也可以看出,在接受的 1591 篇文章中,专门研究问答系统的文章超过了 40 篇。
目前,神经网络仍然是问答系统所主要采用的方法,在本文的三篇文章中,第一篇使用序列-序列模型,第二篇使用 BERT,而第三篇文章为了验证提取的 QA 对的有效性,使用了基于注意力机制的模型。为了改进问答系统的效果,目前一些方法的主要目的仍然是基于训练库提取更多有效的信息,一方面可以改进训练库(第二篇文章使用了通用数据库+专门目标域数据库的方式),另一方面尝试提取全局信息、上下文信息等复杂的语义信息(第一篇文章提出的句子级语义匹配、答案位置推断的方法)。此外,针对专门的应用领域,需要结合单词、句子和文本的特征进行具体的分析和处理。
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=269


Best Last Month
CoCa: Contrastive Captioners are Image-Text Foundation Models